 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapNav: A Novel Memory Representation via Annotated Semantic Maps for VLM-based Vision-and-Language Navigation
Feb 19, 2025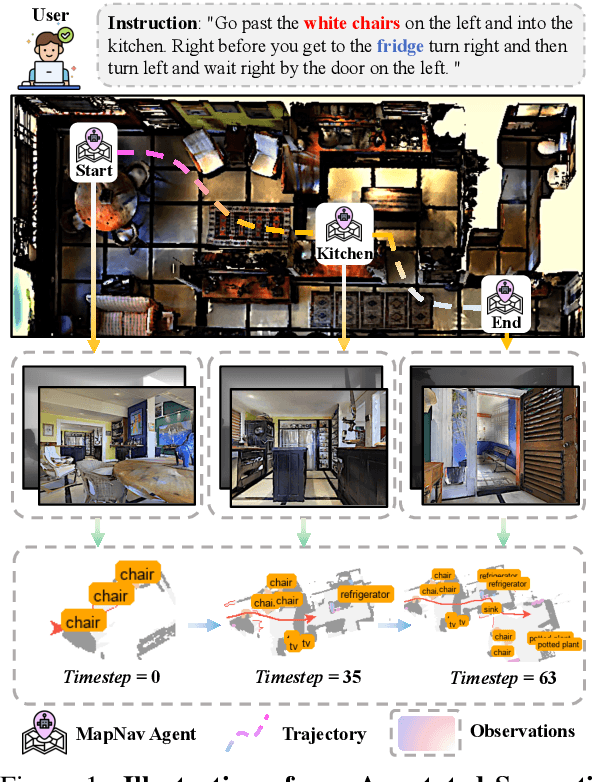
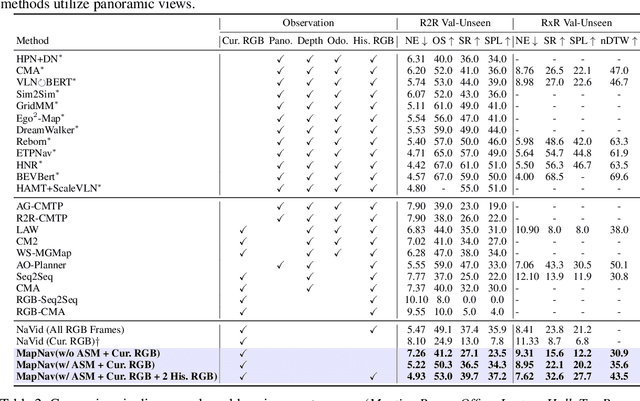
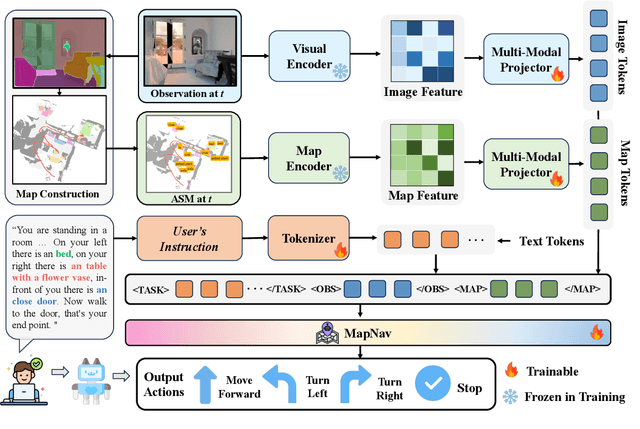

Vision-and-language navigation (VLN) is a key task in Embodied AI, requiring agents to navigate diverse and unseen environments while following natural language instructions. Traditional approaches rely heavily on historical observations as spatio-temporal contexts for decision making, leading to significant storage and computational overhead. In this paper, we introduce MapNav, a novel end-to-end VLN model that leverages Annotated Semantic Map (ASM) to replace historical frames. Specifically, our approach constructs a top-down semantic map at the start of each episode and update it at each timestep, allowing for precise object mapping and structured navigation information. Then, we enhance this map with explicit textual labels for key regions, transforming abstract semantics into clear navigation cues and generate our ASM. MapNav agent using the constructed ASM as input, and use the powerful end-to-end capabilities of VLM to empower VLN. Extensive experiments demonstrate that MapNav achieves state-of-the-art (SOTA) performance in both simulated and real-world environments, validating the effectiveness of our method. Moreover, we will release our ASM generation source code and dataset to ensure reproducibility, contributing valuable resources to the field. We believe that our proposed MapNav can be used as a new memory representation method in VLN, paving the way for future research in this field.
Multi-Floor Zero-Shot Object Navigation Policy
Sep 17, 2024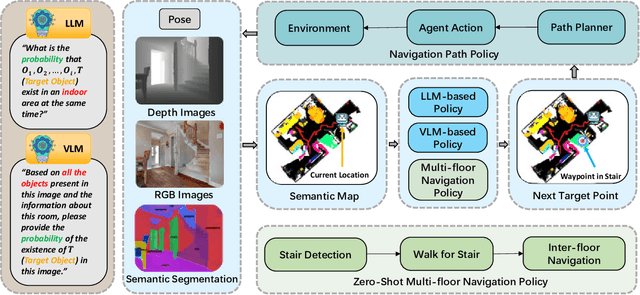
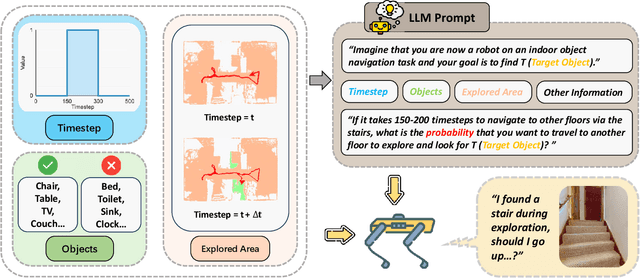


Object navigation in multi-floor environments presents a formidable challenge in robotics, requiring sophisticated spatial reasoning and adaptive exploration strategies. Traditional approaches have primarily focused on single-floor scenarios, overlooking the complexities introduced by multi-floor structures. To address these challenges, we first propose a Multi-floor Navigation Policy (MFNP) and implement it in Zero-Shot object navigation tasks. Our framework comprises three key components: (i) Multi-floor Navigation Policy, which enables an agent to explore across multiple floors; (ii) Multi-modal Large Language Models (MLLMs) for reasoning in the navigation process; and (iii) Inter-Floor Navigation, ensuring efficient floor transitions. We evaluate MFNP on the Habitat-Matterport 3D (HM3D) and Matterport 3D (MP3D) datasets, both include multi-floor scenes. Our experiment results demonstrate that MFNP significantly outperforms all the existing methods in Zero-Shot object navigation, achieving higher success rates and improved exploration efficiency. Ablation studies further highlight the effectiveness of each component in addressing the unique challenges of multi-floor navigation. Meanwhile, we conducted real-world experiments to evaluate the feasibility of our policy. Upon deployment of MFNP, the Unitree quadruped robot demonstrated successful multi-floor navigation and found the target object in a completely unseen environment. By introducing MFNP, we offer a new paradigm for tackling complex, multi-floor environments in object navigation tasks, opening avenues for future research in visual-based navigation in realistic, multi-floor settings.
RoboGPT: an intelligent agent of making embodied long-term decisions for daily instruction tasks
Nov 27, 2023Robotic agents must master common sense and long-term sequential decisions to solve daily tasks through natural language instruction. The developments in Large Language Models (LLMs) in natural language processing have inspired efforts to use LLMs in complex robot planning. Despite LLMs' great generalization and comprehension of instruction tasks, LLMs-generated task plans sometimes lack feasibility and correctness. To address the problem, we propose a RoboGPT agent\footnote{our code and dataset will be released soon} for making embodied long-term decisions for daily tasks, with two modules: 1) LLMs-based planning with re-plan to break the task into multiple sub-goals; 2) RoboSkill individually designed for sub-goals to learn better navigation and manipulation skills. The LLMs-based planning is enhanced with a new robotic dataset and re-plan, called RoboGPT. The new robotic dataset of 67k daily instruction tasks is gathered for fine-tuning the Llama model and obtaining RoboGPT. RoboGPT planner with strong generalization can plan hundreds of daily instruction tasks. Additionally, a low-computational Re-Plan module is designed to allow plans to flexibly adapt to the environment, thereby addressing the nomenclature diversity challenge. The proposed RoboGPT agent outperforms SOTA methods on the ALFRED daily tasks. Moreover, RoboGPT planner exceeds SOTA LLM-based planners like ChatGPT in task-planning rationality for hundreds of unseen daily tasks, and even other domain tasks, while keeping the large model's original broad application and generality.