 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3ICRO: Machine Learning-Enabled Compact Photonic Tensor Core based on PRogrammable Multi-Operand Multimode Interference
May 31, 2023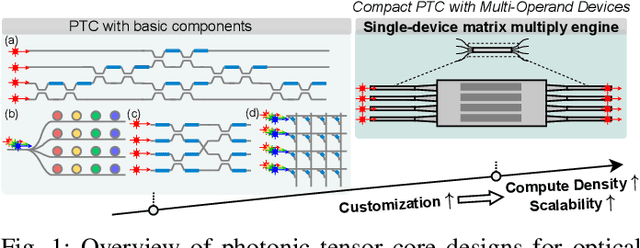
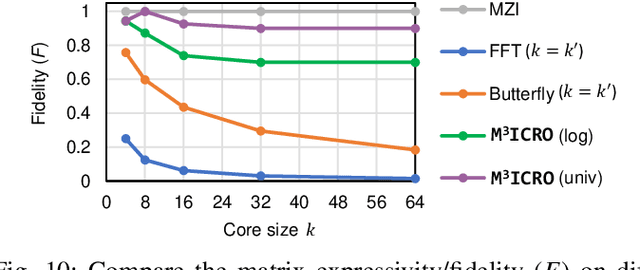
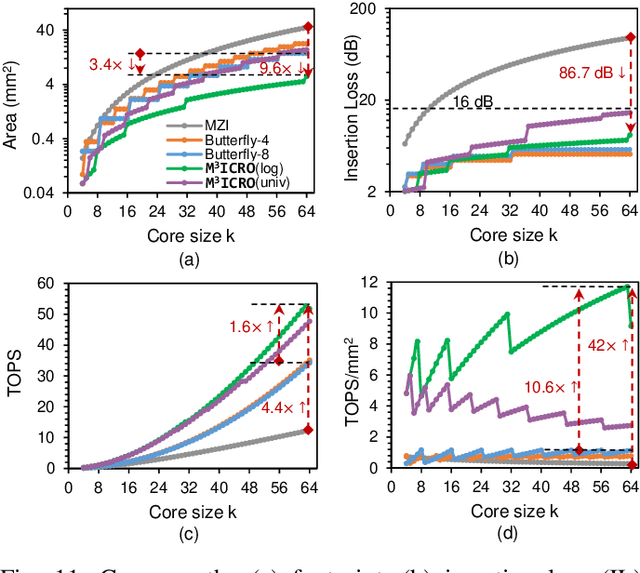
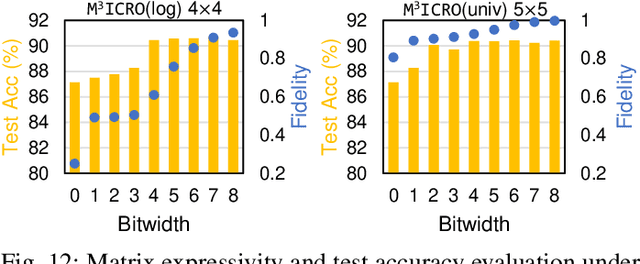
Photonic computing shows promise for transformative advancements in machine learning (ML) acceleration, offering ultra-fast speed, massive parallelism, and high energy efficiency. However, current photonic tensor core (PTC) designs based on standard optical components hinder scalability and compute density due to their large spatial footprint. To address this, we propose an ultra-compact PTC using customized programmable multi-operand multimode interference (MOMMI) devices, named M3ICRO. The programmable MOMMI leverages the intrinsic light propagation principle, providing a single-device programmable matrix unit beyond the conventional computing paradigm of one multiply-accumulate (MAC) operation per device. To overcome the optimization difficulty of customized devices that often requires time-consuming simulation, we apply ML for optics to predict the device behavior and enable a differentiable optimization flow. We thoroughly investigate the reconfigurability and matrix expressivity of our customized PTC, and introduce a novel block unfolding method to fully exploit the computing capabilities of a complex-valued PTC for near-universal real-valued linear transformations. Extensive evaluations demonstrate that M3ICRO achieves a 3.4-9.6x smaller footprint, 1.6-4.4x higher speed, 10.6-42x higher compute density, 3.7-12x higher system throughput, and superior noise robustness compared to state-of-the-art coherent PTC designs, while maintaining close-to-digital task accuracy across various ML benchmarks. Our code is open-sourced at https://github.com/JeremieMelo/M3ICRO-MOMMI.
Integrated multi-operand optical neurons for scalable and hardware-efficient deep learning
May 31, 2023The optical neural network (ONN) is a promising hardware platform for next-generation neuromorphic computing due to its high parallelism, low latency, and low energy consumption. However, previous integrated photonic tensor cores (PTCs) consume numerous single-operand optical modulators for signal and weight encoding, leading to large area costs and high propagation loss to implement large tensor operations. This work proposes a scalable and efficient optical dot-product engine based on customized multi-operand photonic devices, namely multi-operand optical neurons (MOON). We experimentally demonstrate the utility of a MOON using a multi-operand-Mach-Zehnder-interferometer (MOMZI) in image recognition tasks. Specifically, our MOMZI-based ONN achieves a measured accuracy of 85.89% in the street view house number (SVHN) recognition dataset with 4-bit voltage control precision. Furthermore, our performance analysis reveals that a 128x128 MOMZI-based PTCs outperform their counterparts based on single-operand MZIs by one to two order-of-magnitudes in propagation loss, optical delay, and total device footprint, with comparable matrix expressivity.
NeurOLight: A Physics-Agnostic Neural Operator Enabling Parametric Photonic Device Simulation
Sep 19, 2022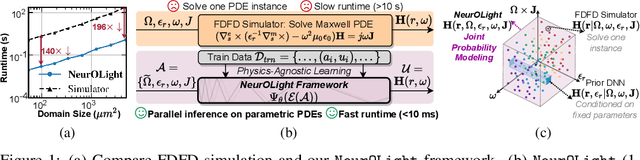
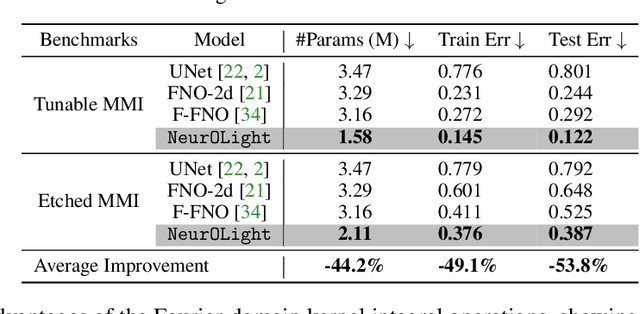
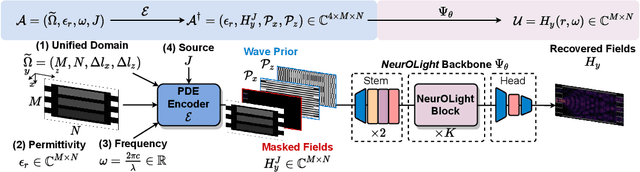
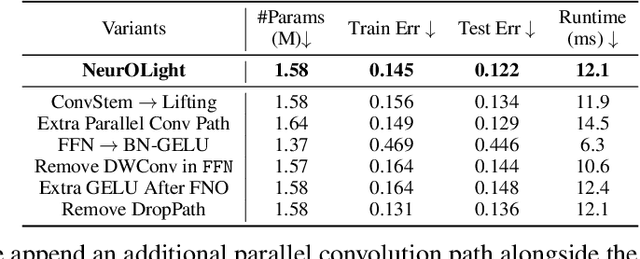
Optical computing is an emerging technology for next-generation efficient artificial intelligence (AI) due to its ultra-high speed and efficiency. Electromagnetic field simulation is critical to the design, optimization, and validation of photonic devices and circuits. However, costly numerical simulation significantly hinders the scalability and turn-around time in the photonic circuit design loop. Recently, physics-informed neural networks have been proposed to predict the optical field solution of a single instance of a partial differential equation (PDE) with predefined parameters. Their complicated PDE formulation and lack of efficient parametrization mechanisms limit their flexibility and generalization in practical simulation scenarios. In this work, for the first time, a physics-agnostic neural operator-based framework, dubbed NeurOLight, is proposed to learn a family of frequency-domain Maxwell PDEs for ultra-fast parametric photonic device simulation. We balance the efficiency and generalization of NeurOLight via several novel techniques. Specifically, we discretize different devices into a unified domain, represent parametric PDEs with a compact wave prior, and encode the incident light via masked source modeling. We design our model with parameter-efficient cross-shaped NeurOLight blocks and adopt superposition-based augmentation for data-efficient learning. With these synergistic approaches, NeurOLight generalizes to a large space of unseen simulation settings, demonstrates 2-orders-of-magnitude faster simulation speed than numerical solvers, and outperforms prior neural network models by ~54% lower prediction error with ~44% fewer parameters. Our code is available at https://github.com/JeremieMelo/NeurOLight.
Weighted Sum Rate Maximization of the mmWave Cell-Free MIMO Downlink Relying on Hybrid Precoding
Jan 12, 2022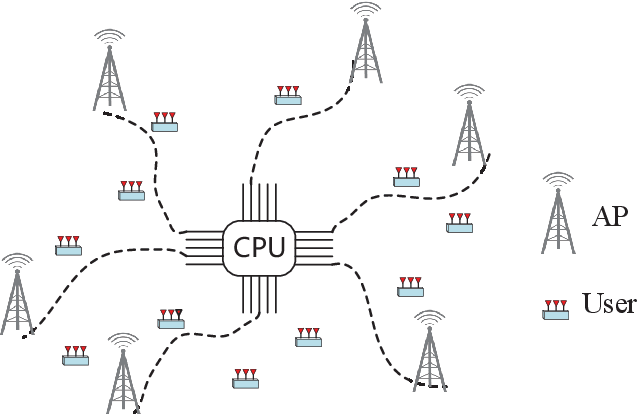
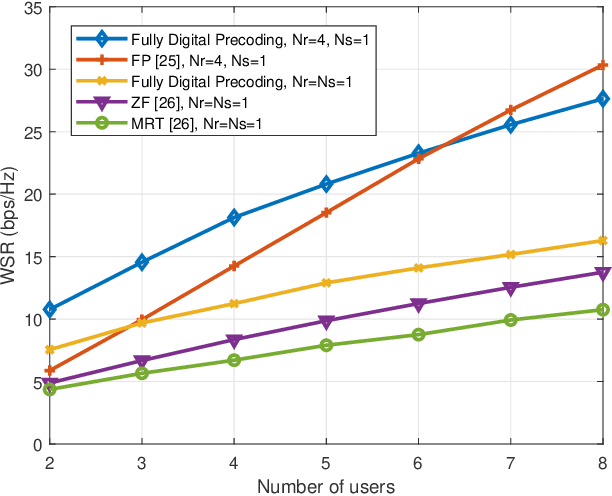
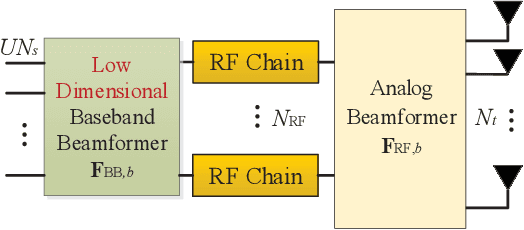
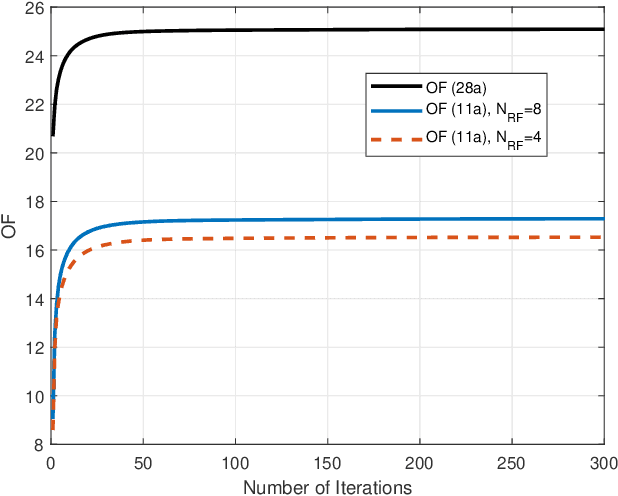
The cell-free MIMO concept relying on hybrid precoding constitutes an innovative technique capable of dramatically increasing the network capacity of millimeter-wave (mmWave) communication systems. It dispenses with the cell boundary of conventional multi-cell MIMO systems, while drastically reducing the power consumption by limiting the number of radio frequency (RF) chains at the access points (APs). In this paper, we aim for maximizing the weighted sum rate (WSR) of mmWave cell-free MIMO systems by conceiving a low-complexity hybrid precoding algorithm. We formulate the WSR optimization problem subject to the transmit power constraint for each AP and the constant-modulus constraint for the phase shifters of the analog precoders. A block coordinate descent (BCD) algorithm is proposed for iteratively solving the problem. In each iteration, the classic Lagrangian multiplier method and the penalty dual decomposition (PDD) method are combined for obtaining near-optimal hybrid analog/digital precoding matrices. Furthermore, we extend our proposed algorithm for deriving closed-form expressions for the precoders of fully digital cell-free MIMO systems. Moreover, we present the convergency analysis and complexity analysis of our proposed method. Finally, our simulation results demonstrate the superiority of the algorithms proposed for both fully digital and hybrid precoding matrices.
Joint Hybrid and Passive RIS-Assisted Beamforming for MmWave MIMO Systems Relying on Dynamically Configured Subarrays
Jan 12, 2022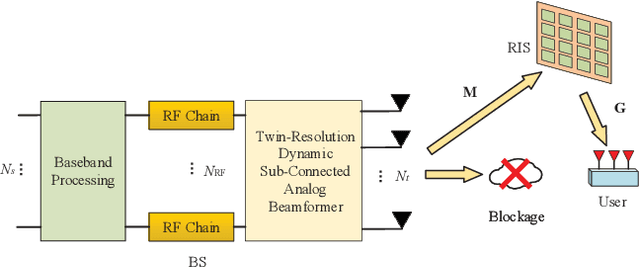
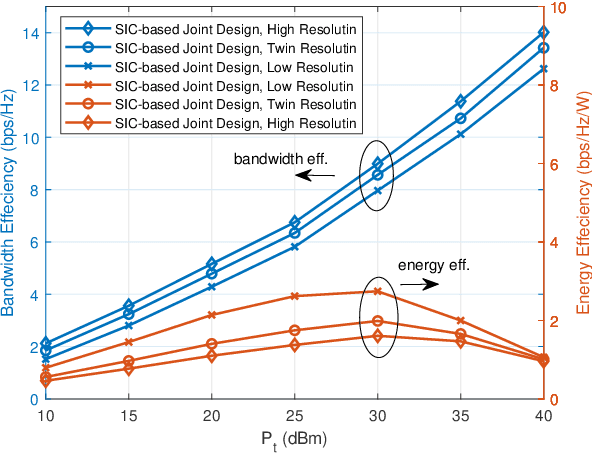


Reconfigurable intelligent surface (RIS) assisted millimeter-wave (mmWave) communication systems relying on hybrid beamforming structures are capable of achieving high spectral efficiency at a low hardware complexity and low power consumption. In this paper, we propose an RIS-assisted mmWave point-to-point system relying on dynamically configured sub-array connected hybrid beamforming structures. More explicitly, an energy-efficient analog beamformer relying on twin-resolution phase shifters is proposed. Then, we conceive a successive interference cancelation (SIC) based method for jointly designing the hybrid beamforming matrix of the base station (BS) and the passive beamforming matrix of the RIS. Specifically, the associated bandwidth-efficiency maximization problem is transformed into a series of sub-problems, where the sub-array of phase shifters and RIS elements are jointly optimized for maximizing each sub-array's rate. Furthermore, a greedy method is proposed for determining the phase shifter configuration of each sub-array. We then propose to update the RIS elements relying on a complex circle manifold (CCM)-based method. The proposed dynamic sub-connected structure as well as the proposed joint hybrid and passive beamforming method strikes an attractive trade-off between the bandwidth efficiency and power consumption. Our simulation results demonstrate the superiority of the proposed method compared to its traditional counterparts.
ELight: Enabling Efficient Photonic In-Memory Neurocomputing with Life Enhancement
Dec 15, 2021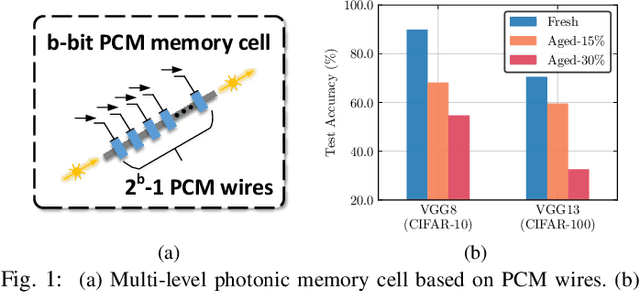
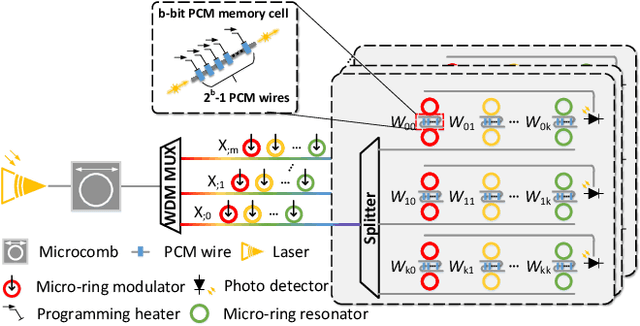
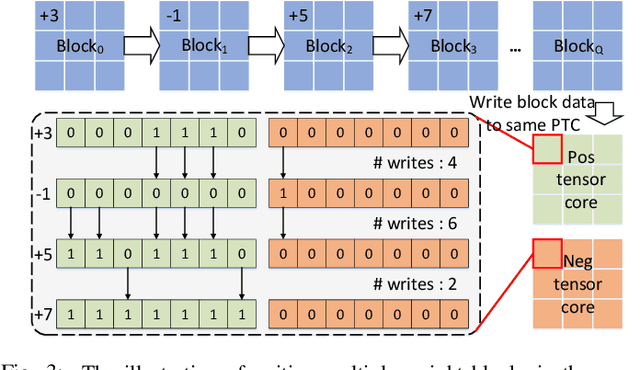
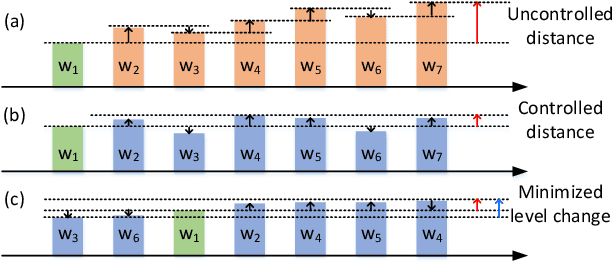
With the recent advances in optical phase change material (PCM), photonic in-memory neurocomputing has demonstrated its superiority in optical neural network (ONN) designs with near-zero static power consumption, time-of-light latency, and compact footprint. However, photonic tensor cores require massive hardware reuse to implement large matrix multiplication due to the limited single-core scale. The resultant large number of PCM writes leads to serious dynamic power and overwhelms the fragile PCM with limited write endurance. In this work, we propose a synergistic optimization framework, ELight, to minimize the overall write efforts for efficient and reliable optical in-memory neurocomputing. We first propose write-aware training to encourage the similarity among weight blocks, and combine it with a post-training optimization method to reduce programming efforts by eliminating redundant writes. Experiments show that ELight can achieve over 20X reduction in the total number of writes and dynamic power with comparable accuracy. With our ELight, photonic in-memory neurocomputing will step forward towards viable applications in machine learning with preserved accuracy, order-of-magnitude longer lifetime, and lower programming energy.
Silicon photonic subspace neural chip for hardware-efficient deep learning
Nov 11, 2021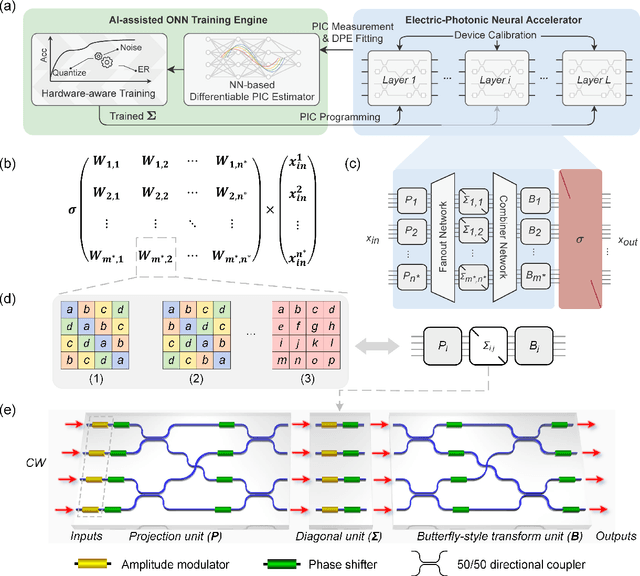
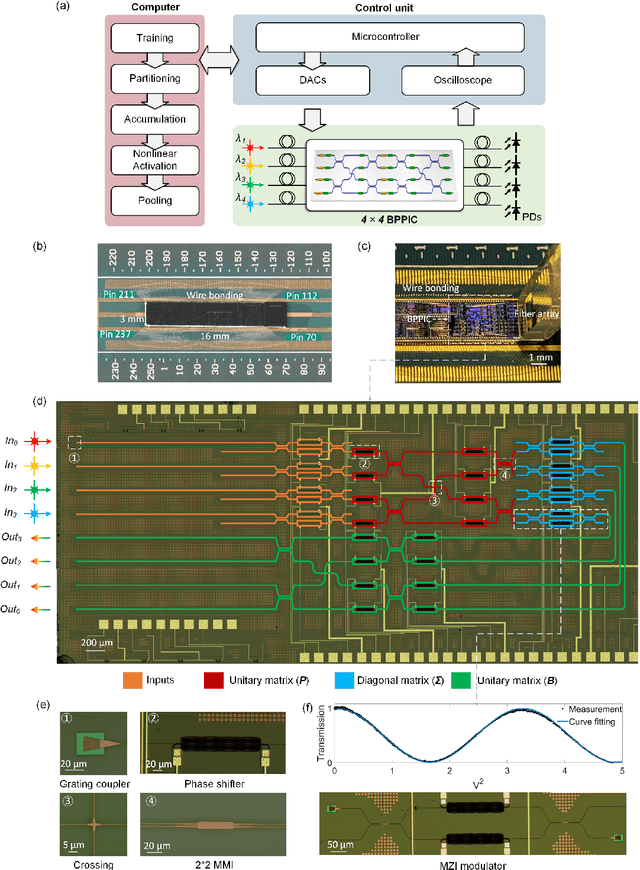
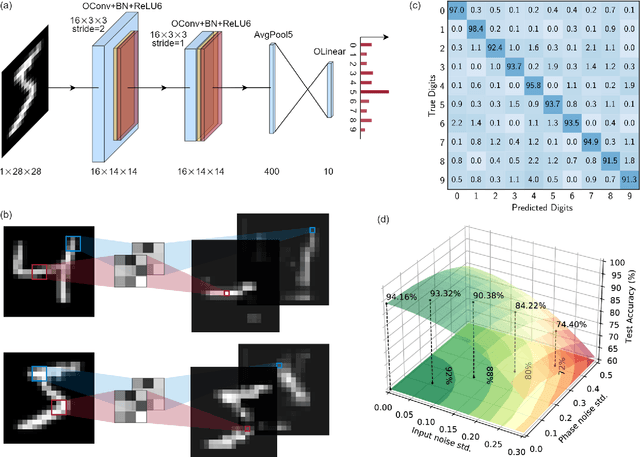
As deep learning has shown revolutionary performance in many artificial intelligence applications, its escalating computation demand requires hardware accelerators for massive parallelism and improved throughput. The optical neural network (ONN) is a promising candidate for next-generation neurocomputing due to its high parallelism, low latency, and low energy consumption. Here, we devise a hardware-efficient photonic subspace neural network (PSNN) architecture, which targets lower optical component usage, area cost, and energy consumption than previous ONN architectures with comparable task performance. Additionally, a hardware-aware training framework is provided to minimize the required device programming precision, lessen the chip area, and boost the noise robustness. We experimentally demonstrate our PSNN on a butterfly-style programmable silicon photonic integrated circuit and show its utility in practical image recognition tasks.
L2ight: Enabling On-Chip Learning for Optical Neural Networks via Efficient in-situ Subspace Optimization
Oct 27, 2021



Silicon-photonics-based optical neural network (ONN) is a promising hardware platform that could represent a paradigm shift in efficient AI with its CMOS-compatibility, flexibility, ultra-low execution latency, and high energy efficiency. In-situ training on the online programmable photonic chips is appealing but still encounters challenging issues in on-chip implementability, scalability, and efficiency. In this work, we propose a closed-loop ONN on-chip learning framework L2ight to enable scalable ONN mapping and efficient in-situ learning. L2ight adopts a three-stage learning flow that first calibrates the complicated photonic circuit states under challenging physical constraints, then performs photonic core mapping via combined analytical solving and zeroth-order optimization. A subspace learning procedure with multi-level sparsity is integrated into L2ight to enable in-situ gradient evaluation and fast adaptation, unleashing the power of optics for real on-chip intelligence. Extensive experiments demonstrate our proposed L2ight outperforms prior ONN training protocols with 3-order-of-magnitude higher scalability and over 30X better efficiency, when benchmarked on various models and learning tasks. This synergistic framework is the first scalable on-chip learning solution that pushes this emerging field from intractable to scalable and further to efficient for next-generation self-learnable photonic neural chips. From a co-design perspective, L2ight also provides essential insights for hardware-restricted unitary subspace optimization and efficient sparse training. We open-source our framework at https://github.com/JeremieMelo/L2ight.
Towards Memory-Efficient Neural Networks via Multi-Level in situ Generation
Sep 05, 2021



Deep neural networks (DNN) have shown superior performance in a variety of tasks. As they rapidly evolve, their escalating computation and memory demands make it challenging to deploy them on resource-constrained edge devices. Though extensive efficient accelerator designs, from traditional electronics to emerging photonics, have been successfully demonstrated, they are still bottlenecked by expensive memory accesses due to tremendous gaps between the bandwidth/power/latency of electrical memory and computing cores. Previous solutions fail to fully-leverage the ultra-fast computational speed of emerging DNN accelerators to break through the critical memory bound. In this work, we propose a general and unified framework to trade expensive memory transactions with ultra-fast on-chip computations, directly translating to performance improvement. We are the first to jointly explore the intrinsic correlations and bit-level redundancy within DNN kernels and propose a multi-level in situ generation mechanism with mixed-precision bases to achieve on-the-fly recovery of high-resolution parameters with minimum hardware overhead. Extensive experiments demonstrate that our proposed joint method can boost the memory efficiency by 10-20x with comparable accuracy over four state-of-the-art designs, when benchmarked on ResNet-18/DenseNet-121/MobileNetV2/V3 with various tasks.
Passive Beamforming Design for Intelligent Reflecting Surface Assisted MIMO Systems
Jun 02, 2021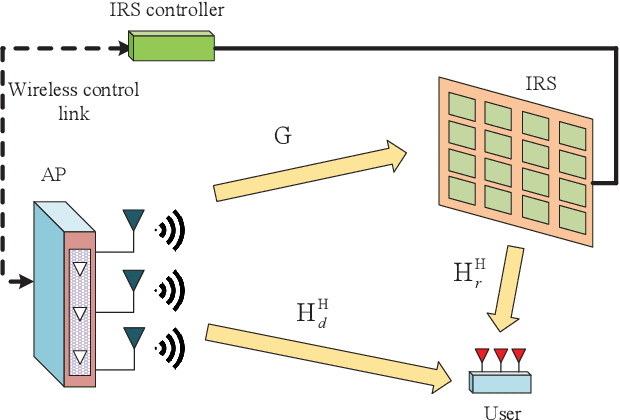



Intelligent reflecting surfaces (IRSs) constitute passive devices, which are capable of adjusting the phase shifts of their reflected signals, and hence they are suitable for passive beamforming. In this paper, we conceive their design with the active beamforming action of multiple-input multipleoutput (MIMO) systems used at the access points (APs) for improving the beamforming gain, where both the APs and users are equipped with multiple antennas. Firstly, we decouple the optimization problem and design the active beamforming for a given IRS configuration. Then we transform the optimization problem of the IRS-based passive beamforming design into a tractable non-convex quadratically constrained quadratic program (QCQP). For solving the transformed problem, we give an approximate solution based on the technique of widely used semidefinite relaxation (SDR). We also propose a low-complexity iterative solution. We further prove that it can converge to a locally optimal value. Finally, considering the practical scenario of discrete phase shifts at the IRS, we give the quantization design for IRS elements on basis of the two solutions. Our simulation results demonstrate the superiority of the proposed solutions over the relevant benchmarks.
* 12 pages, 7 figures