 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapNav: A Novel Memory Representation via Annotated Semantic Maps for VLM-based Vision-and-Language Navigation
Paper and Code
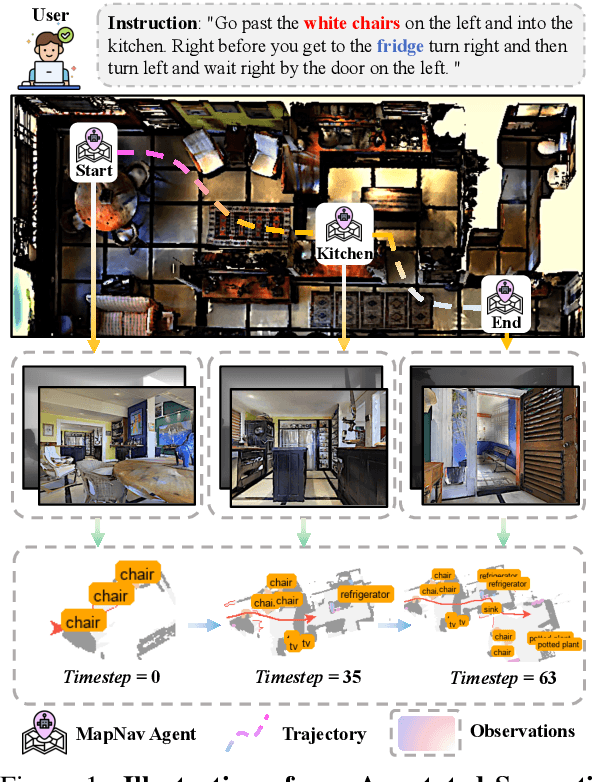
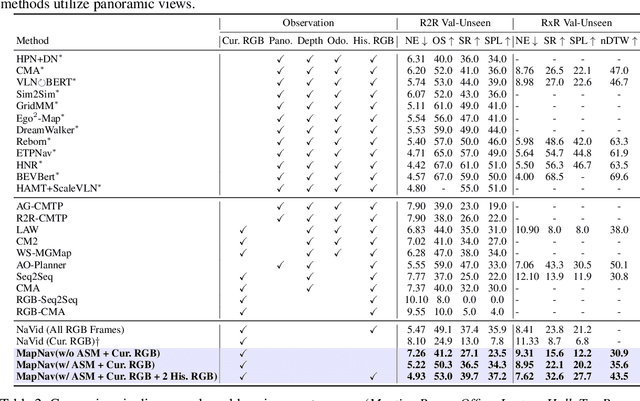
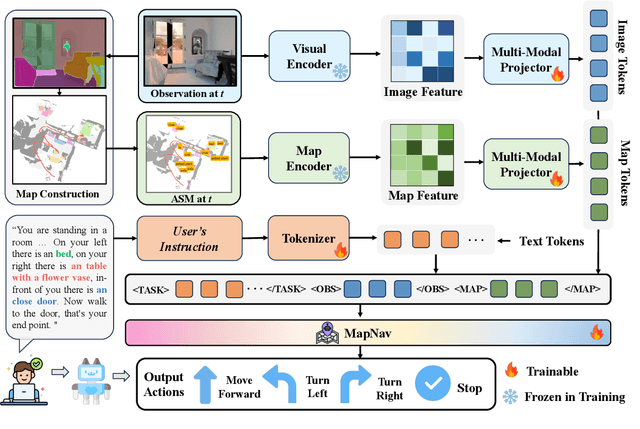

Vision-and-language navigation (VLN) is a key task in Embodied AI, requiring agents to navigate diverse and unseen environments while following natural language instructions. Traditional approaches rely heavily on historical observations as spatio-temporal contexts for decision making, leading to significant storage and computational overhead. In this paper, we introduce MapNav, a novel end-to-end VLN model that leverages Annotated Semantic Map (ASM) to replace historical frames. Specifically, our approach constructs a top-down semantic map at the start of each episode and update it at each timestep, allowing for precise object mapping and structured navigation information. Then, we enhance this map with explicit textual labels for key regions, transforming abstract semantics into clear navigation cues and generate our ASM. MapNav agent using the constructed ASM as input, and use the powerful end-to-end capabilities of VLM to empower VLN. Extensive experiments demonstrate that MapNav achieves state-of-the-art (SOTA) performance in both simulated and real-world environments, validating the effectiveness of our method. Moreover, we will release our ASM generation source code and dataset to ensure reproducibility, contributing valuable resources to the field. We believe that our proposed MapNav can be used as a new memory representation method in VLN, paving the way for future research in this field.