 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D+3D facial expression recognition via embedded tensor manifold regularization
Jan 29, 2022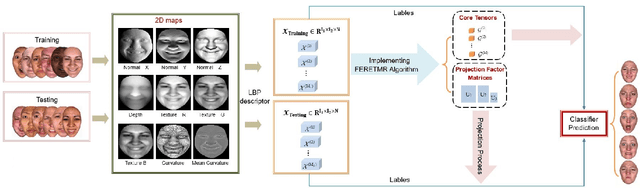
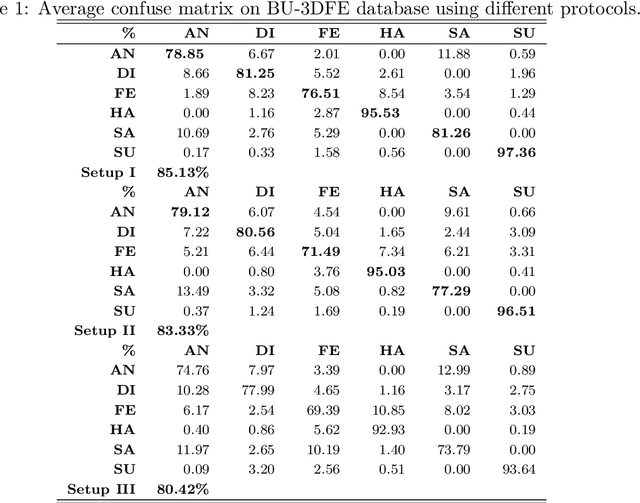
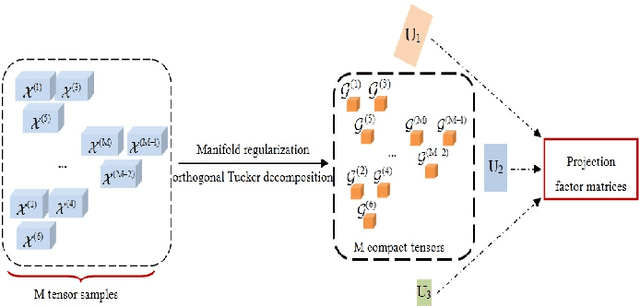
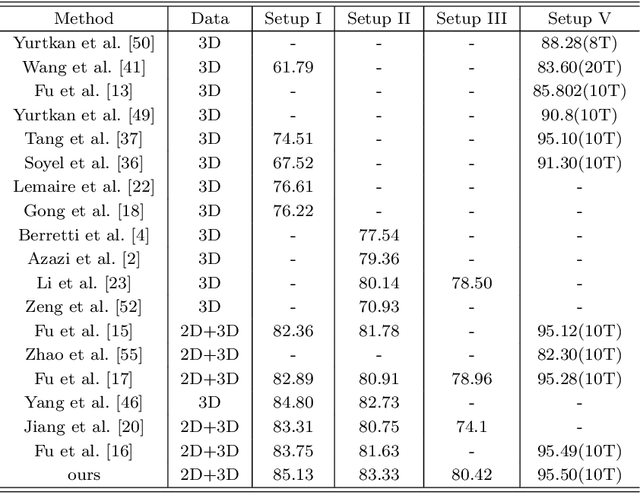
In this paper, a novel approach via embedded tensor manifold regularization for 2D+3D facial expression recognition (FERETMR) is proposed. Firstly, 3D tensors are constructed from 2D face images and 3D face shape models to keep the structural information and correlations. To maintain the local structure (geometric information) of 3D tensor samples in the low-dimensional tensors space during the dimensionality reduction, the $\ell_0$-norm of the core tensors and a tensor manifold regularization scheme embedded on core tensors are adopted via a low-rank truncated Tucker decomposition on the generated tensors. As a result, the obtained factor matrices will be used for facial expression classification prediction. To make the resulting tensor optimization more tractable, $\ell_1$-norm surrogate is employed to relax $\ell_0$-norm and hence the resulting tensor optimization problem has a nonsmooth objective function due to the $\ell_1$-norm and orthogonal constraints from the orthogonal Tucker decomposition. To efficiently tackle this tensor optimization problem, we establish the first-order optimality condition in terms of stationary points, and then design a block coordinate descent (BCD) algorithm with convergence analysis and the computational complexity. Numerical results on BU-3DFE database and Bosphorus databases demonstrate the effectiveness of our proposed approach.
Multi-Scale Context Aggregation Network with Attention-Guided for Crowd Counting
Apr 06, 2021
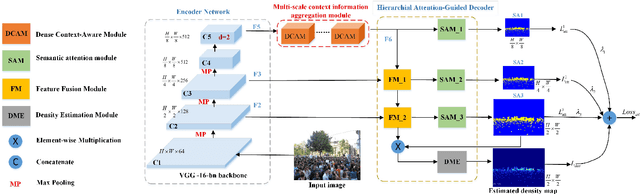
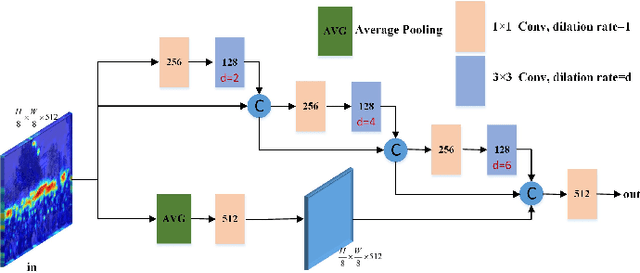
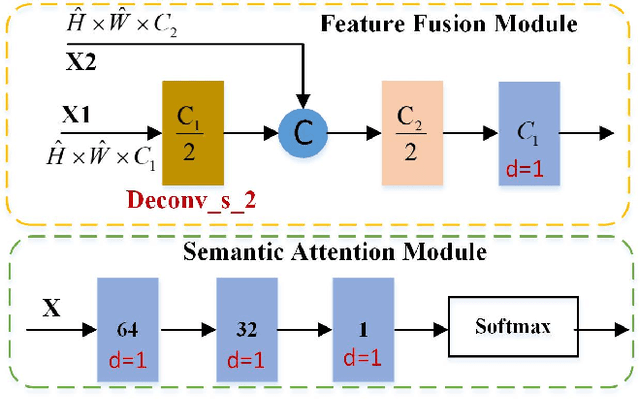
Crowd counting aims to predict the number of people and generate the density map in the image. There are many challenges, including varying head scales, the diversity of crowd distribution across images and cluttered backgrounds. In this paper, we propose a multi-scale context aggregation network (MSCANet) based on single-column encoder-decoder architecture for crowd counting, which consists of an encoder based on a dense context-aware module (DCAM) and a hierarchical attention-guided decoder. To handle the issue of scale variation, we construct the DCAM to aggregate multi-scale contextual information by densely connecting the dilated convolution with varying receptive fields. The proposed DCAM can capture rich contextual information of crowd areas due to its long-range receptive fields and dense scale sampling. Moreover, to suppress the background noise and generate a high-quality density map, we adopt a hierarchical attention-guided mechanism in the decoder. This helps to integrate more useful spatial information from shallow feature maps of the encoder by introducing multiple supervision based on semantic attention module (SAM). Extensive experiments demonstrate that the proposed approach achieves better performance than other similar state-of-the-art methods on three challenging benchmark datasets for crowd counting. The code is available at https://github.com/KingMV/MSCANet
Frustratingly Easy Person Re-Identification: Generalizing Person Re-ID in Practice
May 09, 2019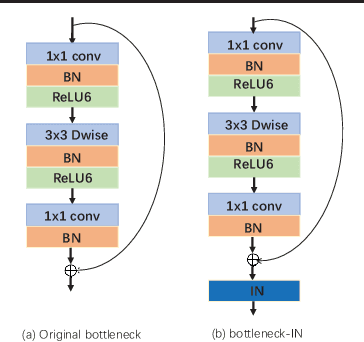

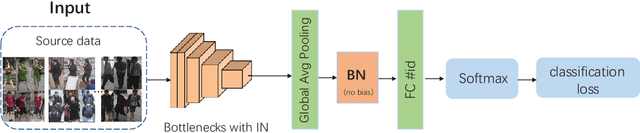
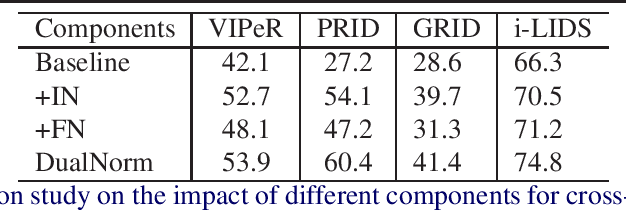
Contemporary person re-identification (Re-ID) methods usually require access to data from the deployment camera network during training in order to perform well. This is because contemporary Re-ID models trained on one dataset do not generalise to other camera networks due to the domain-shift between datasets. This requirement is often the bottleneck for deploying Re-ID systems in practical security or commercial applications as it may be impossible to collect this data in advance or prohibitively costly to annotate it. This paper alleviates this issue by proposing a simple baseline for domain generalizable~(DG) person re-identification. That is, to learn a Re-ID model from a set of source domains that is suitable for application to unseen datasets out-of-the-box, without any model updating. Specifically, we observe that the domain discrepancy in Re-ID is due to style and content variance across datasets and demonstrate appropriate Instance and Feature Normalization alleviates much of the resulting domain-shift in Deep Re-ID models. Instance Normalization~(IN) in early layers filters out style statistic variations and Feature Normalization~(FN) in deep layers is able to further eliminate disparity in content statistics. Compared to contemporary alternatives, this approach is extremely simple to implement, while being faster to train and test, thus making it an extremely valuable baseline for implementing Re-ID in practice. With a few lines of code, it increases the rank 1 Re-ID accuracy by 11.7\%, 28.9\%, 10.1\% and 6.3\% on the VIPeR, PRID, GRID, and i-LIDS benchmarks respectively. Source code will be made available.
Multi-Level Recurrent Residual Networks for Action Recognition
Jan 03, 2018



Most existing Convolutional Neural Networks(CNNs) used for action recognition are either difficult to optimize or underuse crucial temporal information. Inspired by the fact that the recurrent model consistently makes breakthroughs in the task related to sequence, we propose a novel Multi-Level Recurrent Residual Networks(MRRN) which incorporates three recognition streams. Each stream consists of a Residual Networks(ResNets) and a recurrent model. The proposed model captures spatiotemporal information by employing both alternative ResNets to learn spatial representations from static frames and stacked Simple Recurrent Units(SRUs) to model temporal dynamics. Three distinct-level streams learned low-, mid-, high-level representations independently are fused by computing a weighted average of their softmax scores to obtain the complementary representations of the video. Unlike previous models which boost performance at the cost of time complexity and space complexity, our models have a lower complexity by employing shortcut connection and are trained end-to-end with greater efficiency. MRRN displays significant performance improvements compared to CNN-RNN framework baselines and obtains comparable performance with the state-of-the-art, achieving 51.3% on HMDB-51 dataset and 81.9% on UCF-101 dataset although no additional data.