 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUBATrack: Spatio-Temporal State Space Model for General Multi-Modal Tracking
Jan 21, 2026Multi-modal object tracking has attracted considerable attention by integrating multiple complementary inputs (e.g., thermal, depth, and event data) to achieve outstanding performance. Although current general-purpose multi-modal trackers primarily unify various modal tracking tasks (i.e., RGB-Thermal infrared, RGB-Depth or RGB-Event tracking) through prompt learning, they still overlook the effective capture of spatio-temporal cues. In this work, we introduce a novel multi-modal tracking framework based on a mamba-style state space model, termed UBATrack. Our UBATrack comprises two simple yet effective modules: a Spatio-temporal Mamba Adapter (STMA) and a Dynamic Multi-modal Feature Mixer. The former leverages Mamba's long-sequence modeling capability to jointly model cross-modal dependencies and spatio-temporal visual cues in an adapter-tuning manner. The latter further enhances multi-modal representation capacity across multiple feature dimensions to improve tracking robustness. In this way, UBATrack eliminates the need for costly full-parameter fine-tuning, thereby improving the training efficiency of multi-modal tracking algorithms. Experiments show that UBATrack outperforms state-of-the-art methods on RGB-T, RGB-D, and RGB-E tracking benchmarks, achieving outstanding results on the LasHeR, RGBT234, RGBT210, DepthTrack, VOT-RGBD22, and VisEvent datasets.
Towards Universal Modal Tracking with Online Dense Temporal Token Learning
Jul 27, 2025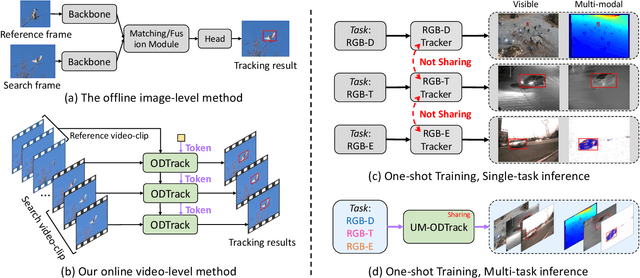


We propose a universal video-level modality-awareness tracking model with online dense temporal token learning (called {\modaltracker}). It is designed to support various tracking tasks, including RGB, RGB+Thermal, RGB+Depth, and RGB+Event, utilizing the same model architecture and parameters. Specifically, our model is designed with three core goals: \textbf{Video-level Sampling}. We expand the model's inputs to a video sequence level, aiming to see a richer video context from an near-global perspective. \textbf{Video-level Association}. Furthermore, we introduce two simple yet effective online dense temporal token association mechanisms to propagate the appearance and motion trajectory information of target via a video stream manner. \textbf{Modality Scalable}. We propose two novel gated perceivers that adaptively learn cross-modal representations via a gated attention mechanism, and subsequently compress them into the same set of model parameters via a one-shot training manner for multi-task inference. This new solution brings the following benefits: (i) The purified token sequences can serve as temporal prompts for the inference in the next video frames, whereby previous information is leveraged to guide future inference. (ii) Unlike multi-modal trackers that require independent training, our one-shot training scheme not only alleviates the training burden, but also improves model representation. Extensive experiments on visible and multi-modal benchmarks show that our {\modaltracker} achieves a new \textit{SOTA} performance. The code will be available at https://github.com/GXNU-ZhongLab/ODTrack.
Similarity-Guided Layer-Adaptive Vision Transformer for UAV Tracking
Mar 09, 2025Vision transformers (ViTs) have emerged as a popular backbone for visual tracking. However, complete ViT architectures are too cumbersome to deploy for unmanned aerial vehicle (UAV) tracking which extremely emphasizes efficiency. In this study, we discover that many layers within lightweight ViT-based trackers tend to learn relatively redundant and repetitive target representations. Based on this observation, we propose a similarity-guided layer adaptation approach to optimize the structure of ViTs. Our approach dynamically disables a large number of representation-similar layers and selectively retains only a single optimal layer among them, aiming to achieve a better accuracy-speed trade-off. By incorporating this approach into existing ViTs, we tailor previously complete ViT architectures into an efficient similarity-guided layer-adaptive framework, namely SGLATrack, for real-time UAV tracking. Extensive experiments on six tracking benchmarks verify the effectiveness of the proposed approach, and show that our SGLATrack achieves a state-of-the-art real-time speed while maintaining competitive tracking precision. Codes and models are available at https://github.com/GXNU-ZhongLab/SGLATrack.
Less is More: Token Context-aware Learning for Object Tracking
Jan 01, 2025Recently, several studies have shown that utilizing contextual information to perceive target states is crucial for object tracking. They typically capture context by incorporating multiple video frames. However, these naive frame-context methods fail to consider the importance of each patch within a reference frame, making them susceptible to noise and redundant tokens, which deteriorates tracking performance. To address this challenge, we propose a new token context-aware tracking pipeline named LMTrack, designed to automatically learn high-quality reference tokens for efficient visual tracking. Embracing the principle of Less is More, the core idea of LMTrack is to analyze the importance distribution of all reference tokens, where important tokens are collected, continually attended to, and updated. Specifically, a novel Token Context Memory module is designed to dynamically collect high-quality spatio-temporal information of a target in an autoregressive manner, eliminating redundant background tokens from the reference frames. Furthermore, an effective Unidirectional Token Attention mechanism is designed to establish dependencies between reference tokens and search frame, enabling robust cross-frame association and target localization. Extensive experiments demonstrate the superiority of our tracker, achieving state-of-the-art results on tracking benchmarks such as GOT-10K, TrackingNet, and LaSOT.
ODTrack: Online Dense Temporal Token Learning for Visual Tracking
Jan 03, 2024



Online contextual reasoning and association across consecutive video frames are critical to perceive instances in visual tracking. However, most current top-performing trackers persistently lean on sparse temporal relationships between reference and search frames via an offline mode. Consequently, they can only interact independently within each image-pair and establish limited temporal correlations. To alleviate the above problem, we propose a simple, flexible and effective video-level tracking pipeline, named \textbf{ODTrack}, which densely associates the contextual relationships of video frames in an online token propagation manner. ODTrack receives video frames of arbitrary length to capture the spatio-temporal trajectory relationships of an instance, and compresses the discrimination features (localization information) of a target into a token sequence to achieve frame-to-frame association. This new solution brings the following benefits: 1) the purified token sequences can serve as prompts for the inference in the next video frame, whereby past information is leveraged to guide future inference; 2) the complex online update strategies are effectively avoided by the iterative propagation of token sequences, and thus we can achieve more efficient model representation and computation. ODTrack achieves a new \textit{SOTA} performance on seven benchmarks, while running at real-time speed. Code and models are available at \url{https://github.com/GXNU-ZhongLab/ODTrack}.
Towards Unified Token Learning for Vision-Language Tracking
Aug 27, 2023



In this paper, we present a simple, flexible and effective vision-language (VL) tracking pipeline, termed \textbf{MMTrack}, which casts VL tracking as a token generation task. Traditional paradigms address VL tracking task indirectly with sophisticated prior designs, making them over-specialize on the features of specific architectures or mechanisms. In contrast, our proposed framework serializes language description and bounding box into a sequence of discrete tokens. In this new design paradigm, all token queries are required to perceive the desired target and directly predict spatial coordinates of the target in an auto-regressive manner. The design without other prior modules avoids multiple sub-tasks learning and hand-designed loss functions, significantly reducing the complexity of VL tracking modeling and allowing our tracker to use a simple cross-entropy loss as unified optimization objective for VL tracking task. Extensive experiments on TNL2K, LaSOT, LaSOT$_{\rm{ext}}$ and OTB99-Lang benchmarks show that our approach achieves promising results, compared to other state-of-the-arts.