 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Aware Privacy Mechanisms for Defending Embedding Inversion Attacks
Feb 06, 2026Text embeddings enable numerous NLP applications but face severe privacy risks from embedding inversion attacks, which can expose sensitive attributes or reconstruct raw text. Existing differential privacy defenses assume uniform sensitivity across embedding dimensions, leading to excessive noise and degraded utility. We propose SPARSE, a user-centric framework for concept-specific privacy protection in text embeddings. SPARSE combines (1) differentiable mask learning to identify privacy-sensitive dimensions for user-defined concepts, and (2) the Mahalanobis mechanism that applies elliptical noise calibrated by dimension sensitivity. Unlike traditional spherical noise injection, SPARSE selectively perturbs privacy-sensitive dimensions while preserving non-sensitive semantics. Evaluated across six datasets with three embedding models and attack scenarios, SPARSE consistently reduces privacy leakage while achieving superior downstream performance compared to state-of-the-art DP methods.
Graph Neural Networks for Tabular Data Learning: A Survey with Taxonomy and Directions
Jan 04, 2024



In this survey, we dive into Tabular Data Learning (TDL) using Graph Neural Networks (GNNs), a domain where deep learning-based approaches have increasingly shown superior performance in both classification and regression tasks compared to traditional methods. The survey highlights a critical gap in deep neural TDL methods: the underrepresentation of latent correlations among data instances and feature values. GNNs, with their innate capability to model intricate relationships and interactions between diverse elements of tabular data, have garnered significant interest and application across various TDL domains. Our survey provides a systematic review of the methods involved in designing and implementing GNNs for TDL (GNN4TDL). It encompasses a detailed investigation into the foundational aspects and an overview of GNN-based TDL methods, offering insights into their evolving landscape. We present a comprehensive taxonomy focused on constructing graph structures and representation learning within GNN-based TDL methods. In addition, the survey examines various training plans, emphasizing the integration of auxiliary tasks to enhance the effectiveness of instance representations. A critical part of our discussion is dedicated to the practical application of GNNs across a spectrum of GNN4TDL scenarios, demonstrating their versatility and impact. Lastly, we discuss the limitations and propose future research directions, aiming to spur advancements in GNN4TDL. This survey serves as a resource for researchers and practitioners, offering a thorough understanding of GNNs' role in revolutionizing TDL and pointing towards future innovations in this promising area.
AutoML-GPT: Large Language Model for AutoML
Sep 03, 2023

With the emerging trend of GPT models, we have established a framework called AutoML-GPT that integrates a comprehensive set of tools and libraries. This framework grants users access to a wide range of data preprocessing techniques, feature engineering methods, and model selection algorithms. Through a conversational interface, users can specify their requirements, constraints, and evaluation metrics. Throughout the process, AutoML-GPT employs advanced techniques for hyperparameter optimization and model selection, ensuring that the resulting model achieves optimal performance. The system effectively manages the complexity of the machine learning pipeline, guiding users towards the best choices without requiring deep domain knowledge. Through our experimental results on diverse datasets, we have demonstrated that AutoML-GPT significantly reduces the time and effort required for machine learning tasks. Its ability to leverage the vast knowledge encoded in large language models enables it to provide valuable insights, identify potential pitfalls, and suggest effective solutions to common challenges faced during model training.
GraphFC: Customs Fraud Detection with Label Scarcity
May 19, 2023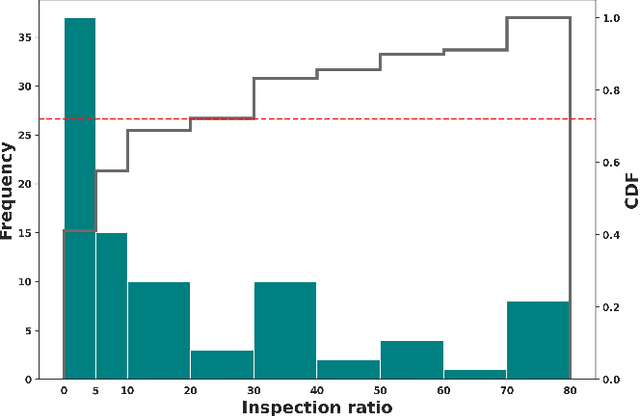



Custom officials across the world encounter huge volumes of transactions. With increased connectivity and globalization, the customs transactions continue to grow every year. Associated with customs transactions is the customs fraud - the intentional manipulation of goods declarations to avoid the taxes and duties. With limited manpower, the custom offices can only undertake manual inspection of a limited number of declarations. This necessitates the need for automating the customs fraud detection by machine learning (ML) techniques. Due the limited manual inspection for labeling the new-incoming declarations, the ML approach should have robust performance subject to the scarcity of labeled data. However, current approaches for customs fraud detection are not well suited and designed for this real-world setting. In this work, we propose $\textbf{GraphFC}$ ($\textbf{Graph}$ neural networks for $\textbf{C}$ustoms $\textbf{F}$raud), a model-agnostic, domain-specific, semi-supervised graph neural network based customs fraud detection algorithm that has strong semi-supervised and inductive capabilities. With upto 252% relative increase in recall over the present state-of-the-art, extensive experimentation on real customs data from customs administrations of three different countries demonstrate that GraphFC consistently outperforms various baselines and the present state-of-art by a large margin.
FinGAT: Financial Graph Attention Networks for Recommending Top-K Profitable Stocks
Jun 18, 2021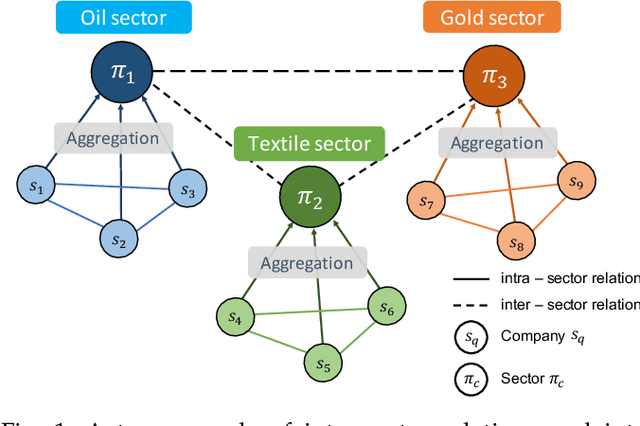

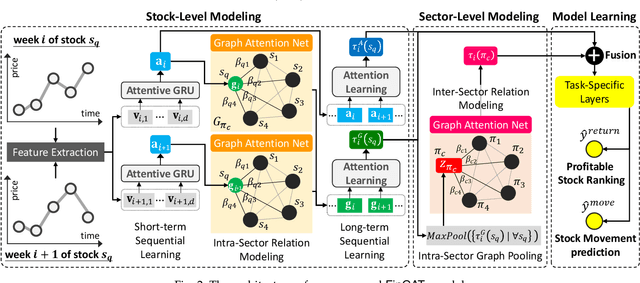
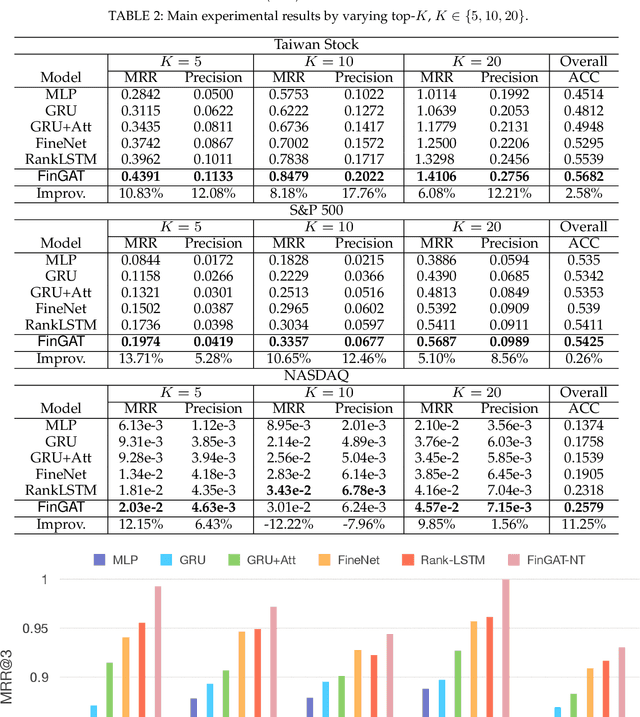
Financial technology (FinTech) has drawn much attention among investors and companies. While conventional stock analysis in FinTech targets at predicting stock prices, less effort is made for profitable stock recommendation. Besides, in existing approaches on modeling time series of stock prices, the relationships among stocks and sectors (i.e., categories of stocks) are either neglected or pre-defined. Ignoring stock relationships will miss the information shared between stocks while using pre-defined relationships cannot depict the latent interactions or influence of stock prices between stocks. In this work, we aim at recommending the top-K profitable stocks in terms of return ratio using time series of stock prices and sector information. We propose a novel deep learning-based model, Financial Graph Attention Networks (FinGAT), to tackle the task under the setting that no pre-defined relationships between stocks are given. The idea of FinGAT is three-fold. First, we devise a hierarchical learning component to learn short-term and long-term sequential patterns from stock time series. Second, a fully-connected graph between stocks and a fully-connected graph between sectors are constructed, along with graph attention networks, to learn the latent interactions among stocks and sectors. Third, a multi-task objective is devised to jointly recommend the profitable stocks and predict the stock movement. Experiments conducted on Taiwan Stock, S&P 500, and NASDAQ datasets exhibit remarkable recommendation performance of our FinGAT, comparing to state-of-the-art methods.