 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Dialogues: Enhancing Image Selection through Dialogue Understanding with Large Language Models
Jul 04, 2024



Recent advancements in dialogue systems have highlighted the significance of integrating multimodal responses, which enable conveying ideas through diverse modalities rather than solely relying on text-based interactions. This enrichment not only improves overall communicative efficacy but also enhances the quality of conversational experiences. However, existing methods for dialogue-to-image retrieval face limitations due to the constraints of pre-trained vision language models (VLMs) in comprehending complex dialogues accurately. To address this, we present a novel approach leveraging the robust reasoning capabilities of large language models (LLMs) to generate precise dialogue-associated visual descriptors, facilitating seamless connection with images. Extensive experiments conducted on benchmark data validate the effectiveness of our proposed approach in deriving concise and accurate visual descriptors, leading to significant enhancements in dialogue-to-image retrieval performance. Furthermore, our findings demonstrate the method's generalizability across diverse visual cues, various LLMs, and different datasets, underscoring its practicality and potential impact in real-world applications.
A Survey of Data Synthesis Approaches
Jul 04, 2024This paper provides a detailed survey of synthetic data techniques. We first discuss the expected goals of using synthetic data in data augmentation, which can be divided into four parts: 1) Improving Diversity, 2) Data Balancing, 3) Addressing Domain Shift, and 4) Resolving Edge Cases. Synthesizing data are closely related to the prevailing machine learning techniques at the time, therefore, we summarize the domain of synthetic data techniques into four categories: 1) Expert-knowledge, 2) Direct Training, 3) Pre-train then Fine-tune, and 4) Foundation Models without Fine-tuning. Next, we categorize the goals of synthetic data filtering into four types for discussion: 1) Basic Quality, 2) Label Consistency, and 3) Data Distribution. In section 5 of this paper, we also discuss the future directions of synthetic data and state three direction that we believe is important: 1) focus more on quality, 2) the evaluation of synthetic data, and 3) multi-model data augmentation.
Environment Diversification with Multi-head Neural Network for Invariant Learning
Aug 17, 2023
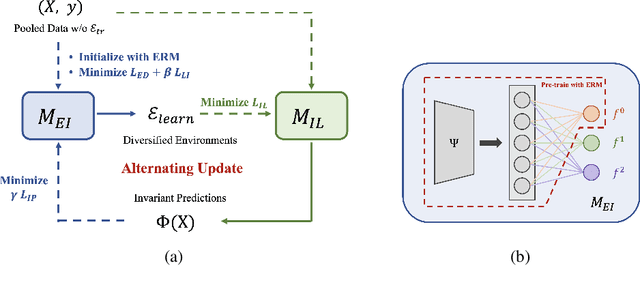
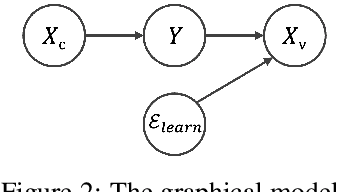

Neural networks are often trained with empirical risk minimization; however, it has been shown that a shift between training and testing distributions can cause unpredictable performance degradation. On this issue, a research direction, invariant learning, has been proposed to extract invariant features insensitive to the distributional changes. This work proposes EDNIL, an invariant learning framework containing a multi-head neural network to absorb data biases. We show that this framework does not require prior knowledge about environments or strong assumptions about the pre-trained model. We also reveal that the proposed algorithm has theoretical connections to recent studies discussing properties of variant and invariant features. Finally, we demonstrate that models trained with EDNIL are empirically more robust against distributional shifts.