 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Initialization-Accelerated CPU-GPU Hybrid Combinatorial Scheduling
Mar 30, 2026This paper presents a hybrid CPU-GPU framework for solving combinatorial scheduling problems formulated as Integer Linear Programming (ILP). While scheduling underpins many optimization tasks in computing systems, solving these problems optimally at scale remains a long-standing challenge due to their NP-hard nature. We introduce a novel approach that combines differentiable optimization with classical ILP solving. Specifically, we utilize differentiable presolving to rapidly generate high-quality partial solutions, which serve as warm-starts for commercial ILP solvers (CPLEX, Gurobi) and rising open-source solver HiGHS. This method enables significantly improved early pruning compared to state-of-the-art standalone solvers. Empirical results across industry-scale benchmarks demonstrate up to a $10\times$ performance gain over baselines, narrowing the optimality gap to $<0.1\%$. This work represents the first demonstration of utilizing differentiable optimization to initialize exact ILP solvers for combinatorial scheduling, opening new opportunities to integrate machine learning infrastructure with classical exact optimization methods across broader domains.
GaloisSAT: Differentiable Boolean Satisfiability Solving via Finite Field Algebra
Mar 25, 2026Boolean satisfiability (SAT) problem, the first problem proven to be NP-complete, has become a fundamental challenge in computational complexity, with widespread applications in optimization and verification across many domains. Despite significant algorithmic advances over the past two decades, the performance of SAT solvers has improved at a limited pace. Notably, the 2025 competition winner shows only about a 2X improvement over the 2006 winner in SAT Competition performance after nearly 20 years of effort. This paper introduces GaloisSAT, a novel hybrid GPU-CPU SAT solver that integrates a differentiable SAT solving engine powered by modern machine learning infrastructure on GPUs, followed by a traditional CDCL-based SAT solving stage on CPUs. GaloisSAT is benchmarked against the latest versions of state-of-the-art solvers, Kissat and CaDiCaL, using the SAT Competition 2024 benchmark suite. Results demonstrate substantial improvements in the official SAT Competition metric PAR-2 (penalized average runtime with a timeout of 5,000 seconds and a penalty factor of 2). Specifically, GaloisSAT achieves an 8.41X speedup in the satisfiable category and a 1.29X speedup in the unsatisfiable category compared to the strongest baselines.
MapTune: Advancing ASIC Technology Mapping via Reinforcement Learning Guided Library Tuning
Jul 25, 2024
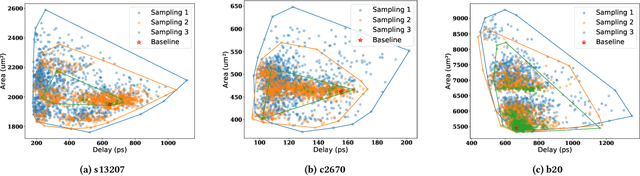
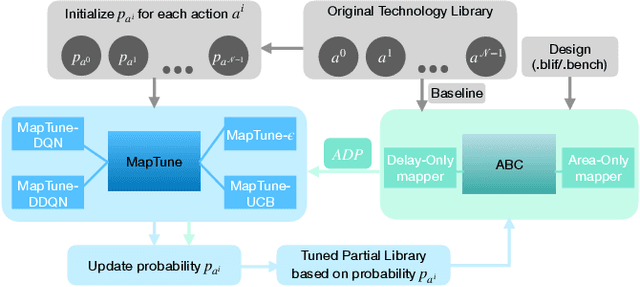
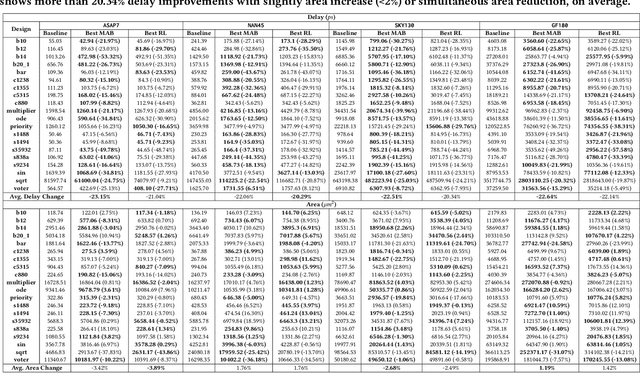
Technology mapping involves mapping logical circuits to a library of cells. Traditionally, the full technology library is used, leading to a large search space and potential overhead. Motivated by randomly sampled technology mapping case studies, we propose MapTune framework that addresses this challenge by utilizing reinforcement learning to make design-specific choices during cell selection. By learning from the environment, MapTune refines the cell selection process, resulting in a reduced search space and potentially improved mapping quality. The effectiveness of MapTune is evaluated on a wide range of benchmarks, different technology libraries and technology mappers. The experimental results demonstrate that MapTune achieves higher mapping accuracy and reducing delay/area across diverse circuit designs, technology libraries and mappers. The paper also discusses the Pareto-Optimal exploration and confirms the perpetual delay-area trade-off. Conducted on benchmark suites ISCAS 85/89, ITC/ISCAS 99, VTR8.0 and EPFL benchmarks, the post-technology mapping and post-sizing quality-of-results (QoR) have been significantly improved, with average Area-Delay Product (ADP) improvement of 22.54\% among all different exploration settings in MapTune. The improvements are consistently remained for four different technologies (7nm, 45nm, 130nm, and 180 nm) and two different mappers.
Differentiable Combinatorial Scheduling at Scale
Jun 06, 2024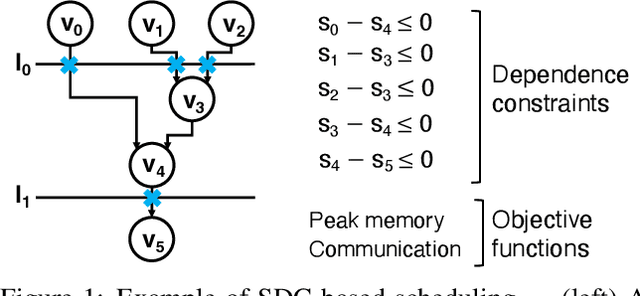
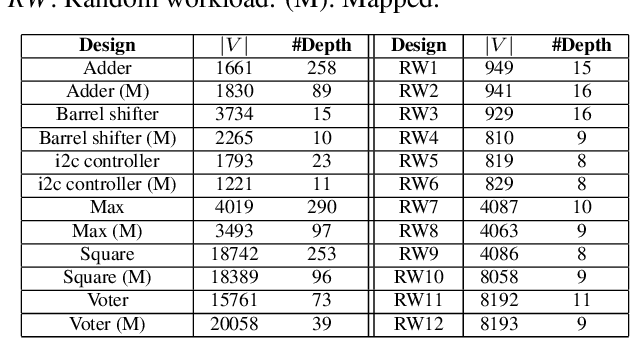
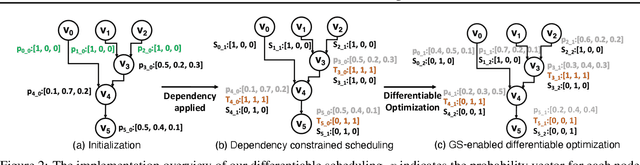
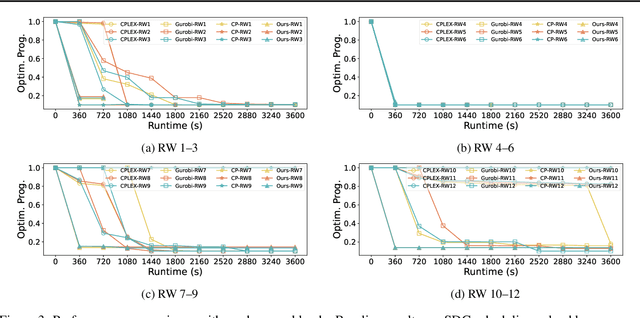
This paper addresses the complex issue of resource-constrained scheduling, an NP-hard problem that spans critical areas including chip design and high-performance computing. Traditional scheduling methods often stumble over scalability and applicability challenges. We propose a novel approach using a differentiable combinatorial scheduling framework, utilizing Gumbel-Softmax differentiable sampling technique. This new technical allows for a fully differentiable formulation of linear programming (LP) based scheduling, extending its application to a broader range of LP formulations. To encode inequality constraints for scheduling tasks, we introduce \textit{constrained Gumbel Trick}, which adeptly encodes arbitrary inequality constraints. Consequently, our method facilitates an efficient and scalable scheduling via gradient descent without the need for training data. Comparative evaluations on both synthetic and real-world benchmarks highlight our capability to significantly improve the optimization efficiency of scheduling, surpassing state-of-the-art solutions offered by commercial and open-source solvers such as CPLEX, Gurobi, and CP-SAT in the majority of the designs.
Verilog-to-PyG -- A Framework for Graph Learning and Augmentation on RTL Designs
Nov 09, 2023



The complexity of modern hardware designs necessitates advanced methodologies for optimizing and analyzing modern digital systems. In recent times, machine learning (ML) methodologies have emerged as potent instruments for assessing design quality-of-results at the Register-Transfer Level (RTL) or Boolean level, aiming to expedite design exploration of advanced RTL configurations. In this presentation, we introduce an innovative open-source framework that translates RTL designs into graph representation foundations, which can be seamlessly integrated with the PyTorch Geometric graph learning platform. Furthermore, the Verilog-to-PyG (V2PYG) framework is compatible with the open-source Electronic Design Automation (EDA) toolchain OpenROAD, facilitating the collection of labeled datasets in an utterly open-source manner. Additionally, we will present novel RTL data augmentation methods (incorporated in our framework) that enable functional equivalent design augmentation for the construction of an extensive graph-based RTL design database. Lastly, we will showcase several using cases of V2PYG with detailed scripting examples. V2PYG can be found at \url{https://yu-maryland.github.io/Verilog-to-PyG/}.