 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Tabular Data Learning: A Survey with Taxonomy and Directions
Jan 04, 2024



In this survey, we dive into Tabular Data Learning (TDL) using Graph Neural Networks (GNNs), a domain where deep learning-based approaches have increasingly shown superior performance in both classification and regression tasks compared to traditional methods. The survey highlights a critical gap in deep neural TDL methods: the underrepresentation of latent correlations among data instances and feature values. GNNs, with their innate capability to model intricate relationships and interactions between diverse elements of tabular data, have garnered significant interest and application across various TDL domains. Our survey provides a systematic review of the methods involved in designing and implementing GNNs for TDL (GNN4TDL). It encompasses a detailed investigation into the foundational aspects and an overview of GNN-based TDL methods, offering insights into their evolving landscape. We present a comprehensive taxonomy focused on constructing graph structures and representation learning within GNN-based TDL methods. In addition, the survey examines various training plans, emphasizing the integration of auxiliary tasks to enhance the effectiveness of instance representations. A critical part of our discussion is dedicated to the practical application of GNNs across a spectrum of GNN4TDL scenarios, demonstrating their versatility and impact. Lastly, we discuss the limitations and propose future research directions, aiming to spur advancements in GNN4TDL. This survey serves as a resource for researchers and practitioners, offering a thorough understanding of GNNs' role in revolutionizing TDL and pointing towards future innovations in this promising area.
Label-Aware Hyperbolic Embeddings for Fine-grained Emotion Classification
Jun 26, 2023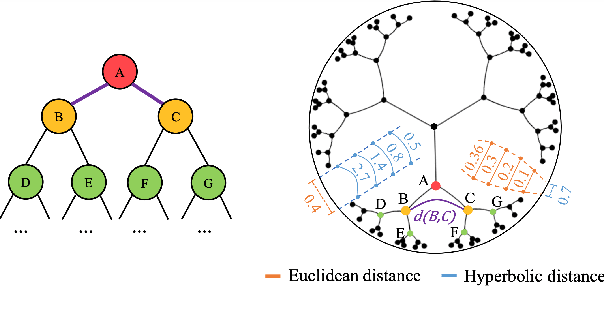
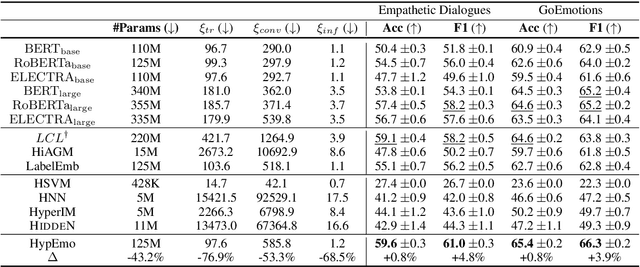
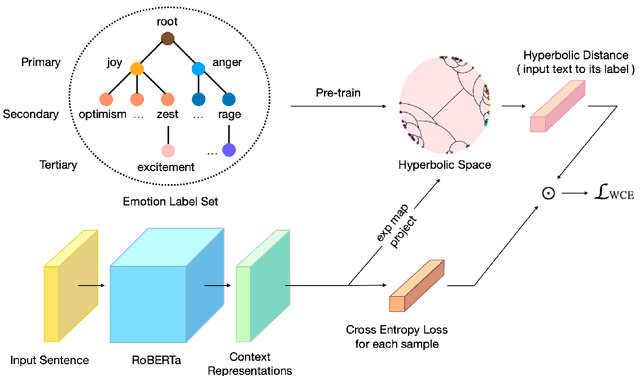
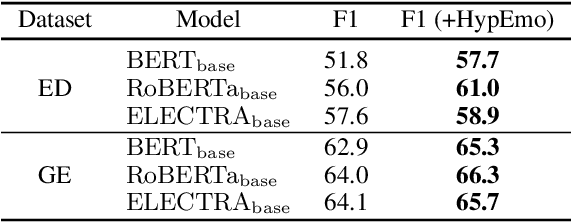
Fine-grained emotion classification (FEC) is a challenging task. Specifically, FEC needs to handle subtle nuance between labels, which can be complex and confusing. Most existing models only address text classification problem in the euclidean space, which we believe may not be the optimal solution as labels of close semantic (e.g., afraid and terrified) may not be differentiated in such space, which harms the performance. In this paper, we propose HypEmo, a novel framework that can integrate hyperbolic embeddings to improve the FEC task. First, we learn label embeddings in the hyperbolic space to better capture their hierarchical structure, and then our model projects contextualized representations to the hyperbolic space to compute the distance between samples and labels. Experimental results show that incorporating such distance to weight cross entropy loss substantially improves the performance with significantly higher efficiency. We evaluate our proposed model on two benchmark datasets and found 4.8% relative improvement compared to the previous state of the art with 43.2% fewer parameters and 76.9% less training time. Code is available at https: //github.com/dinobby/HypEmo.
HonestBait: Forward References for Attractive but Faithful Headline Generation
Jun 26, 2023Current methods for generating attractive headlines often learn directly from data, which bases attractiveness on the number of user clicks and views. Although clicks or views do reflect user interest, they can fail to reveal how much interest is raised by the writing style and how much is due to the event or topic itself. Also, such approaches can lead to harmful inventions by over-exaggerating the content, aggravating the spread of false information. In this work, we propose HonestBait, a novel framework for solving these issues from another aspect: generating headlines using forward references (FRs), a writing technique often used for clickbait. A self-verification process is included during training to avoid spurious inventions. We begin with a preliminary user study to understand how FRs affect user interest, after which we present PANCO1, an innovative dataset containing pairs of fake news with verified news for attractive but faithful news headline generation. Automatic metrics and human evaluations show that our framework yields more attractive results (+11.25% compared to human-written verified news headlines) while maintaining high veracity, which helps promote real information to fight against fake news.
SUVR: A Search-based Approach to Unsupervised Visual Representation Learning
May 24, 2023


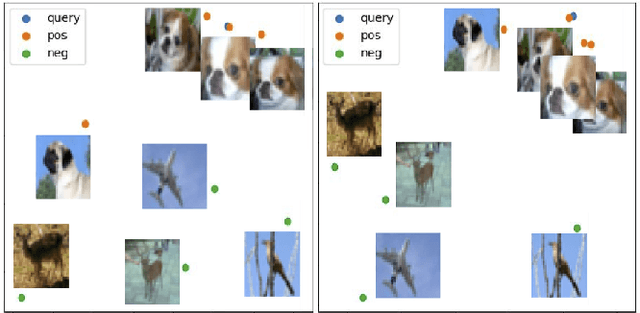
Unsupervised learning has grown in popularity because of the difficulty of collecting annotated data and the development of modern frameworks that allow us to learn from unlabeled data. Existing studies, however, either disregard variations at different levels of similarity or only consider negative samples from one batch. We argue that image pairs should have varying degrees of similarity, and the negative samples should be allowed to be drawn from the entire dataset. In this work, we propose Search-based Unsupervised Visual Representation Learning (SUVR) to learn better image representations in an unsupervised manner. We first construct a graph from the image dataset by the similarity between images, and adopt the concept of graph traversal to explore positive samples. In the meantime, we make sure that negative samples can be drawn from the full dataset. Quantitative experiments on five benchmark image classification datasets demonstrate that SUVR can significantly outperform strong competing methods on unsupervised embedding learning. Qualitative experiments also show that SUVR can produce better representations in which similar images are clustered closer together than unrelated images in the latent space.
ZS-BERT: Towards Zero-Shot Relation Extraction with Attribute Representation Learning
Apr 10, 2021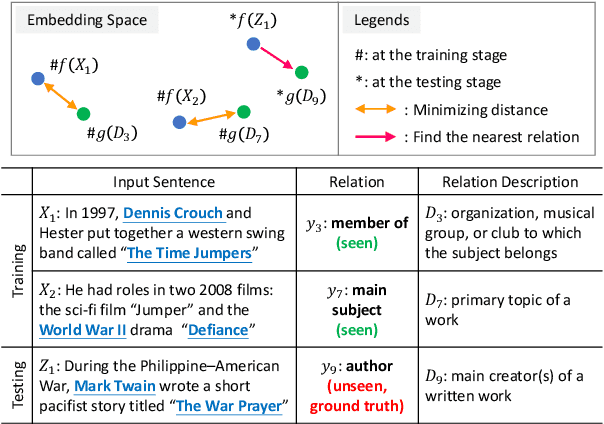


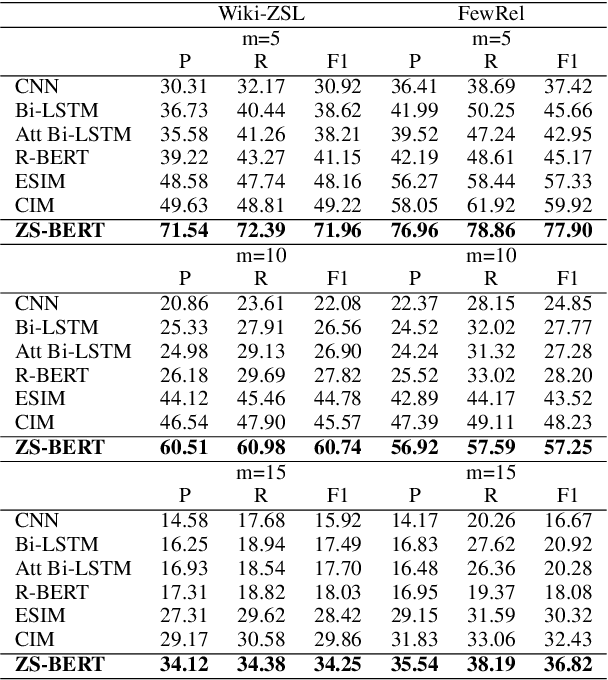
While relation extraction is an essential task in knowledge acquisition and representation, and new-generated relations are common in the real world, less effort is made to predict unseen relations that cannot be observed at the training stage. In this paper, we formulate the zero-shot relation extraction problem by incorporating the text description of seen and unseen relations. We propose a novel multi-task learning model, zero-shot BERT (ZS-BERT), to directly predict unseen relations without hand-crafted attribute labeling and multiple pairwise classifications. Given training instances consisting of input sentences and the descriptions of their relations, ZS-BERT learns two functions that project sentences and relation descriptions into an embedding space by jointly minimizing the distances between them and classifying seen relations. By generating the embeddings of unseen relations and new-coming sentences based on such two functions, we use nearest neighbor search to obtain the prediction of unseen relations. Experiments conducted on two well-known datasets exhibit that ZS-BERT can outperform existing methods by at least 13.54\% improvement on F1 score.