 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink or Remember? Detecting and Directing LLMs Towards Memorization or Generalization
Dec 24, 2024


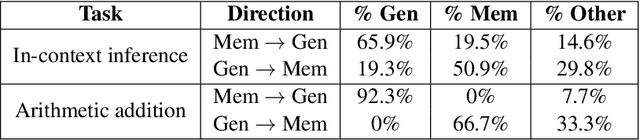
In this paper, we explore the foundational mechanisms of memorization and generalization in Large Language Models (LLMs), inspired by the functional specialization observed in the human brain. Our investigation serves as a case study leveraging specially designed datasets and experimental-scale LLMs to lay the groundwork for understanding these behaviors. Specifically, we aim to first enable LLMs to exhibit both memorization and generalization by training with the designed dataset, then (a) examine whether LLMs exhibit neuron-level spatial differentiation for memorization and generalization, (b) predict these behaviors using model internal representations, and (c) steer the behaviors through inference-time interventions. Our findings reveal that neuron-wise differentiation of memorization and generalization is observable in LLMs, and targeted interventions can successfully direct their behavior.
Enhance Modality Robustness in Text-Centric Multimodal Alignment with Adversarial Prompting
Aug 19, 2024Converting different modalities into generalized text, which then serves as input prompts for large language models (LLMs), is a common approach for aligning multimodal models, particularly when pairwise data is limited. Text-centric alignment method leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation, thereby enabling downstream models to effectively interpret various modal inputs. This study evaluates the quality and robustness of multimodal representations in the face of noise imperfections, dynamic input order permutations, and missing modalities, revealing that current text-centric alignment methods can compromise downstream robustness. To address this issue, we propose a new text-centric adversarial training approach that significantly enhances robustness compared to traditional robust training methods and pre-trained multimodal foundation models. Our findings underscore the potential of this approach to improve the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Enhance the Robustness of Text-Centric Multimodal Alignments
Jul 06, 2024Converting different modalities into general text, serving as input prompts for large language models (LLMs), is a common method to align multimodal models when there is limited pairwise data. This text-centric approach leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation. This enables downstream models to effectively interpret various modal inputs. This study assesses the quality and robustness of multimodal representations in the presence of missing entries, noise, or absent modalities, revealing that current text-centric alignment methods compromise downstream robustness. To address this issue, we propose a new text-centric approach that achieves superior robustness compared to previous methods across various modalities in different settings. Our findings highlight the potential of this approach to enhance the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Environment Diversification with Multi-head Neural Network for Invariant Learning
Aug 17, 2023
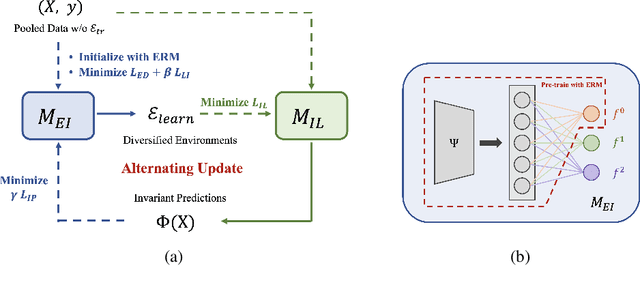
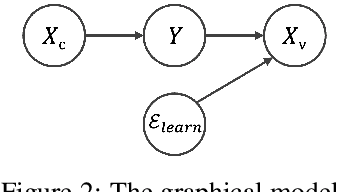

Neural networks are often trained with empirical risk minimization; however, it has been shown that a shift between training and testing distributions can cause unpredictable performance degradation. On this issue, a research direction, invariant learning, has been proposed to extract invariant features insensitive to the distributional changes. This work proposes EDNIL, an invariant learning framework containing a multi-head neural network to absorb data biases. We show that this framework does not require prior knowledge about environments or strong assumptions about the pre-trained model. We also reveal that the proposed algorithm has theoretical connections to recent studies discussing properties of variant and invariant features. Finally, we demonstrate that models trained with EDNIL are empirically more robust against distributional shifts.