 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Macro Placement with Reinforcement Learning
Sep 06, 2021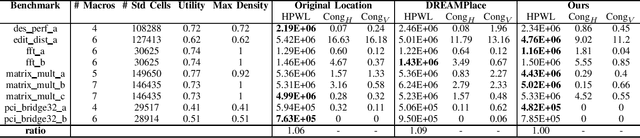
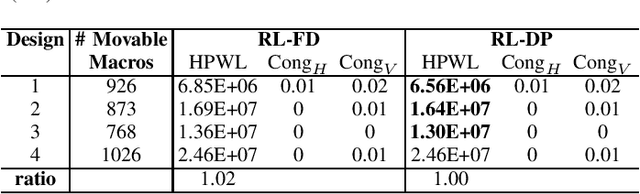
In physical design, human designers typically place macros via trial and error, which is a Markov decision process. Reinforcement learning (RL) methods have demonstrated superhuman performance on the macro placement. In this paper, we propose an extension to this prior work (Mirhoseini et al., 2020). We first describe the details of the policy and value network architecture. We replace the force-directed method with DREAMPlace for placing standard cells in the RL environment. We also compare our improved method with other academic placers on public benchmarks.
Chip Placement with Deep Reinforcement Learning
Apr 22, 2020

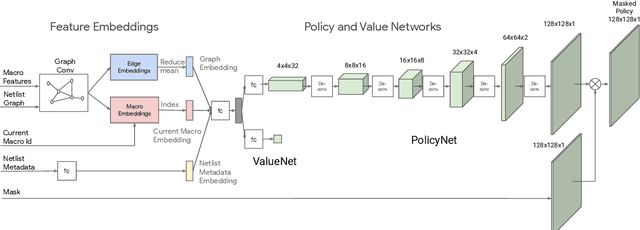
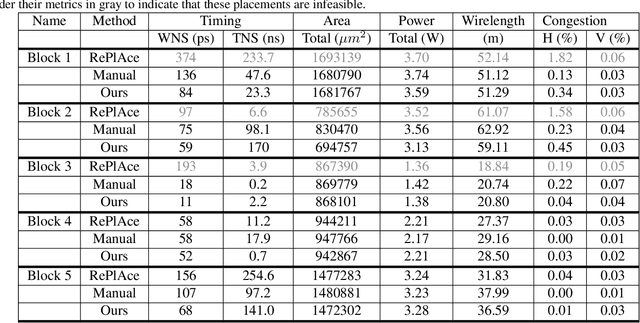
In this work, we present a learning-based approach to chip placement, one of the most complex and time-consuming stages of the chip design process. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of chip blocks, our method becomes better at rapidly generating optimized placements for previously unseen chip blocks. To achieve these results, we pose placement as a Reinforcement Learning (RL) problem and train an agent to place the nodes of a chip netlist onto a chip canvas. To enable our RL policy to generalize to unseen blocks, we ground representation learning in the supervised task of predicting placement quality. By designing a neural architecture that can accurately predict reward across a wide variety of netlists and their placements, we are able to generate rich feature embeddings of the input netlists. We then use this architecture as the encoder of our policy and value networks to enable transfer learning. Our objective is to minimize PPA (power, performance, and area), and we show that, in under 6 hours, our method can generate placements that are superhuman or comparable on modern accelerator netlists, whereas existing baselines require human experts in the loop and take several weeks.