 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-Optical Segmentation via Diffractive Neural Networks for Autonomous Driving
Feb 07, 2026Semantic segmentation and lane detection are crucial tasks in autonomous driving systems. Conventional approaches predominantly rely on deep neural networks (DNNs), which incur high energy costs due to extensive analog-to-digital conversions and large-scale image computations required for low-latency, real-time responses. Diffractive optical neural networks (DONNs) have shown promising advantages over conventional DNNs on digital or optoelectronic computing platforms in energy efficiency. By performing all-optical image processing via light diffraction at the speed of light, DONNs save computation energy costs while reducing the overhead associated with analog-to-digital conversions by all-optical encoding and computing. In this work, we propose a novel all-optical computing framework for RGB image segmentation and lane detection in autonomous driving applications. Our experimental results demonstrate the effectiveness of the DONN system for image segmentation on the CityScapes dataset. Additionally, we conduct case studies on lane detection using a customized indoor track dataset and simulated driving scenarios in CARLA, where we further evaluate the model's generalizability under diverse environmental conditions.
MapTune: Advancing ASIC Technology Mapping via Reinforcement Learning Guided Library Tuning
Jul 25, 2024
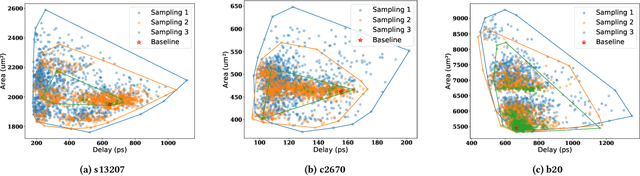
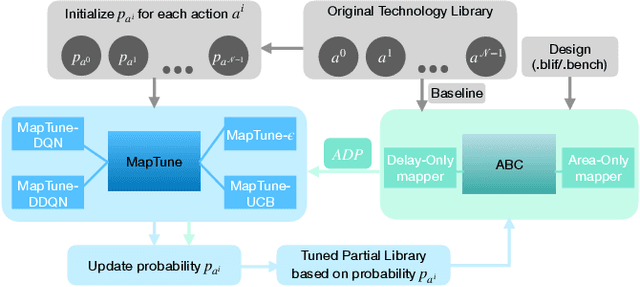
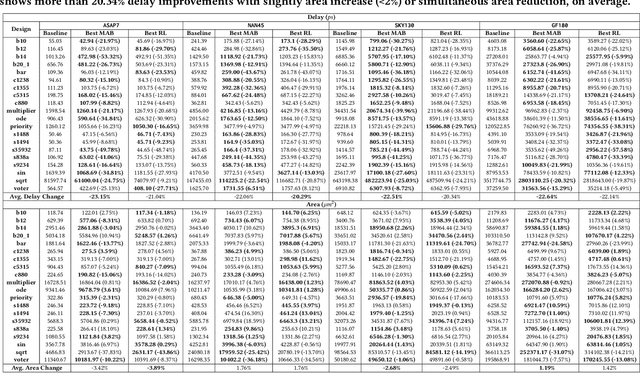
Technology mapping involves mapping logical circuits to a library of cells. Traditionally, the full technology library is used, leading to a large search space and potential overhead. Motivated by randomly sampled technology mapping case studies, we propose MapTune framework that addresses this challenge by utilizing reinforcement learning to make design-specific choices during cell selection. By learning from the environment, MapTune refines the cell selection process, resulting in a reduced search space and potentially improved mapping quality. The effectiveness of MapTune is evaluated on a wide range of benchmarks, different technology libraries and technology mappers. The experimental results demonstrate that MapTune achieves higher mapping accuracy and reducing delay/area across diverse circuit designs, technology libraries and mappers. The paper also discusses the Pareto-Optimal exploration and confirms the perpetual delay-area trade-off. Conducted on benchmark suites ISCAS 85/89, ITC/ISCAS 99, VTR8.0 and EPFL benchmarks, the post-technology mapping and post-sizing quality-of-results (QoR) have been significantly improved, with average Area-Delay Product (ADP) improvement of 22.54\% among all different exploration settings in MapTune. The improvements are consistently remained for four different technologies (7nm, 45nm, 130nm, and 180 nm) and two different mappers.
RESPECT: Reinforcement Learning based Edge Scheduling on Pipelined Coral Edge TPUs
Apr 10, 2023



Deep neural networks (DNNs) have substantial computational and memory requirements, and the compilation of its computational graphs has a great impact on the performance of resource-constrained (e.g., computation, I/O, and memory-bound) edge computing systems. While efficient execution of their computational graph requires an effective scheduling algorithm, generating the optimal scheduling solution is a challenging NP-hard problem. Furthermore, the complexity of scheduling DNN computational graphs will further increase on pipelined multi-core systems considering memory communication cost, as well as the increasing size of DNNs. Using the synthetic graph for the training dataset, this work presents a reinforcement learning (RL) based scheduling framework RESPECT, which learns the behaviors of optimal optimization algorithms and generates near-optimal scheduling results with short solving runtime overhead. Our framework has demonstrated up to $\sim2.5\times$ real-world on-chip inference runtime speedups over the commercial compiler with ten popular ImageNet models deployed on the physical Coral Edge TPUs system. Moreover, compared to the exact optimization methods, the proposed RL scheduling improves the scheduling optimization runtime by up to 683$\times$ speedups compared to the commercial compiler and matches the exact optimal solutions with up to 930$\times$ speedups. Finally, we perform a comprehensive generalizability test, which demonstrates RESPECT successfully imitates optimal solving behaviors from small synthetic graphs to large real-world DNNs computational graphs.