 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction
Apr 16, 2024



In this report, we present the 1st place solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction. The challenge aims to evaluate approaches for novel view synthesis and surface reconstruction using only a few posed images of each object. We utilize Pixel-NeRF as the basic model, and apply depth supervision as well as coarse-to-fine positional encoding. The experiments demonstrate the effectiveness of our approach in improving sparse-view reconstruction quality. We ranked first in the final test with a PSNR of 25.44614.
Arbitrary-Scale Point Cloud Upsampling by Voxel-Based Network with Latent Geometric-Consistent Learning
Mar 08, 2024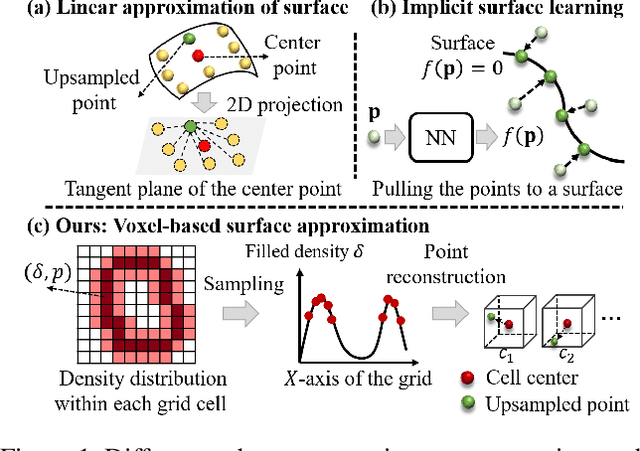
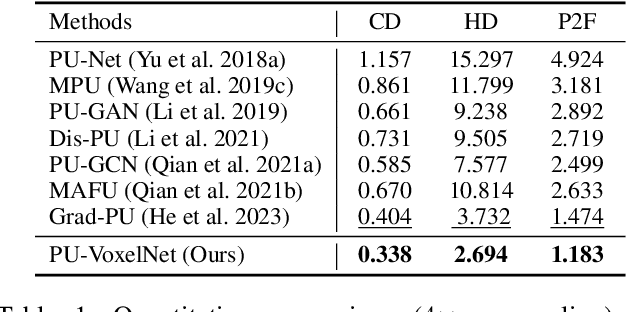
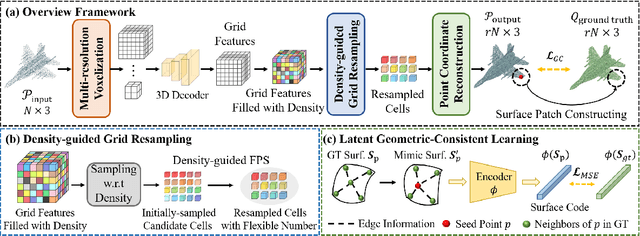
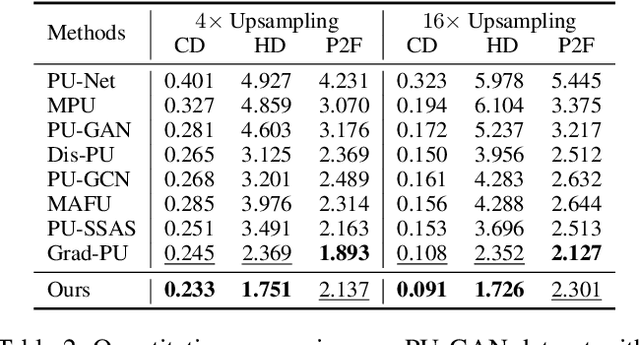
Recently, arbitrary-scale point cloud upsampling mechanism became increasingly popular due to its efficiency and convenience for practical applications. To achieve this, most previous approaches formulate it as a problem of surface approximation and employ point-based networks to learn surface representations. However, learning surfaces from sparse point clouds is more challenging, and thus they often suffer from the low-fidelity geometry approximation. To address it, we propose an arbitrary-scale Point cloud Upsampling framework using Voxel-based Network (\textbf{PU-VoxelNet}). Thanks to the completeness and regularity inherited from the voxel representation, voxel-based networks are capable of providing predefined grid space to approximate 3D surface, and an arbitrary number of points can be reconstructed according to the predicted density distribution within each grid cell. However, we investigate the inaccurate grid sampling caused by imprecise density predictions. To address this issue, a density-guided grid resampling method is developed to generate high-fidelity points while effectively avoiding sampling outliers. Further, to improve the fine-grained details, we present an auxiliary training supervision to enforce the latent geometric consistency among local surface patches. Extensive experiments indicate the proposed approach outperforms the state-of-the-art approaches not only in terms of fixed upsampling rates but also for arbitrary-scale upsampling.
Rethinking the Approximation Error in 3D Surface Fitting for Point Cloud Normal Estimation
Mar 30, 2023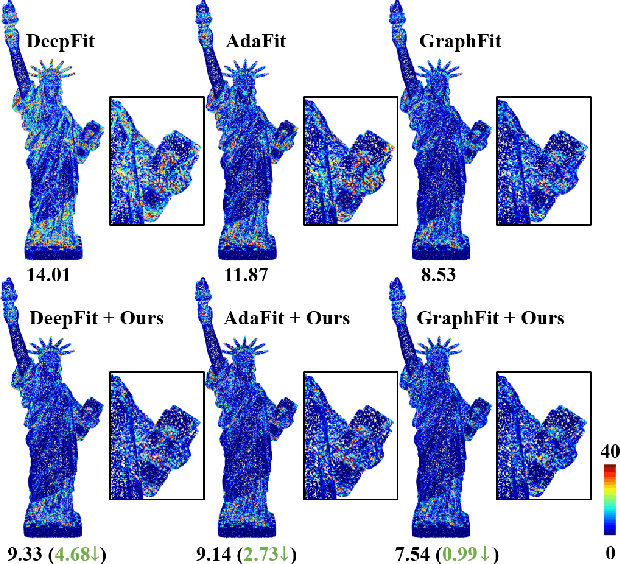
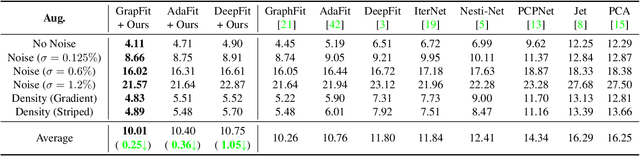
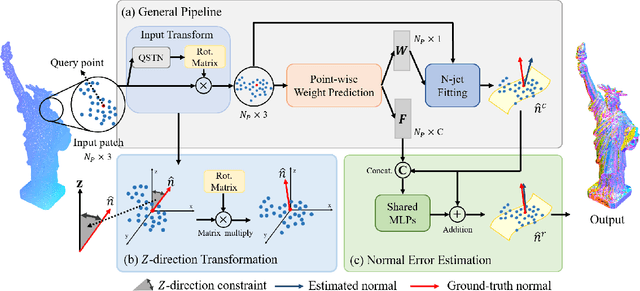
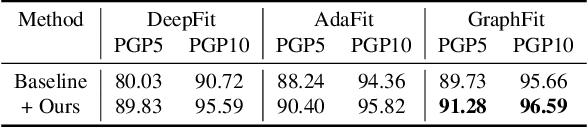
Most existing approaches for point cloud normal estimation aim to locally fit a geometric surface and calculate the normal from the fitted surface. Recently, learning-based methods have adopted a routine of predicting point-wise weights to solve the weighted least-squares surface fitting problem. Despite achieving remarkable progress, these methods overlook the approximation error of the fitting problem, resulting in a less accurate fitted surface. In this paper, we first carry out in-depth analysis of the approximation error in the surface fitting problem. Then, in order to bridge the gap between estimated and precise surface normals, we present two basic design principles: 1) applies the $Z$-direction Transform to rotate local patches for a better surface fitting with a lower approximation error; 2) models the error of the normal estimation as a learnable term. We implement these two principles using deep neural networks, and integrate them with the state-of-the-art (SOTA) normal estimation methods in a plug-and-play manner. Extensive experiments verify our approaches bring benefits to point cloud normal estimation and push the frontier of state-of-the-art performance on both synthetic and real-world datasets.
Point Cloud Upsampling via Cascaded Refinement Network
Oct 08, 2022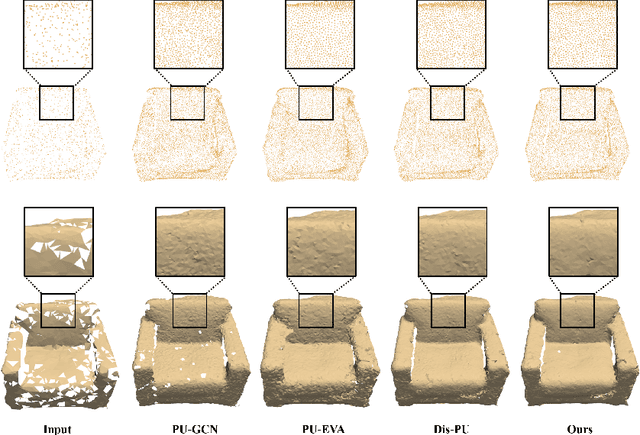
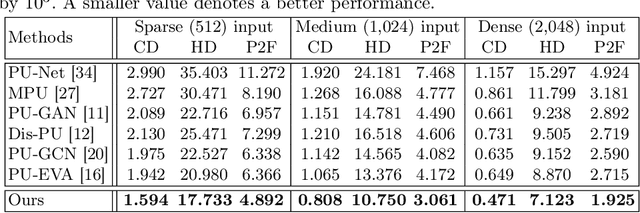
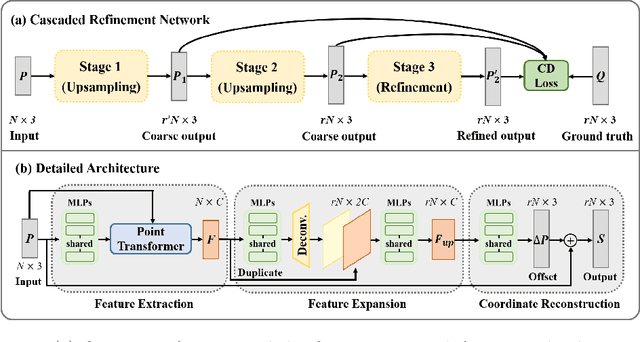
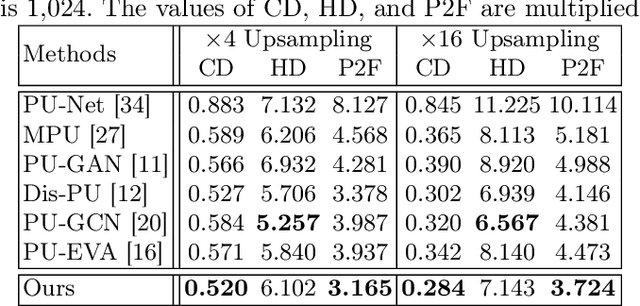
Point cloud upsampling focuses on generating a dense, uniform and proximity-to-surface point set. Most previous approaches accomplish these objectives by carefully designing a single-stage network, which makes it still challenging to generate a high-fidelity point distribution. Instead, upsampling point cloud in a coarse-to-fine manner is a decent solution. However, existing coarse-to-fine upsampling methods require extra training strategies, which are complicated and time-consuming during the training. In this paper, we propose a simple yet effective cascaded refinement network, consisting of three generation stages that have the same network architecture but achieve different objectives. Specifically, the first two upsampling stages generate the dense but coarse points progressively, while the last refinement stage further adjust the coarse points to a better position. To mitigate the learning conflicts between multiple stages and decrease the difficulty of regressing new points, we encourage each stage to predict the point offsets with respect to the input shape. In this manner, the proposed cascaded refinement network can be easily optimized without extra learning strategies. Moreover, we design a transformer-based feature extraction module to learn the informative global and local shape context. In inference phase, we can dynamically adjust the model efficiency and effectiveness, depending on the available computational resources. Extensive experiments on both synthetic and real-scanned datasets demonstrate that the proposed approach outperforms the existing state-of-the-art methods.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022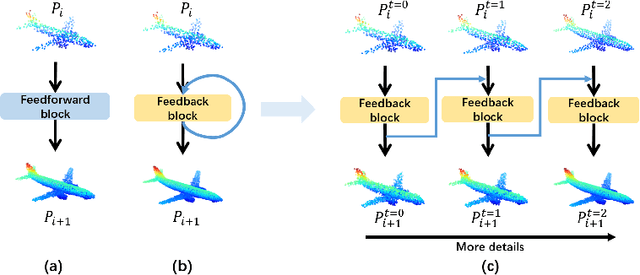
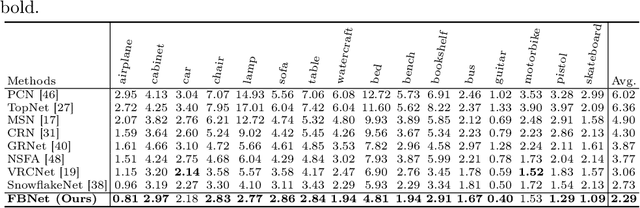
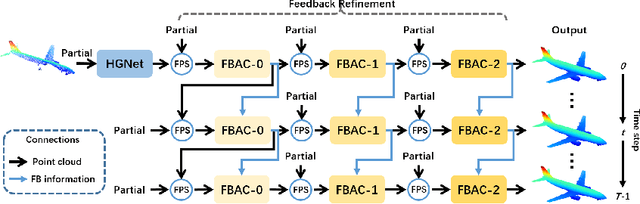
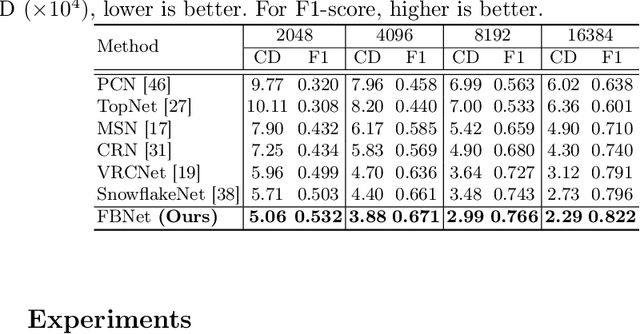
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.