 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaRec: Adaptive Sequential Recommendation for Reinforcing Long-term User Engagement
Paper and Code
Oct 06, 2023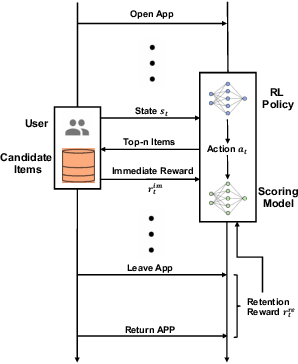
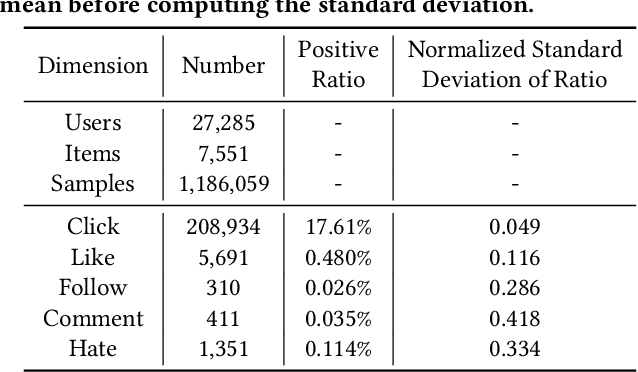
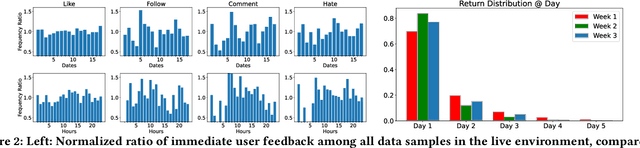
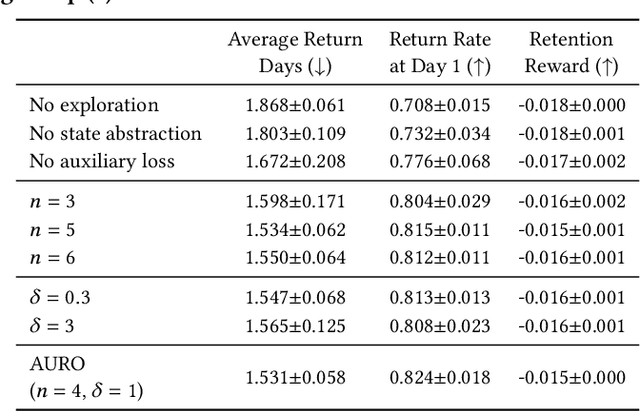
Growing attention has been paid to Reinforcement Learning (RL) algorithms when optimizing long-term user engagement in sequential recommendation tasks. One challenge in large-scale online recommendation systems is the constant and complicated changes in users' behavior patterns, such as interaction rates and retention tendencies. When formulated as a Markov Decision Process (MDP), the dynamics and reward functions of the recommendation system are continuously affected by these changes. Existing RL algorithms for recommendation systems will suffer from distribution shift and struggle to adapt in such an MDP. In this paper, we introduce a novel paradigm called Adaptive Sequential Recommendation (AdaRec) to address this issue. AdaRec proposes a new distance-based representation loss to extract latent information from users' interaction trajectories. Such information reflects how RL policy fits to current user behavior patterns, and helps the policy to identify subtle changes in the recommendation system. To make rapid adaptation to these changes, AdaRec encourages exploration with the idea of optimism under uncertainty. The exploration is further guarded by zero-order action optimization to ensure stable recommendation quality in complicated environments. We conduct extensive empirical analyses in both simulator-based and live sequential recommendation tasks, where AdaRec exhibits superior long-term performance compared to all baseline algorithms.