 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Hardware-Friendly Weight Quantization
Oct 07, 2022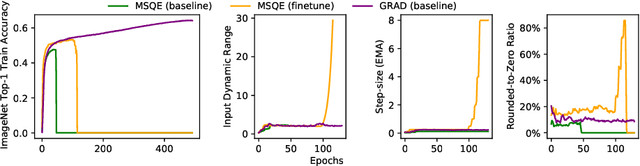
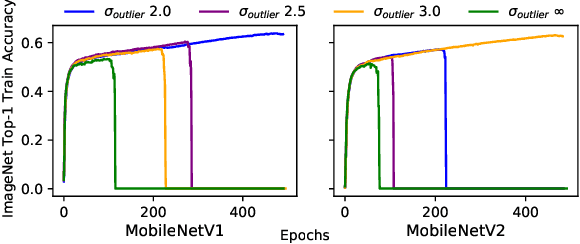
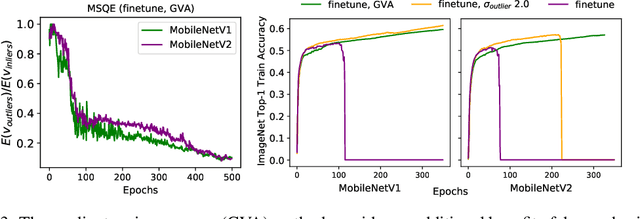
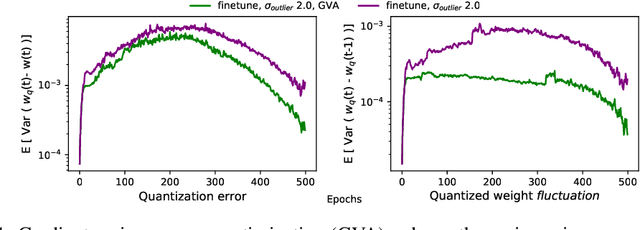
Quantizing a Deep Neural Network (DNN) model to be used on a custom accelerator with efficient fixed-point hardware implementations, requires satisfying many stringent hardware-friendly quantization constraints to train the model. We evaluate the two main classes of hardware-friendly quantization methods in the context of weight quantization: the traditional Mean Squared Quantization Error (MSQE)-based methods and the more recent gradient-based methods. We study the two methods on MobileNetV1 and MobileNetV2 using multiple empirical metrics to identify the sources of performance differences between the two classes, namely, sensitivity to outliers and convergence instability of the quantizer scaling factor. Using those insights, we propose various techniques to improve the performance of both quantization methods - they fix the optimization instability issues present in the MSQE-based methods during quantization of MobileNet models and allow us to improve validation performance of the gradient-based methods by 4.0% and 3.3% for MobileNetV1 and MobileNetV2 on ImageNet respectively.
Chip Placement with Deep Reinforcement Learning
Apr 22, 2020

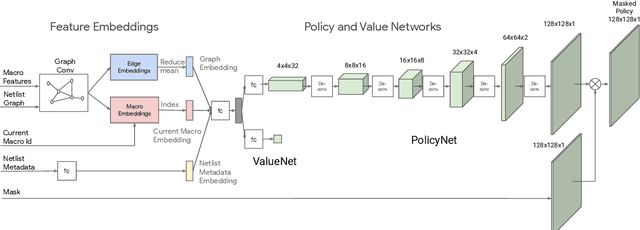
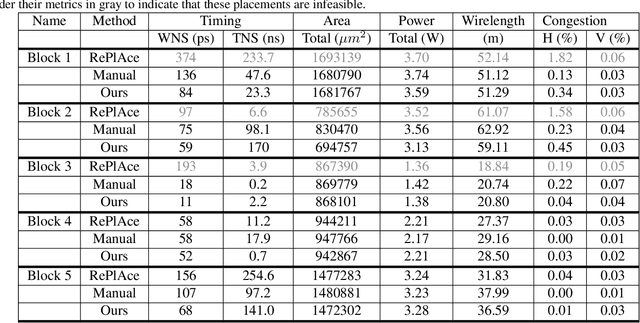
In this work, we present a learning-based approach to chip placement, one of the most complex and time-consuming stages of the chip design process. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of chip blocks, our method becomes better at rapidly generating optimized placements for previously unseen chip blocks. To achieve these results, we pose placement as a Reinforcement Learning (RL) problem and train an agent to place the nodes of a chip netlist onto a chip canvas. To enable our RL policy to generalize to unseen blocks, we ground representation learning in the supervised task of predicting placement quality. By designing a neural architecture that can accurately predict reward across a wide variety of netlists and their placements, we are able to generate rich feature embeddings of the input netlists. We then use this architecture as the encoder of our policy and value networks to enable transfer learning. Our objective is to minimize PPA (power, performance, and area), and we show that, in under 6 hours, our method can generate placements that are superhuman or comparable on modern accelerator netlists, whereas existing baselines require human experts in the loop and take several weeks.