 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialNLP Fake-EmoReact 2021 Challenge Overview: Predicting Fake Tweets from Their Replies and GIFs
May 31, 2024

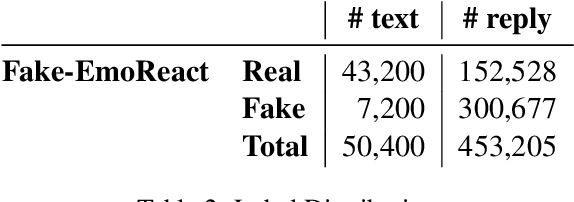

This paper provides an overview of the Fake-EmoReact 2021 Challenge, held at the 9th SocialNLP Workshop, in conjunction with NAACL 2021. The challenge requires predicting the authenticity of tweets using reply context and augmented GIF categories from EmotionGIF dataset. We offer the Fake-EmoReact dataset with more than 453k as the experimental materials, where every tweet is labeled with authenticity. Twenty-four teams registered to participate in this challenge, and 5 submitted their results successfully in the evaluation phase. The best team achieves 93.9 on Fake-EmoReact 2021 dataset using F1 score. In addition, we show the definition of share task, data collection, and the teams' performance that joined this challenge and their approaches.
Graph Neural Networks for Tabular Data Learning: A Survey with Taxonomy and Directions
Jan 04, 2024



In this survey, we dive into Tabular Data Learning (TDL) using Graph Neural Networks (GNNs), a domain where deep learning-based approaches have increasingly shown superior performance in both classification and regression tasks compared to traditional methods. The survey highlights a critical gap in deep neural TDL methods: the underrepresentation of latent correlations among data instances and feature values. GNNs, with their innate capability to model intricate relationships and interactions between diverse elements of tabular data, have garnered significant interest and application across various TDL domains. Our survey provides a systematic review of the methods involved in designing and implementing GNNs for TDL (GNN4TDL). It encompasses a detailed investigation into the foundational aspects and an overview of GNN-based TDL methods, offering insights into their evolving landscape. We present a comprehensive taxonomy focused on constructing graph structures and representation learning within GNN-based TDL methods. In addition, the survey examines various training plans, emphasizing the integration of auxiliary tasks to enhance the effectiveness of instance representations. A critical part of our discussion is dedicated to the practical application of GNNs across a spectrum of GNN4TDL scenarios, demonstrating their versatility and impact. Lastly, we discuss the limitations and propose future research directions, aiming to spur advancements in GNN4TDL. This survey serves as a resource for researchers and practitioners, offering a thorough understanding of GNNs' role in revolutionizing TDL and pointing towards future innovations in this promising area.
DDNAS: Discretized Differentiable Neural Architecture Search for Text Classification
Jul 12, 2023



Neural Architecture Search (NAS) has shown promising capability in learning text representation. However, existing text-based NAS neither performs a learnable fusion of neural operations to optimize the architecture, nor encodes the latent hierarchical categorization behind text input. This paper presents a novel NAS method, Discretized Differentiable Neural Architecture Search (DDNAS), for text representation learning and classification. With the continuous relaxation of architecture representation, DDNAS can use gradient descent to optimize the search. We also propose a novel discretization layer via mutual information maximization, which is imposed on every search node to model the latent hierarchical categorization in text representation. Extensive experiments conducted on eight diverse real datasets exhibit that DDNAS can consistently outperform the state-of-the-art NAS methods. While DDNAS relies on only three basic operations, i.e., convolution, pooling, and none, to be the candidates of NAS building blocks, its promising performance is noticeable and extensible to obtain further improvement by adding more different operations.
TabGSL: Graph Structure Learning for Tabular Data Prediction
May 25, 2023


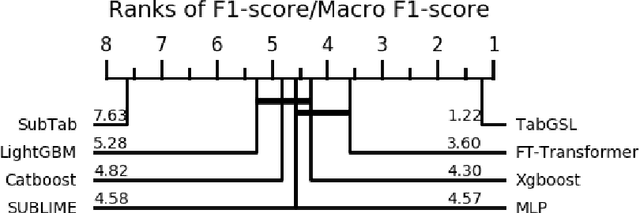
This work presents a novel approach to tabular data prediction leveraging graph structure learning and graph neural networks. Despite the prevalence of tabular data in real-world applications, traditional deep learning methods often overlook the potentially valuable associations between data instances. Such associations can offer beneficial insights for classification tasks, as instances may exhibit similar patterns of correlations among features and target labels. This information can be exploited by graph neural networks, necessitating robust graph structures. However, existing studies primarily focus on improving graph structure from noisy data, largely neglecting the possibility of deriving graph structures from tabular data. We present a novel solution, Tabular Graph Structure Learning (TabGSL), to enhance tabular data prediction by simultaneously learning instance correlation and feature interaction within a unified framework. This is achieved through a proposed graph contrastive learning module, along with transformer-based feature extractor and graph neural network. Comprehensive experiments conducted on 30 benchmark tabular datasets demonstrate that TabGSL markedly outperforms both tree-based models and recent deep learning-based tabular models. Visualizations of the learned instance embeddings further substantiate the effectiveness of TabGSL.
SUVR: A Search-based Approach to Unsupervised Visual Representation Learning
May 24, 2023


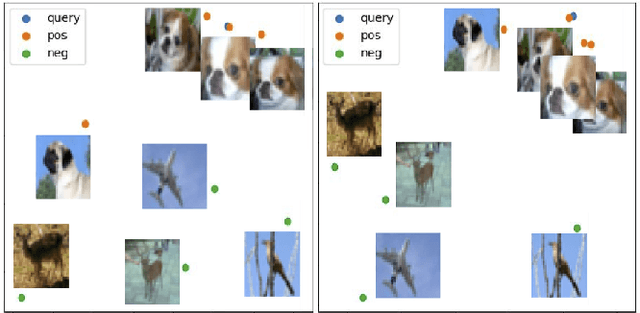
Unsupervised learning has grown in popularity because of the difficulty of collecting annotated data and the development of modern frameworks that allow us to learn from unlabeled data. Existing studies, however, either disregard variations at different levels of similarity or only consider negative samples from one batch. We argue that image pairs should have varying degrees of similarity, and the negative samples should be allowed to be drawn from the entire dataset. In this work, we propose Search-based Unsupervised Visual Representation Learning (SUVR) to learn better image representations in an unsupervised manner. We first construct a graph from the image dataset by the similarity between images, and adopt the concept of graph traversal to explore positive samples. In the meantime, we make sure that negative samples can be drawn from the full dataset. Quantitative experiments on five benchmark image classification datasets demonstrate that SUVR can significantly outperform strong competing methods on unsupervised embedding learning. Qualitative experiments also show that SUVR can produce better representations in which similar images are clustered closer together than unrelated images in the latent space.
GraphFC: Customs Fraud Detection with Label Scarcity
May 19, 2023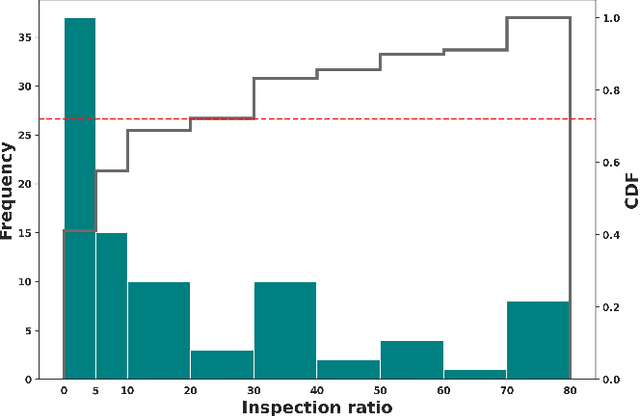



Custom officials across the world encounter huge volumes of transactions. With increased connectivity and globalization, the customs transactions continue to grow every year. Associated with customs transactions is the customs fraud - the intentional manipulation of goods declarations to avoid the taxes and duties. With limited manpower, the custom offices can only undertake manual inspection of a limited number of declarations. This necessitates the need for automating the customs fraud detection by machine learning (ML) techniques. Due the limited manual inspection for labeling the new-incoming declarations, the ML approach should have robust performance subject to the scarcity of labeled data. However, current approaches for customs fraud detection are not well suited and designed for this real-world setting. In this work, we propose $\textbf{GraphFC}$ ($\textbf{Graph}$ neural networks for $\textbf{C}$ustoms $\textbf{F}$raud), a model-agnostic, domain-specific, semi-supervised graph neural network based customs fraud detection algorithm that has strong semi-supervised and inductive capabilities. With upto 252% relative increase in recall over the present state-of-the-art, extensive experimentation on real customs data from customs administrations of three different countries demonstrate that GraphFC consistently outperforms various baselines and the present state-of-art by a large margin.
FairSR: Fairness-aware Sequential Recommendation through Multi-Task Learning with Preference Graph Embeddings
Apr 30, 2022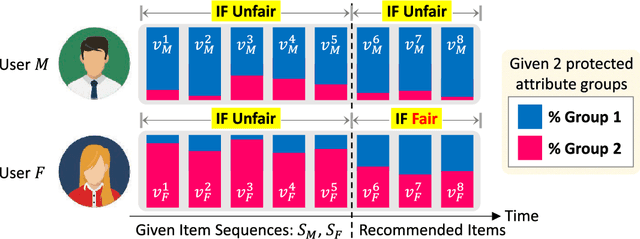
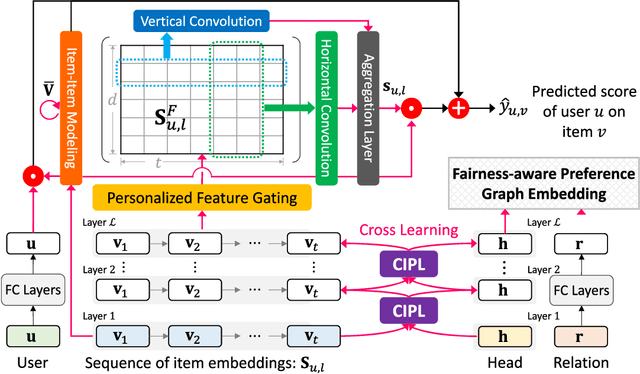
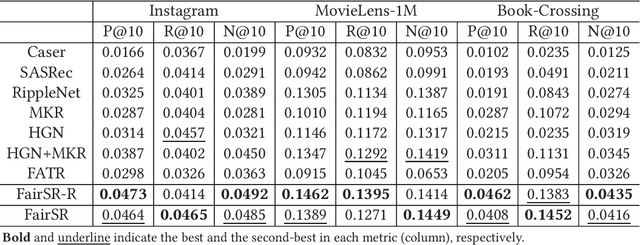
Sequential recommendation (SR) learns from the temporal dynamics of user-item interactions to predict the next ones. Fairness-aware recommendation mitigates a variety of algorithmic biases in the learning of user preferences. This paper aims at bringing a marriage between SR and algorithmic fairness. We propose a novel fairness-aware sequential recommendation task, in which a new metric, interaction fairness, is defined to estimate how recommended items are fairly interacted by users with different protected attribute groups. We propose a multi-task learning based deep end-to-end model, FairSR, which consists of two parts. One is to learn and distill personalized sequential features from the given user and her item sequence for SR. The other is fairness-aware preference graph embedding (FPGE). The aim of FPGE is two-fold: incorporating the knowledge of users' and items' attributes and their correlation into entity representations, and alleviating the unfair distributions of user attributes on items. Extensive experiments conducted on three datasets show FairSR can outperform state-of-the-art SR models in recommendation performance. In addition, the recommended items by FairSR also exhibit promising interaction fairness.
WikiContradiction: Detecting Self-Contradiction Articles on Wikipedia
Nov 16, 2021

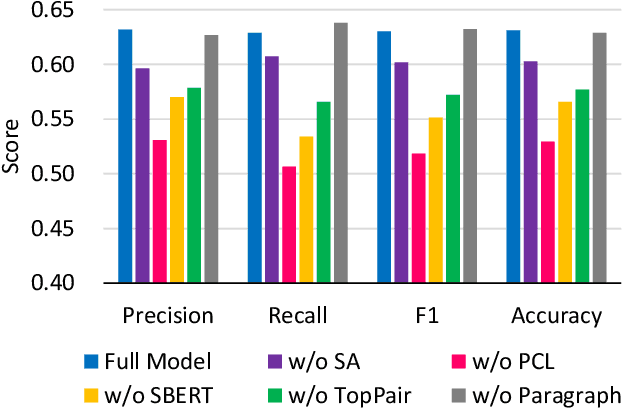
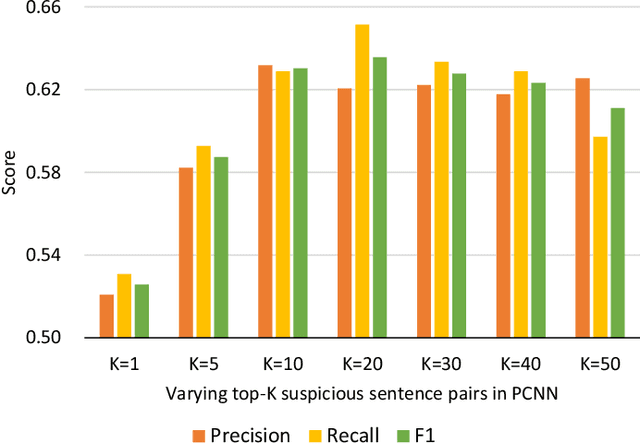
While Wikipedia has been utilized for fact-checking and claim verification to debunk misinformation and disinformation, it is essential to either improve article quality and rule out noisy articles. Self-contradiction is one of the low-quality article types in Wikipedia. In this work, we propose a task of detecting self-contradiction articles in Wikipedia. Based on the "self-contradictory" template, we create a novel dataset for the self-contradiction detection task. Conventional contradiction detection focuses on comparing pairs of sentences or claims, but self-contradiction detection needs to further reason the semantics of an article and simultaneously learn the contradiction-aware comparison from all pairs of sentences. Therefore, we present the first model, Pairwise Contradiction Neural Network (PCNN), to not only effectively identify self-contradiction articles, but also highlight the most contradiction pairs of contradiction sentences. The main idea of PCNN is two-fold. First, to mitigate the effect of data scarcity on self-contradiction articles, we pre-train the module of pairwise contradiction learning using SNLI and MNLI benchmarks. Second, we select top-K sentence pairs with the highest contradiction probability values and model their correlation to determine whether the corresponding article belongs to self-contradiction. Experiments conducted on the proposed WikiContradiction dataset exhibit that PCNN can generate promising performance and comprehensively highlight the sentence pairs the contradiction locates.
NetFense: Adversarial Defenses against Privacy Attacks on Neural Networks for Graph Data
Jun 22, 2021



Recent advances in protecting node privacy on graph data and attacking graph neural networks (GNNs) gain much attention. The eye does not bring these two essential tasks together yet. Imagine an adversary can utilize the powerful GNNs to infer users' private labels in a social network. How can we adversarially defend against such privacy attacks while maintaining the utility of perturbed graphs? In this work, we propose a novel research task, adversarial defenses against GNN-based privacy attacks, and present a graph perturbation-based approach, NetFense, to achieve the goal. NetFense can simultaneously keep graph data unnoticeability (i.e., having limited changes on the graph structure), maintain the prediction confidence of targeted label classification (i.e., preserving data utility), and reduce the prediction confidence of private label classification (i.e., protecting the privacy of nodes). Experiments conducted on single- and multiple-target perturbations using three real graph data exhibit that the perturbed graphs by NetFense can effectively maintain data utility (i.e., model unnoticeability) on targeted label classification and significantly decrease the prediction confidence of private label classification (i.e., privacy protection). Extensive studies also bring several insights, such as the flexibility of NetFense, preserving local neighborhoods in data unnoticeability, and better privacy protection for high-degree nodes.
* Accepted to IEEE TKDE 2021. Code is available at https://github.com/ICHproject/NetFense/
FinGAT: Financial Graph Attention Networks for Recommending Top-K Profitable Stocks
Jun 18, 2021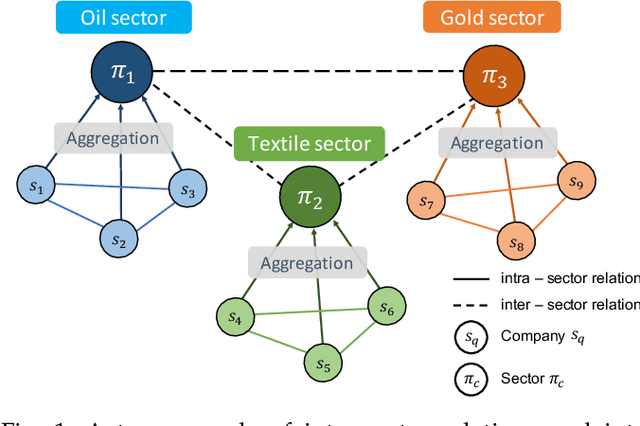

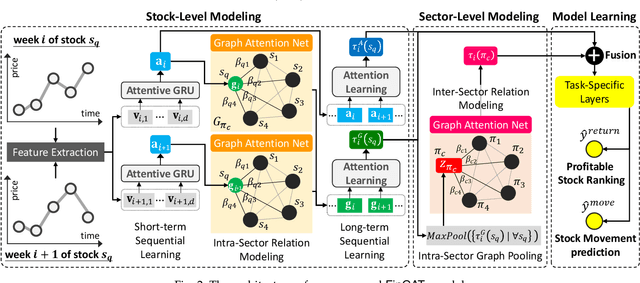
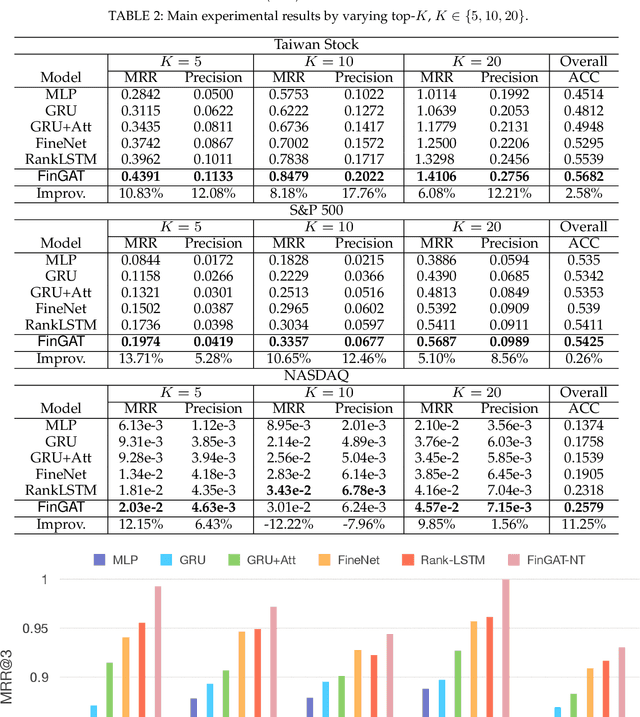
Financial technology (FinTech) has drawn much attention among investors and companies. While conventional stock analysis in FinTech targets at predicting stock prices, less effort is made for profitable stock recommendation. Besides, in existing approaches on modeling time series of stock prices, the relationships among stocks and sectors (i.e., categories of stocks) are either neglected or pre-defined. Ignoring stock relationships will miss the information shared between stocks while using pre-defined relationships cannot depict the latent interactions or influence of stock prices between stocks. In this work, we aim at recommending the top-K profitable stocks in terms of return ratio using time series of stock prices and sector information. We propose a novel deep learning-based model, Financial Graph Attention Networks (FinGAT), to tackle the task under the setting that no pre-defined relationships between stocks are given. The idea of FinGAT is three-fold. First, we devise a hierarchical learning component to learn short-term and long-term sequential patterns from stock time series. Second, a fully-connected graph between stocks and a fully-connected graph between sectors are constructed, along with graph attention networks, to learn the latent interactions among stocks and sectors. Third, a multi-task objective is devised to jointly recommend the profitable stocks and predict the stock movement. Experiments conducted on Taiwan Stock, S&P 500, and NASDAQ datasets exhibit remarkable recommendation performance of our FinGAT, comparing to state-of-the-art methods.