 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Data Synthesis Approaches
Jul 04, 2024This paper provides a detailed survey of synthetic data techniques. We first discuss the expected goals of using synthetic data in data augmentation, which can be divided into four parts: 1) Improving Diversity, 2) Data Balancing, 3) Addressing Domain Shift, and 4) Resolving Edge Cases. Synthesizing data are closely related to the prevailing machine learning techniques at the time, therefore, we summarize the domain of synthetic data techniques into four categories: 1) Expert-knowledge, 2) Direct Training, 3) Pre-train then Fine-tune, and 4) Foundation Models without Fine-tuning. Next, we categorize the goals of synthetic data filtering into four types for discussion: 1) Basic Quality, 2) Label Consistency, and 3) Data Distribution. In section 5 of this paper, we also discuss the future directions of synthetic data and state three direction that we believe is important: 1) focus more on quality, 2) the evaluation of synthetic data, and 3) multi-model data augmentation.
Domain-Specific Mappings for Generative Adversarial Style Transfer
Aug 05, 2020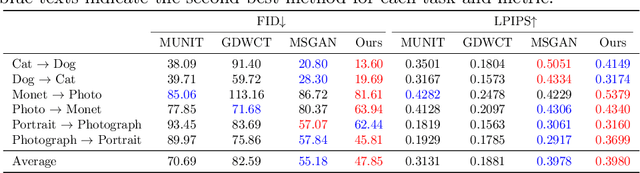
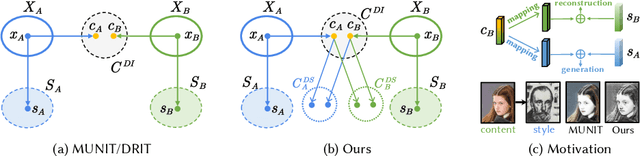
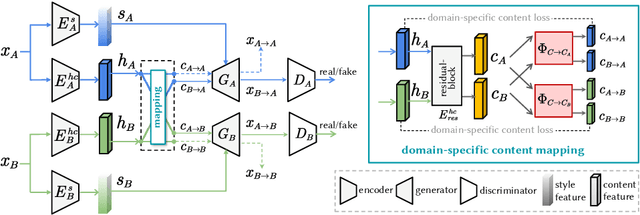

Style transfer generates an image whose content comes from one image and style from the other. Image-to-image translation approaches with disentangled representations have been shown effective for style transfer between two image categories. However, previous methods often assume a shared domain-invariant content space, which could compromise the content representation power. For addressing this issue, this paper leverages domain-specific mappings for remapping latent features in the shared content space to domain-specific content spaces. This way, images can be encoded more properly for style transfer. Experiments show that the proposed method outperforms previous style transfer methods, particularly on challenging scenarios that would require semantic correspondences between images. Code and results are available at https://acht7111020.github.io/DSMAP-demo/.
Deep Reinforcement Learning for Playing 2.5D Fighting Games
May 05, 2018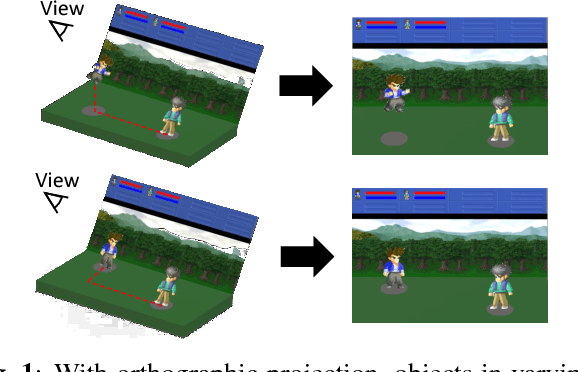
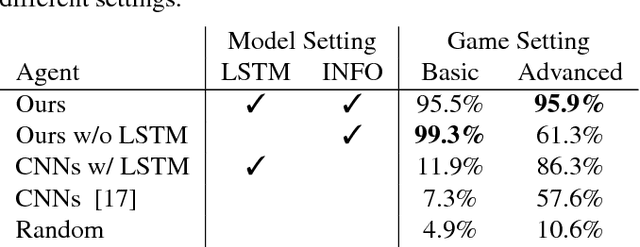
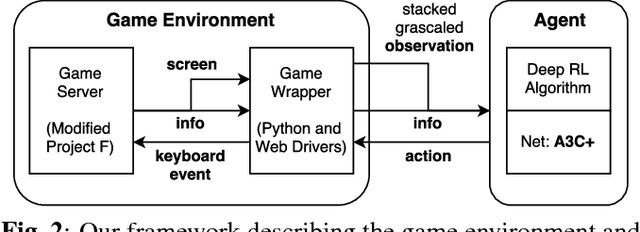

Deep reinforcement learning has shown its success in game playing. However, 2.5D fighting games would be a challenging task to handle due to ambiguity in visual appearances like height or depth of the characters. Moreover, actions in such games typically involve particular sequential action orders, which also makes the network design very difficult. Based on the network of Asynchronous Advantage Actor-Critic (A3C), we create an OpenAI-gym-like gaming environment with the game of Little Fighter 2 (LF2), and present a novel A3C+ network for learning RL agents. The introduced model includes a Recurrent Info network, which utilizes game-related info features with recurrent layers to observe combo skills for fighting. In the experiments, we consider LF2 in different settings, which successfully demonstrates the use of our proposed model for learning 2.5D fighting games.