 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Instruction Tuning Large Language Models on Graphs
Aug 10, 2024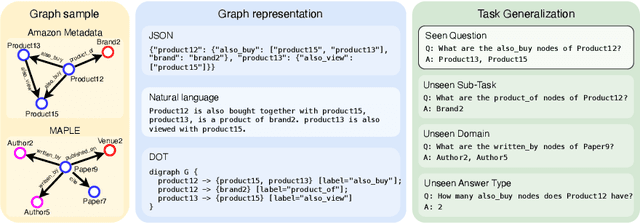
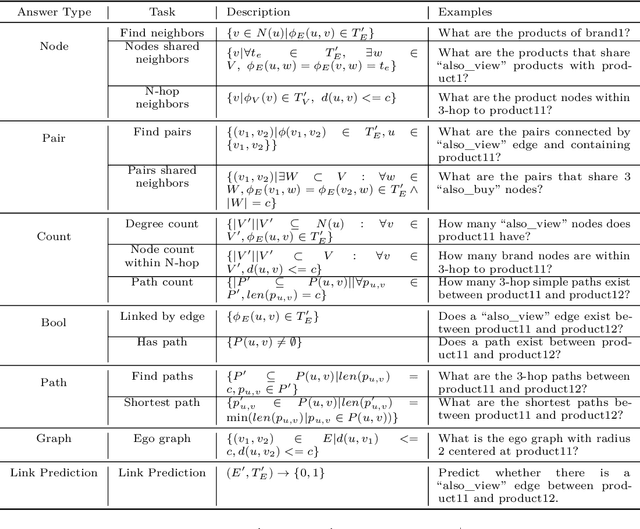

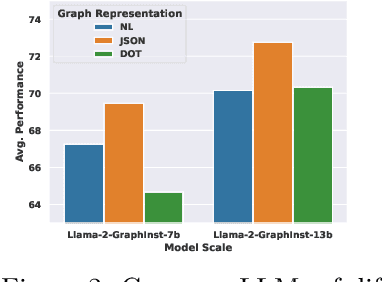
Inspired by the recent advancements of Large Language Models (LLMs) in NLP tasks, there's growing interest in applying LLMs to graph-related tasks. This study delves into the capabilities of instruction-following LLMs for engaging with real-world graphs, aiming to offer empirical insights into how LLMs can effectively interact with graphs and generalize across graph tasks. We begin by constructing a dataset designed for instruction tuning, which comprises a diverse collection of 79 graph-related tasks from academic and e-commerce domains, featuring 44,240 training instances and 18,960 test samples. Utilizing this benchmark, our initial investigation focuses on identifying the optimal graph representation that serves as a conduit for LLMs to understand complex graph structures. Our findings indicate that JSON format for graph representation consistently outperforms natural language and code formats across various LLMs and graph types. Furthermore, we examine the key factors that influence the generalization abilities of instruction-tuned LLMs by evaluating their performance on both in-domain and out-of-domain graph tasks.
AutoML-GPT: Large Language Model for AutoML
Sep 03, 2023

With the emerging trend of GPT models, we have established a framework called AutoML-GPT that integrates a comprehensive set of tools and libraries. This framework grants users access to a wide range of data preprocessing techniques, feature engineering methods, and model selection algorithms. Through a conversational interface, users can specify their requirements, constraints, and evaluation metrics. Throughout the process, AutoML-GPT employs advanced techniques for hyperparameter optimization and model selection, ensuring that the resulting model achieves optimal performance. The system effectively manages the complexity of the machine learning pipeline, guiding users towards the best choices without requiring deep domain knowledge. Through our experimental results on diverse datasets, we have demonstrated that AutoML-GPT significantly reduces the time and effort required for machine learning tasks. Its ability to leverage the vast knowledge encoded in large language models enables it to provide valuable insights, identify potential pitfalls, and suggest effective solutions to common challenges faced during model training.
Environment Diversification with Multi-head Neural Network for Invariant Learning
Aug 17, 2023
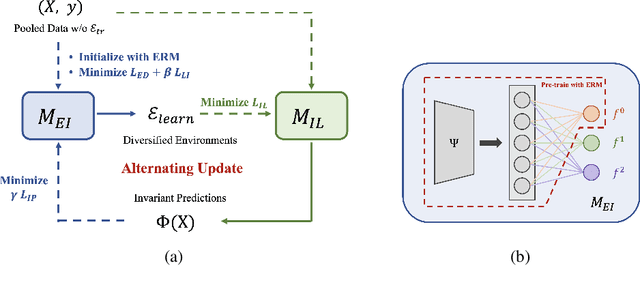
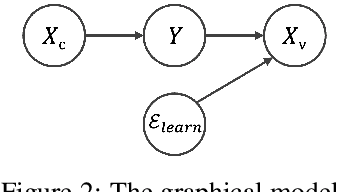

Neural networks are often trained with empirical risk minimization; however, it has been shown that a shift between training and testing distributions can cause unpredictable performance degradation. On this issue, a research direction, invariant learning, has been proposed to extract invariant features insensitive to the distributional changes. This work proposes EDNIL, an invariant learning framework containing a multi-head neural network to absorb data biases. We show that this framework does not require prior knowledge about environments or strong assumptions about the pre-trained model. We also reveal that the proposed algorithm has theoretical connections to recent studies discussing properties of variant and invariant features. Finally, we demonstrate that models trained with EDNIL are empirically more robust against distributional shifts.