 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Jun 05, 2025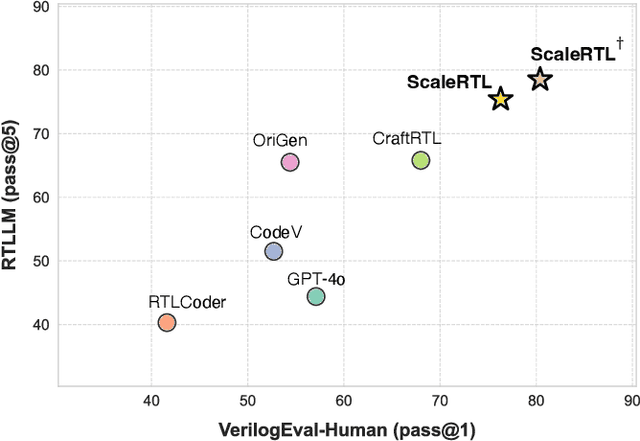
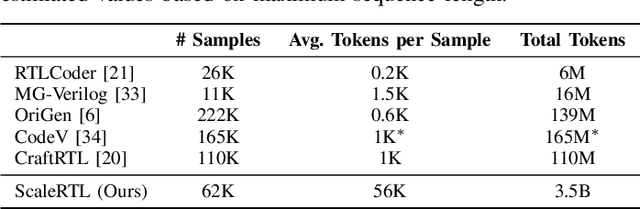
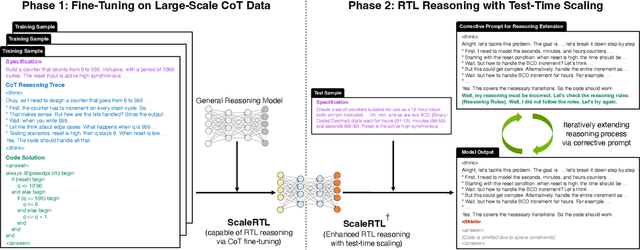
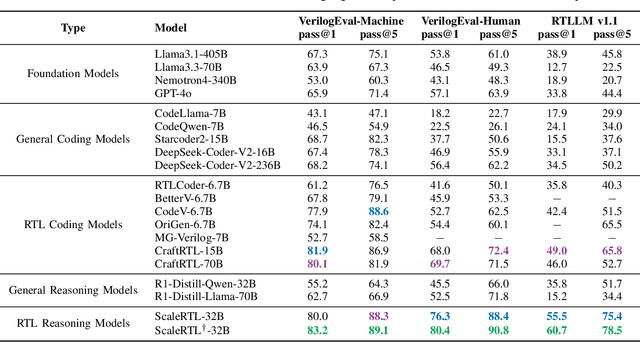
Recent advances in large language models (LLMs) have enabled near-human performance on software coding benchmarks, but their effectiveness in RTL code generation remains limited due to the scarcity of high-quality training data. While prior efforts have fine-tuned LLMs for RTL tasks, they do not fundamentally overcome the data bottleneck and lack support for test-time scaling due to their non-reasoning nature. In this work, we introduce ScaleRTL, the first reasoning LLM for RTL coding that scales up both high-quality reasoning data and test-time compute. Specifically, we curate a diverse set of long chain-of-thought reasoning traces averaging 56K tokens each, resulting in a dataset of 3.5B tokens that captures rich RTL knowledge. Fine-tuning a general-purpose reasoning model on this corpus yields ScaleRTL that is capable of deep RTL reasoning. Subsequently, we further enhance the performance of ScaleRTL through a novel test-time scaling strategy that extends the reasoning process via iteratively reflecting on and self-correcting previous reasoning steps. Experimental results show that ScaleRTL achieves state-of-the-art performance on VerilogEval and RTLLM, outperforming 18 competitive baselines by up to 18.4% on VerilogEval and 12.7% on RTLLM.
Uncertainty Profiles for LLMs: Uncertainty Source Decomposition and Adaptive Model-Metric Selection
May 12, 2025Large language models (LLMs) often generate fluent but factually incorrect outputs, known as hallucinations, which undermine their reliability in real-world applications. While uncertainty estimation has emerged as a promising strategy for detecting such errors, current metrics offer limited interpretability and lack clarity about the types of uncertainty they capture. In this paper, we present a systematic framework for decomposing LLM uncertainty into four distinct sources, inspired by previous research. We develop a source-specific estimation pipeline to quantify these uncertainty types and evaluate how existing metrics relate to each source across tasks and models. Our results show that metrics, task, and model exhibit systematic variation in uncertainty characteristic. Building on this, we propose a method for task specific metric/model selection guided by the alignment or divergence between their uncertainty characteristics and that of a given task. Our experiments across datasets and models demonstrate that our uncertainty-aware selection strategy consistently outperforms baseline strategies, helping us select appropriate models or uncertainty metrics, and contributing to more reliable and efficient deployment in uncertainty estimation.
Benchmarking Large Language Model Uncertainty for Prompt Optimization
Sep 16, 2024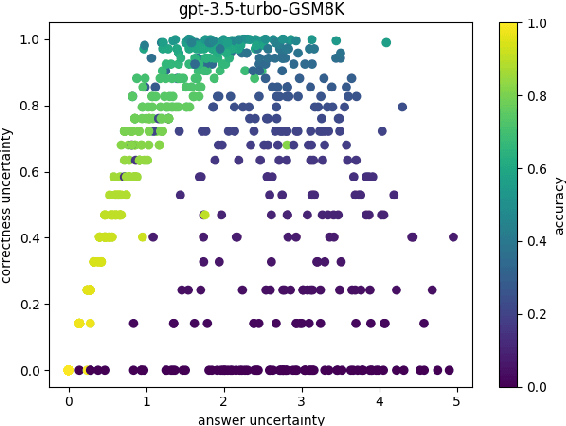
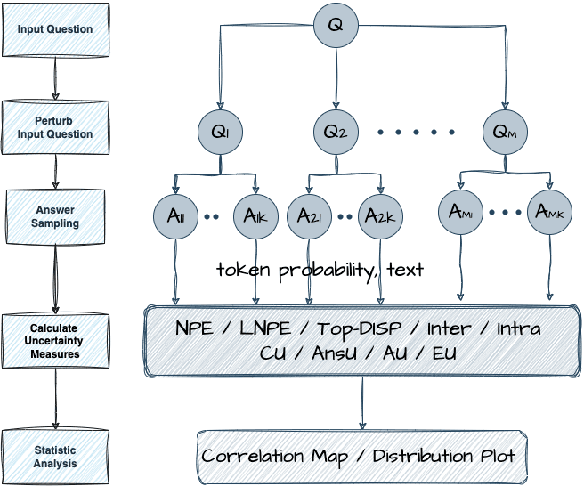
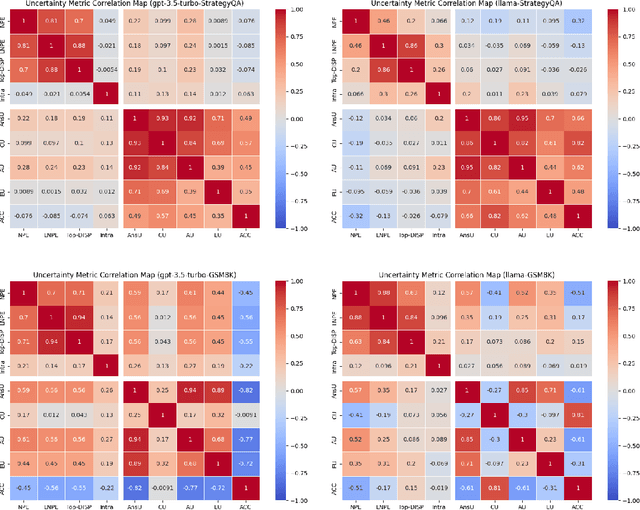
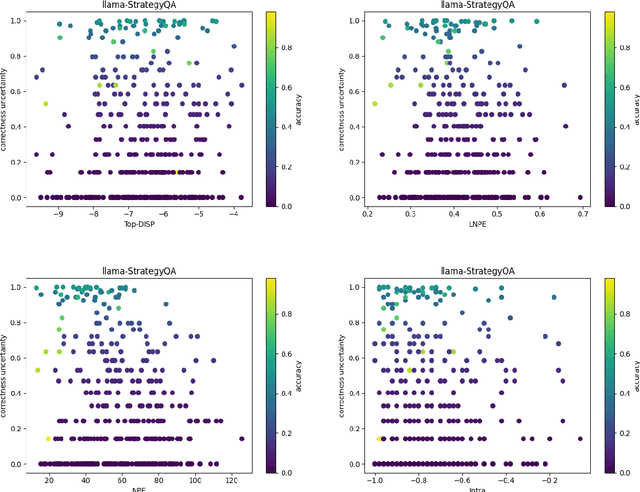
Prompt optimization algorithms for Large Language Models (LLMs) excel in multi-step reasoning but still lack effective uncertainty estimation. This paper introduces a benchmark dataset to evaluate uncertainty metrics, focusing on Answer, Correctness, Aleatoric, and Epistemic Uncertainty. Through analysis of models like GPT-3.5-Turbo and Meta-Llama-3.1-8B-Instruct, we show that current metrics align more with Answer Uncertainty, which reflects output confidence and diversity, rather than Correctness Uncertainty, highlighting the need for improved metrics that are optimization-objective-aware to better guide prompt optimization. Our code and dataset are available at https://github.com/0Frett/PO-Uncertainty-Benchmarking.
Enhance Modality Robustness in Text-Centric Multimodal Alignment with Adversarial Prompting
Aug 19, 2024Converting different modalities into generalized text, which then serves as input prompts for large language models (LLMs), is a common approach for aligning multimodal models, particularly when pairwise data is limited. Text-centric alignment method leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation, thereby enabling downstream models to effectively interpret various modal inputs. This study evaluates the quality and robustness of multimodal representations in the face of noise imperfections, dynamic input order permutations, and missing modalities, revealing that current text-centric alignment methods can compromise downstream robustness. To address this issue, we propose a new text-centric adversarial training approach that significantly enhances robustness compared to traditional robust training methods and pre-trained multimodal foundation models. Our findings underscore the potential of this approach to improve the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Code Less, Align More: Efficient LLM Fine-tuning for Code Generation with Data Pruning
Jul 06, 2024



Recent work targeting large language models (LLMs) for code generation demonstrated that increasing the amount of training data through synthetic code generation often leads to exceptional performance. In this paper we explore data pruning methods aimed at enhancing the efficiency of model training specifically for code LLMs. We present techniques that integrate various clustering and pruning metrics to selectively reduce training data without compromising the accuracy and functionality of the generated code. We observe significant redundancies in synthetic training data generation, where our experiments demonstrate that benchmark performance can be largely preserved by training on only 10% of the data. Moreover, we observe consistent improvements in benchmark results through moderate pruning of the training data. Our experiments show that these pruning strategies not only reduce the computational resources needed but also enhance the overall quality code generation.
Enhance the Robustness of Text-Centric Multimodal Alignments
Jul 06, 2024Converting different modalities into general text, serving as input prompts for large language models (LLMs), is a common method to align multimodal models when there is limited pairwise data. This text-centric approach leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation. This enables downstream models to effectively interpret various modal inputs. This study assesses the quality and robustness of multimodal representations in the presence of missing entries, noise, or absent modalities, revealing that current text-centric alignment methods compromise downstream robustness. To address this issue, we propose a new text-centric approach that achieves superior robustness compared to previous methods across various modalities in different settings. Our findings highlight the potential of this approach to enhance the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
LinearAPT: An Adaptive Algorithm for the Fixed-Budget Thresholding Linear Bandit Problem
Mar 10, 2024



In this study, we delve into the Thresholding Linear Bandit (TLB) problem, a nuanced domain within stochastic Multi-Armed Bandit (MAB) problems, focusing on maximizing decision accuracy against a linearly defined threshold under resource constraints. We present LinearAPT, a novel algorithm designed for the fixed budget setting of TLB, providing an efficient solution to optimize sequential decision-making. This algorithm not only offers a theoretical upper bound for estimated loss but also showcases robust performance on both synthetic and real-world datasets. Our contributions highlight the adaptability, simplicity, and computational efficiency of LinearAPT, making it a valuable addition to the toolkit for addressing complex sequential decision-making challenges.
Text-centric Alignment for Multi-Modality Learning
Feb 12, 2024



This research paper addresses the challenge of modality mismatch in multimodal learning, where the modalities available during inference differ from those available at training. We propose the Text-centric Alignment for Multi-Modality Learning (TAMML) approach, an innovative method that utilizes Large Language Models (LLMs) with in-context learning and foundation models to enhance the generalizability of multimodal systems under these conditions. By leveraging the unique properties of text as a unified semantic space, TAMML demonstrates significant improvements in handling unseen, diverse, and unpredictable modality combinations. TAMML not only adapts to varying modalities but also maintains robust performance, showcasing the potential of foundation models in overcoming the limitations of traditional fixed-modality frameworks in embedding representations. This study contributes to the field by offering a flexible, effective solution for real-world applications where modality availability is dynamic and uncertain.
lil'HDoC: An Algorithm for Good Arm Identification under Small Threshold Gap
Feb 07, 2024



Good arm identification (GAI) is a pure-exploration bandit problem in which a single learner outputs an arm as soon as it is identified as a good arm. A good arm is defined as an arm with an expected reward greater than or equal to a given threshold. This paper focuses on the GAI problem under a small threshold gap, which refers to the distance between the expected rewards of arms and the given threshold. We propose a new algorithm called lil'HDoC to significantly improve the total sample complexity of the HDoC algorithm. We demonstrate that the sample complexity of the first $\lambda$ output arm in lil'HDoC is bounded by the original HDoC algorithm, except for one negligible term, when the distance between the expected reward and threshold is small. Extensive experiments confirm that our algorithm outperforms the state-of-the-art algorithms in both synthetic and real-world datasets.
PSGText: Stroke-Guided Scene Text Editing with PSP Module
Oct 20, 2023



Scene Text Editing (STE) aims to substitute text in an image with new desired text while preserving the background and styles of the original text. However, present techniques present a notable challenge in the generation of edited text images that exhibit a high degree of clarity and legibility. This challenge primarily stems from the inherent diversity found within various text types and the intricate textures of complex backgrounds. To address this challenge, this paper introduces a three-stage framework for transferring texts across text images. Initially, we introduce a text-swapping network that seamlessly substitutes the original text with the desired replacement. Subsequently, we incorporate a background inpainting network into our framework. This specialized network is designed to skillfully reconstruct background images, effectively addressing the voids left after the removal of the original text. This process meticulously preserves visual harmony and coherence in the background. Ultimately, the synthesis of outcomes from the text-swapping network and the background inpainting network is achieved through a fusion network, culminating in the creation of the meticulously edited final image. A demo video is included in the supplementary material.