 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution for ECCV 2022 OOD-CV Challenge Image Classification Track
Jan 12, 2023OOD-CV challenge is an out-of-distribution generalization task. In this challenge, our core solution can be summarized as that Noisy Label Learning Is A Strong Test-Time Domain Adaptation Optimizer. Briefly speaking, our main pipeline can be divided into two stages, a pre-training stage for domain generalization and a test-time training stage for domain adaptation. We only exploit labeled source data in the pre-training stage and only exploit unlabeled target data in the test-time training stage. In the pre-training stage, we propose a simple yet effective Mask-Level Copy-Paste data augmentation strategy to enhance out-of-distribution generalization ability so as to resist shape, pose, context, texture, occlusion, and weather domain shifts in this challenge. In the test-time training stage, we use the pre-trained model to assign noisy label for the unlabeled target data, and propose a Label-Periodically-Updated DivideMix method for noisy label learning. After integrating Test-Time Augmentation and Model Ensemble strategies, our solution ranks the first place on the Image Classification Leaderboard of the OOD-CV Challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
2nd Place Solution for ICCV 2021 VIPriors Image Classification Challenge: An Attract-and-Repulse Learning Approach
Jun 13, 2022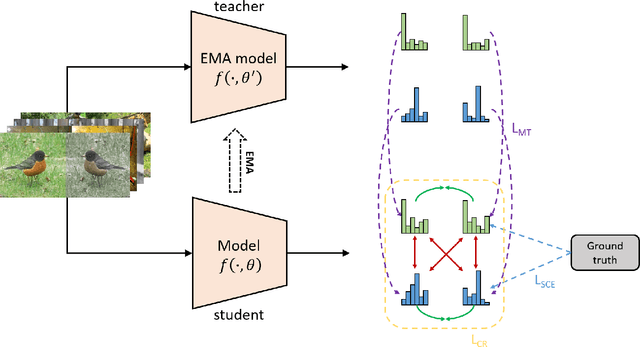

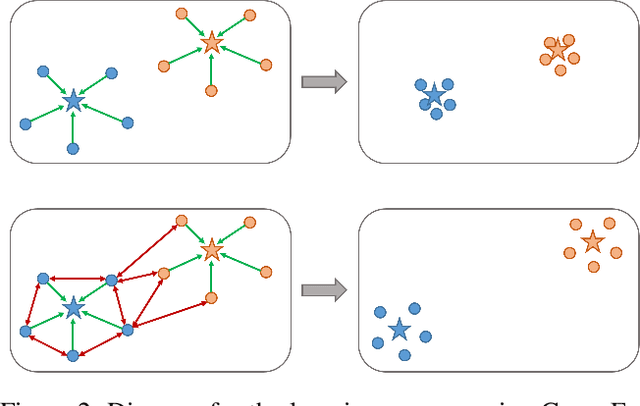

Convolutional neural networks (CNNs) have achieved significant success in image classification by utilizing large-scale datasets. However, it is still of great challenge to learn from scratch on small-scale datasets efficiently and effectively. With limited training datasets, the concepts of categories will be ambiguous since the over-parameterized CNNs tend to simply memorize the dataset, leading to poor generalization capacity. Therefore, it is crucial to study how to learn more discriminative representations while avoiding over-fitting. Since the concepts of categories tend to be ambiguous, it is important to catch more individual-wise information. Thus, we propose a new framework, termed Attract-and-Repulse, which consists of Contrastive Regularization (CR) to enrich the feature representations, Symmetric Cross Entropy (SCE) to balance the fitting for different classes and Mean Teacher to calibrate label information. Specifically, SCE and CR learn discriminative representations while alleviating over-fitting by the adaptive trade-off between the information of classes (attract) and instances (repulse). After that, Mean Teacher is used to further improve the performance via calibrating more accurate soft pseudo labels. Sufficient experiments validate the effectiveness of the Attract-and-Repulse framework. Together with other strategies, such as aggressive data augmentation, TenCrop inference, and models ensembling, we achieve the second place in ICCV 2021 VIPriors Image Classification Challenge.
Box Re-Ranking: Unsupervised False Positive Suppression for Domain Adaptive Pedestrian Detection
Feb 01, 2021
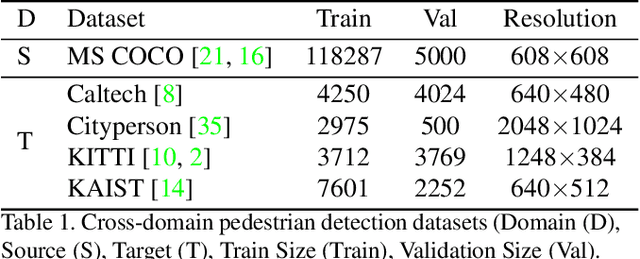
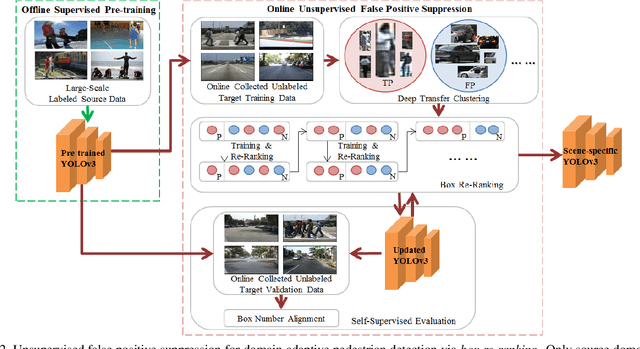
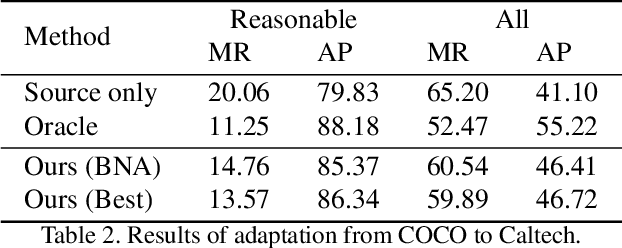
False positive is one of the most serious problems brought by agnostic domain shift in domain adaptive pedestrian detection. However, it is impossible to label each box in countless target domains. Therefore, it yields our attention to suppress false positive in each target domain in an unsupervised way. In this paper, we model an object detection task into a ranking task among positive and negative boxes innovatively, and thus transform a false positive suppression problem into a box re-ranking problem elegantly, which makes it feasible to solve without manual annotation. An attached problem during box re-ranking appears that no labeled validation data is available for cherrypicking. Considering we aim to keep the detection of true positive unchanged, we propose box number alignment, a self-supervised evaluation metric, to prevent the optimized model from capacity degeneration. Extensive experiments conducted on cross-domain pedestrian detection datasets have demonstrated the effectiveness of our proposed framework. Furthermore, the extension to two general unsupervised domain adaptive object detection benchmarks also supports our superiority to other state-of-the-arts.
Unsupervised Image Classification for Deep Representation Learning
Jun 20, 2020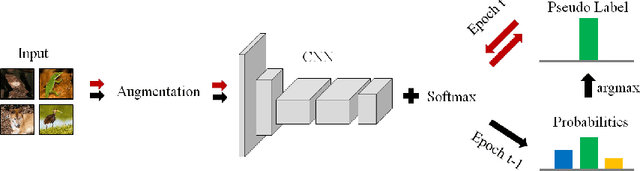
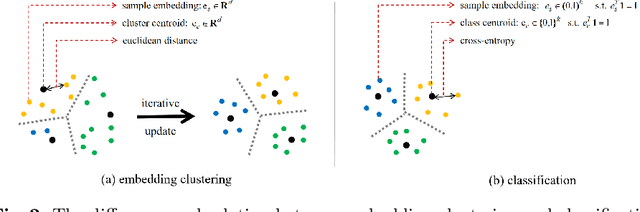
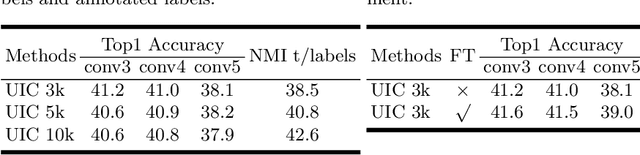

Deep clustering against self-supervised learning is a very important and promising direction for unsupervised visual representation learning since it requires little domain knowledge to design pretext tasks. However, the key component, embedding clustering, limits its extension to the extremely large-scale dataset due to its prerequisite to save the global latent embedding of the entire dataset. In this work, we aim to make this framework more simple and elegant without performance decline. We propose an unsupervised image classification framework without using embedding clustering, which is very similar to standard supervised training manner. For detailed interpretation, we further analyze its relation with deep clustering and contrastive learning. Extensive experiments on ImageNet dataset have been conducted to prove the effectiveness of our method. Furthermore, the experiments on transfer learning benchmarks have verified its generalization to other downstream tasks, including multi-label image classification, object detection, semantic segmentation and few-shot image classification.
Deep Differentiable Random Forests for Age Estimation
Aug 22, 2019
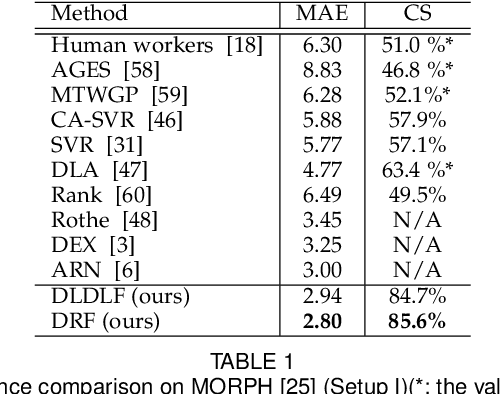
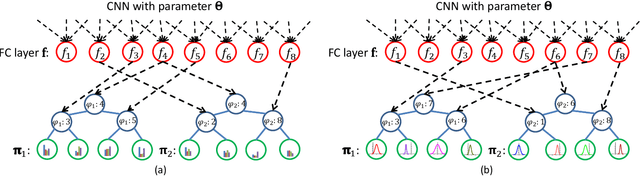
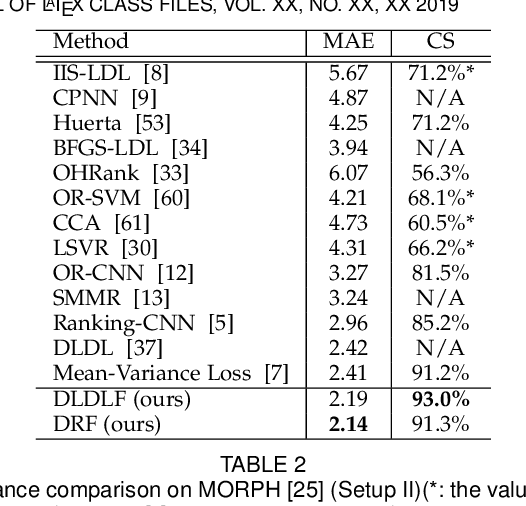
Age estimation from facial images is typically cast as a label distribution learning or regression problem, since aging is a gradual progress. Its main challenge is the facial feature space w.r.t. ages is inhomogeneous, due to the large variation in facial appearance across different persons of the same age and the non-stationary property of aging. In this paper, we propose two Deep Differentiable Random Forests methods, Deep Label Distribution Learning Forest (DLDLF) and Deep Regression Forest (DRF), for age estimation. Both of them connect split nodes to the top layer of convolutional neural networks (CNNs) and deal with inhomogeneous data by jointly learning input-dependent data partitions at the split nodes and age distributions at the leaf nodes. This joint learning follows an alternating strategy: (1) Fixing the leaf nodes and optimizing the split nodes and the CNN parameters by Back-propagation; (2) Fixing the split nodes and optimizing the leaf nodes by Variational Bounding. Two Deterministic Annealing processes are introduced into the learning of the split and leaf nodes, respectively, to avoid poor local optima and obtain better estimates of tree parameters free of initial values. Experimental results show that DLDLF and DRF achieve state-of-the-art performance on three age estimation datasets.
Deep Regression Forests for Age Estimation
Dec 19, 2017
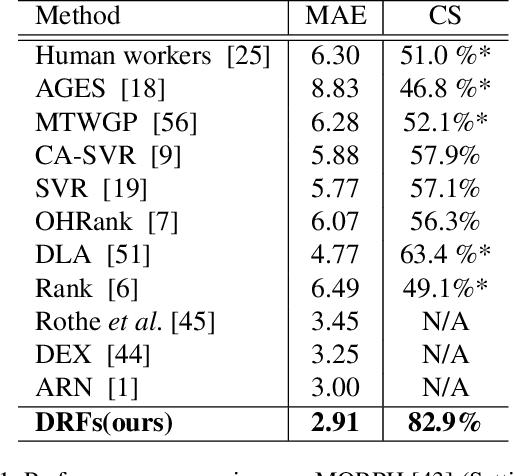
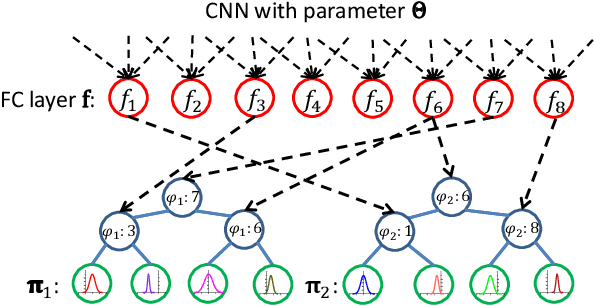
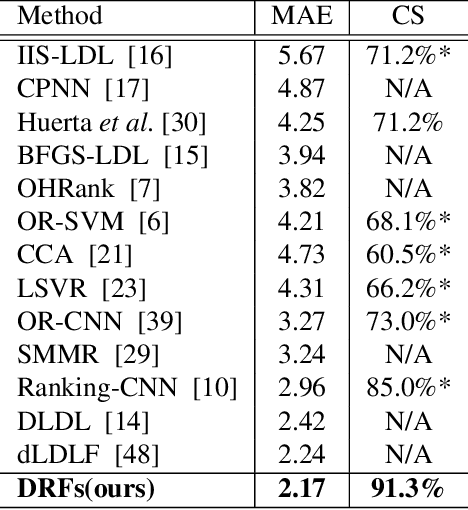
Age estimation from facial images is typically cast as a nonlinear regression problem. The main challenge of this problem is the facial feature space w.r.t. ages is heterogeneous, due to the large variation in facial appearance across different persons of the same age and the non-stationary property of aging patterns. In this paper, we propose Deep Regression Forests (DRFs), an end-to-end model, for age estimation. DRFs connect the split nodes to a fully connected layer of a convolutional neural network (CNN) and deal with heterogeneous data by jointly learning input-dependant data partitions at the split nodes and data abstractions at the leaf nodes. This joint learning follows an alternating strategy: First, by fixing the leaf nodes, the split nodes as well as the CNN parameters are optimized by Back-propagation; Then, by fixing the split nodes, the leaf nodes are optimized by iterating a step-size free and fast-converging update rule derived from Variational Bounding. We verify the proposed DRFs on three standard age estimation benchmarks and achieve state-of-the-art results on all of them.
Label Distribution Learning Forests
Oct 16, 2017

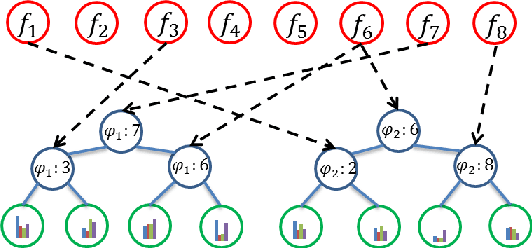

Label distribution learning (LDL) is a general learning framework, which assigns to an instance a distribution over a set of labels rather than a single label or multiple labels. Current LDL methods have either restricted assumptions on the expression form of the label distribution or limitations in representation learning, e.g., to learn deep features in an end-to-end manner. This paper presents label distribution learning forests (LDLFs) - a novel label distribution learning algorithm based on differentiable decision trees, which have several advantages: 1) Decision trees have the potential to model any general form of label distributions by a mixture of leaf node predictions. 2) The learning of differentiable decision trees can be combined with representation learning. We define a distribution-based loss function for a forest, enabling all the trees to be learned jointly, and show that an update function for leaf node predictions, which guarantees a strict decrease of the loss function, can be derived by variational bounding. The effectiveness of the proposed LDLFs is verified on several LDL tasks and a computer vision application, showing significant improvements to the state-of-the-art LDL methods.