 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze Label Alignment: Alleviating Domain Shift for Gaze Estimation
Dec 20, 2024Gaze estimation methods encounter significant performance deterioration when being evaluated across different domains, because of the domain gap between the testing and training data. Existing methods try to solve this issue by reducing the deviation of data distribution, however, they ignore the existence of label deviation in the data due to the acquisition mechanism of the gaze label and the individual physiological differences. In this paper, we first point out that the influence brought by the label deviation cannot be ignored, and propose a gaze label alignment algorithm (GLA) to eliminate the label distribution deviation. Specifically, we first train the feature extractor on all domains to get domain invariant features, and then select an anchor domain to train the gaze regressor. We predict the gaze label on remaining domains and use a mapping function to align the labels. Finally, these aligned labels can be used to train gaze estimation models. Therefore, our method can be combined with any existing method. Experimental results show that our GLA method can effectively alleviate the label distribution shift, and SOTA gaze estimation methods can be further improved obviously.
LG-Gaze: Learning Geometry-aware Continuous Prompts for Language-Guided Gaze Estimation
Nov 13, 2024The ability of gaze estimation models to generalize is often significantly hindered by various factors unrelated to gaze, especially when the training dataset is limited. Current strategies aim to address this challenge through different domain generalization techniques, yet they have had limited success due to the risk of overfitting when solely relying on value labels for regression. Recent progress in pre-trained vision-language models has motivated us to capitalize on the abundant semantic information available. We propose a novel approach in this paper, reframing the gaze estimation task as a vision-language alignment issue. Our proposed framework, named Language-Guided Gaze Estimation (LG-Gaze), learns continuous and geometry-sensitive features for gaze estimation benefit from the rich prior knowledges of vision-language models. Specifically, LG-Gaze aligns gaze features with continuous linguistic features through our proposed multimodal contrastive regression loss, which customizes adaptive weights for different negative samples. Furthermore, to better adapt to the labels for gaze estimation task, we propose a geometry-aware interpolation method to obtain more precise gaze embeddings. Through extensive experiments, we validate the efficacy of our framework in four different cross-domain evaluation tasks.
CLIP-Gaze: Towards General Gaze Estimation via Visual-Linguistic Model
Mar 08, 2024Gaze estimation methods often experience significant performance degradation when evaluated across different domains, due to the domain gap between the testing and training data. Existing methods try to address this issue using various domain generalization approaches, but with little success because of the limited diversity of gaze datasets, such as appearance, wearable, and image quality. To overcome these limitations, we propose a novel framework called CLIP-Gaze that utilizes a pre-trained vision-language model to leverage its transferable knowledge. Our framework is the first to leverage the vision-and-language cross-modality approach for gaze estimation task. Specifically, we extract gaze-relevant feature by pushing it away from gaze-irrelevant features which can be flexibly constructed via language descriptions. To learn more suitable prompts, we propose a personalized context optimization method for text prompt tuning. Furthermore, we utilize the relationship among gaze samples to refine the distribution of gaze-relevant features, thereby improving the generalization capability of the gaze estimation model. Extensive experiments demonstrate the excellent performance of CLIP-Gaze over existing methods on four cross-domain evaluations.
NeRF-Gaze: A Head-Eye Redirection Parametric Model for Gaze Estimation
Dec 30, 2022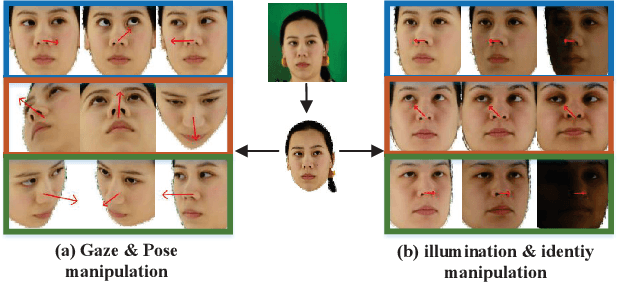
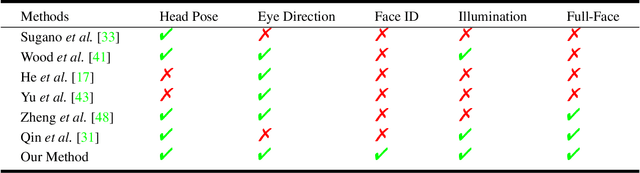
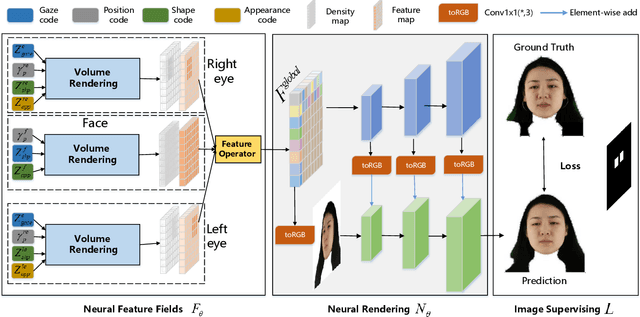

Gaze estimation is the fundamental basis for many visual tasks. Yet, the high cost of acquiring gaze datasets with 3D annotations hinders the optimization and application of gaze estimation models. In this work, we propose a novel Head-Eye redirection parametric model based on Neural Radiance Field, which allows dense gaze data generation with view consistency and accurate gaze direction. Moreover, our head-eye redirection parametric model can decouple the face and eyes for separate neural rendering, so it can achieve the purpose of separately controlling the attributes of the face, identity, illumination, and eye gaze direction. Thus diverse 3D-aware gaze datasets could be obtained by manipulating the latent code belonging to different face attributions in an unsupervised manner. Extensive experiments on several benchmarks demonstrate the effectiveness of our method in domain generalization and domain adaptation for gaze estimation tasks.