 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerilog-to-PyG -- A Framework for Graph Learning and Augmentation on RTL Designs
Nov 09, 2023



The complexity of modern hardware designs necessitates advanced methodologies for optimizing and analyzing modern digital systems. In recent times, machine learning (ML) methodologies have emerged as potent instruments for assessing design quality-of-results at the Register-Transfer Level (RTL) or Boolean level, aiming to expedite design exploration of advanced RTL configurations. In this presentation, we introduce an innovative open-source framework that translates RTL designs into graph representation foundations, which can be seamlessly integrated with the PyTorch Geometric graph learning platform. Furthermore, the Verilog-to-PyG (V2PYG) framework is compatible with the open-source Electronic Design Automation (EDA) toolchain OpenROAD, facilitating the collection of labeled datasets in an utterly open-source manner. Additionally, we will present novel RTL data augmentation methods (incorporated in our framework) that enable functional equivalent design augmentation for the construction of an extensive graph-based RTL design database. Lastly, we will showcase several using cases of V2PYG with detailed scripting examples. V2PYG can be found at \url{https://yu-maryland.github.io/Verilog-to-PyG/}.
Logic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Dec 15, 2020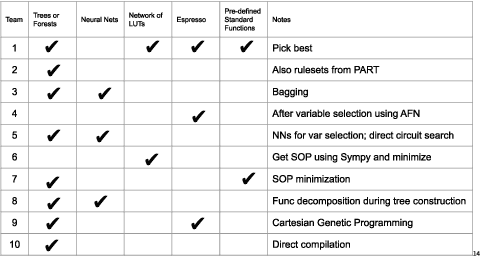
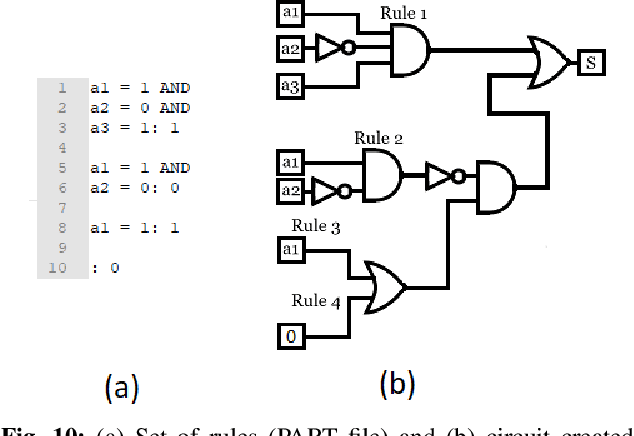
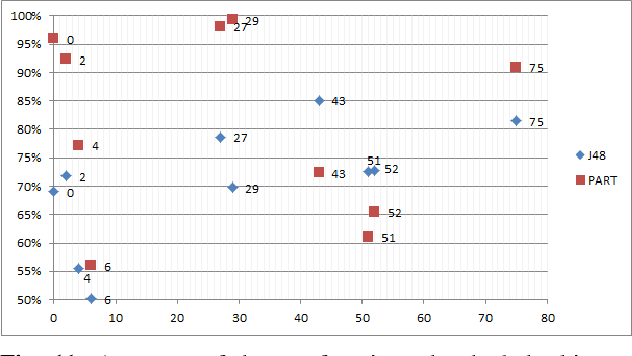
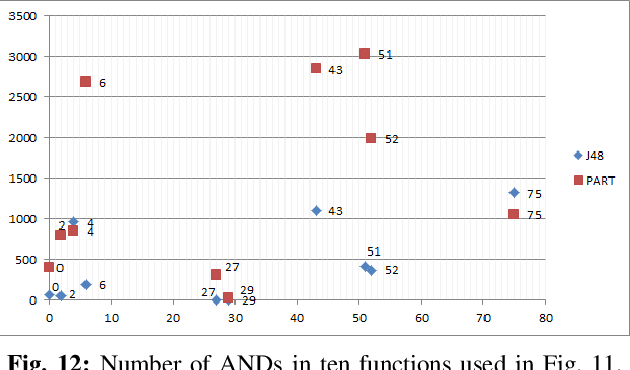
Logic synthesis is a fundamental step in hardware design whose goal is to find structural representations of Boolean functions while minimizing delay and area. If the function is completely-specified, the implementation accurately represents the function. If the function is incompletely-specified, the implementation has to be true only on the care set. While most of the algorithms in logic synthesis rely on SAT and Boolean methods to exactly implement the care set, we investigate learning in logic synthesis, attempting to trade exactness for generalization. This work is directly related to machine learning where the care set is the training set and the implementation is expected to generalize on a validation set. We present learning incompletely-specified functions based on the results of a competition conducted at IWLS 2020. The goal of the competition was to implement 100 functions given by a set of care minterms for training, while testing the implementation using a set of validation minterms sampled from the same function. We make this benchmark suite available and offer a detailed comparative analysis of the different approaches to learning
Circuit-Based Intrinsic Methods to Detect Overfitting
Jul 03, 2019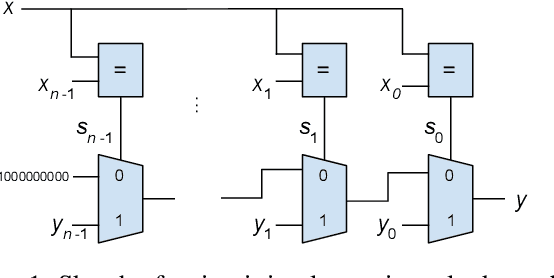
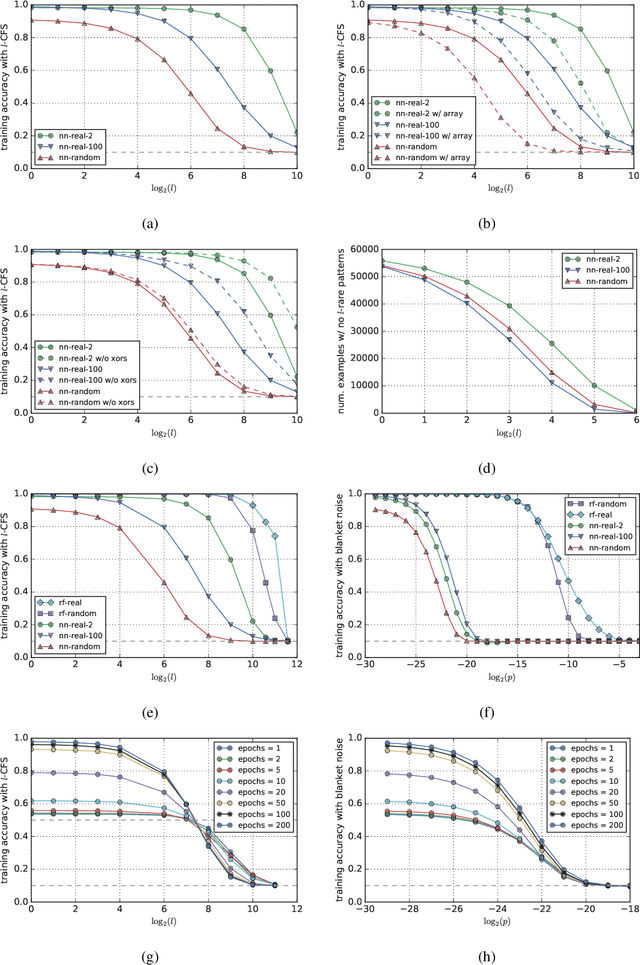
The focus of this paper is on intrinsic methods to detect overfitting. These rely only on the model and the training data, as opposed to traditional extrinsic methods that rely on performance on a test set or on bounds from model complexity. We propose a family of intrinsic methods called Counterfactual Simulation (CFS) which analyze the flow of training examples through the model by identifying and perturbing rare patterns. By applying CFS to logic circuits we get a method that has no hyper-parameters and works uniformly across different types of models such as neural networks, random forests and lookup tables. Experimentally, CFS can separate models with different levels of overfit using only their logic circuit representations without any access to the high level structure. By comparing lookup tables, neural networks, and random forests using CFS, we get insight into why neural networks generalize. In particular, we find that stochastic gradient descent in neural nets does not lead to "brute force" memorization, but finds common patterns (whether we train with actual or randomized labels), and neural networks are not unlike forests in this regard. Finally, we identify a limitation with our proposal that makes it unsuitable in an adversarial setting, but points the way to future work on robust intrinsic methods.