 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilicon photonic subspace neural chip for hardware-efficient deep learning
Nov 11, 2021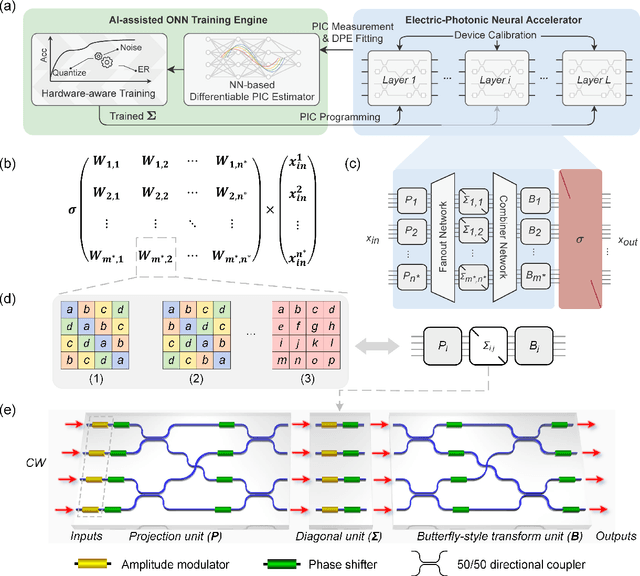
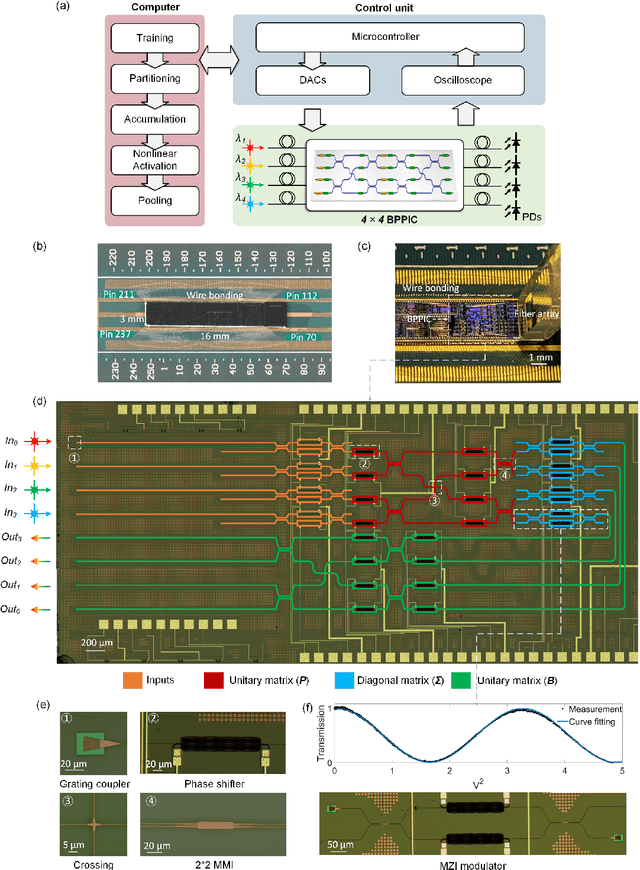
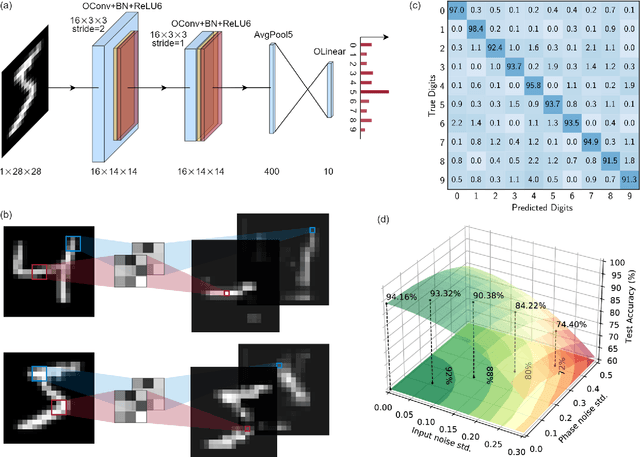
As deep learning has shown revolutionary performance in many artificial intelligence applications, its escalating computation demand requires hardware accelerators for massive parallelism and improved throughput. The optical neural network (ONN) is a promising candidate for next-generation neurocomputing due to its high parallelism, low latency, and low energy consumption. Here, we devise a hardware-efficient photonic subspace neural network (PSNN) architecture, which targets lower optical component usage, area cost, and energy consumption than previous ONN architectures with comparable task performance. Additionally, a hardware-aware training framework is provided to minimize the required device programming precision, lessen the chip area, and boost the noise robustness. We experimentally demonstrate our PSNN on a butterfly-style programmable silicon photonic integrated circuit and show its utility in practical image recognition tasks.
Efficient On-Chip Learning for Optical Neural Networks Through Power-Aware Sparse Zeroth-Order Optimization
Dec 21, 2020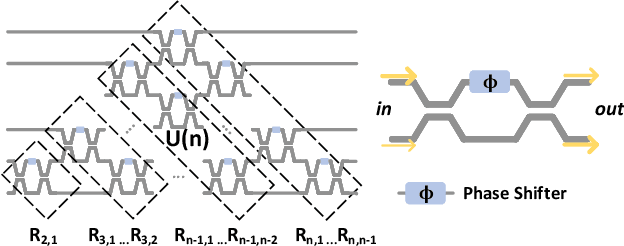
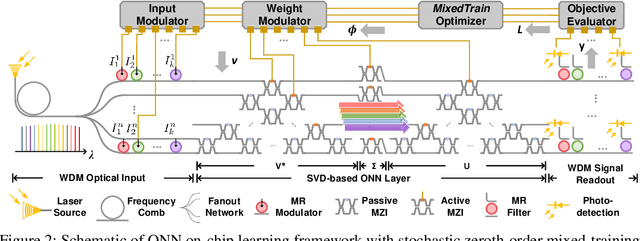

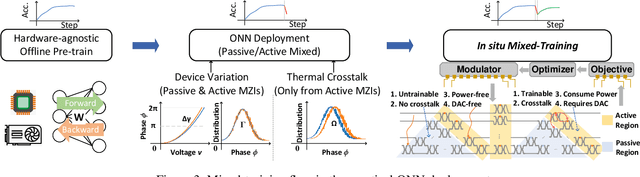
Optical neural networks (ONNs) have demonstrated record-breaking potential in high-performance neuromorphic computing due to their ultra-high execution speed and low energy consumption. However, current learning protocols fail to provide scalable and efficient solutions to photonic circuit optimization in practical applications. In this work, we propose a novel on-chip learning framework to release the full potential of ONNs for power-efficient in situ training. Instead of deploying implementation-costly back-propagation, we directly optimize the device configurations with computation budgets and power constraints. We are the first to model the ONN on-chip learning as a resource-constrained stochastic noisy zeroth-order optimization problem, and propose a novel mixed-training strategy with two-level sparsity and power-aware dynamic pruning to offer a scalable on-chip training solution in practical ONN deployment. Compared with previous methods, we are the first to optimize over 2,500 optical components on chip. We can achieve much better optimization stability, 3.7x-7.6x higher efficiency, and save >90% power under practical device variations and thermal crosstalk.