 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Hardware-Friendly Weight Quantization
Paper and Code
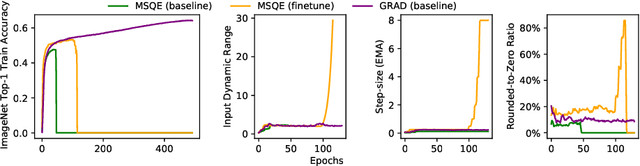
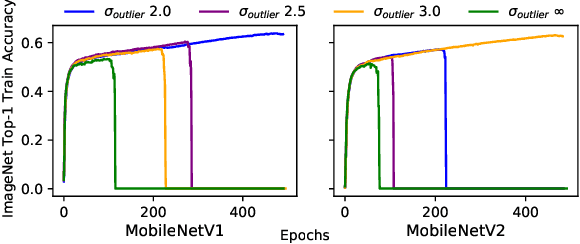
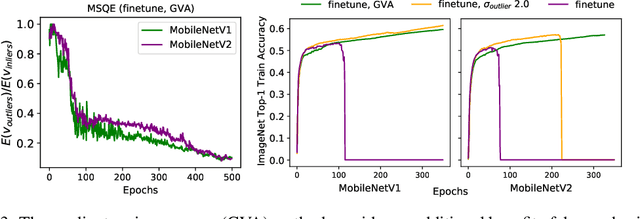
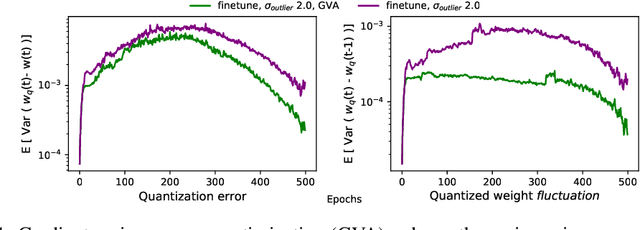
Quantizing a Deep Neural Network (DNN) model to be used on a custom accelerator with efficient fixed-point hardware implementations, requires satisfying many stringent hardware-friendly quantization constraints to train the model. We evaluate the two main classes of hardware-friendly quantization methods in the context of weight quantization: the traditional Mean Squared Quantization Error (MSQE)-based methods and the more recent gradient-based methods. We study the two methods on MobileNetV1 and MobileNetV2 using multiple empirical metrics to identify the sources of performance differences between the two classes, namely, sensitivity to outliers and convergence instability of the quantizer scaling factor. Using those insights, we propose various techniques to improve the performance of both quantization methods - they fix the optimization instability issues present in the MSQE-based methods during quantization of MobileNet models and allow us to improve validation performance of the gradient-based methods by 4.0% and 3.3% for MobileNetV1 and MobileNetV2 on ImageNet respectively.