 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Medical Scribe: Corpus Development and Model Performance Analyses
Mar 12, 2020

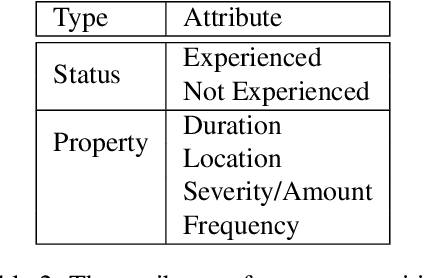
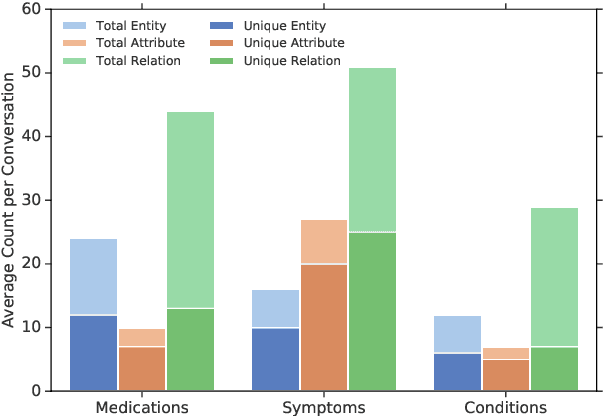
There is a growing interest in creating tools to assist in clinical note generation using the audio of provider-patient encounters. Motivated by this goal and with the help of providers and medical scribes, we developed an annotation scheme to extract relevant clinical concepts. We used this annotation scheme to label a corpus of about 6k clinical encounters. This was used to train a state-of-the-art tagging model. We report ontologies, labeling results, model performances, and detailed analyses of the results. Our results show that the entities related to medications can be extracted with a relatively high accuracy of 0.90 F-score, followed by symptoms at 0.72 F-score, and conditions at 0.57 F-score. In our task, we not only identify where the symptoms are mentioned but also map them to canonical forms as they appear in the clinical notes. Of the different types of errors, in about 19-38% of the cases, we find that the model output was correct, and about 17-32% of the errors do not impact the clinical note. Taken together, the models developed in this work are more useful than the F-scores reflect, making it a promising approach for practical applications.
* Extended version of the paper accepted at LREC 2020