 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Context Aggregation Network with Attention-Guided for Crowd Counting
Apr 06, 2021
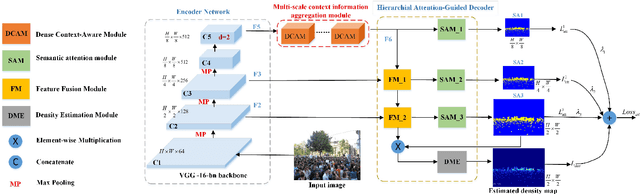
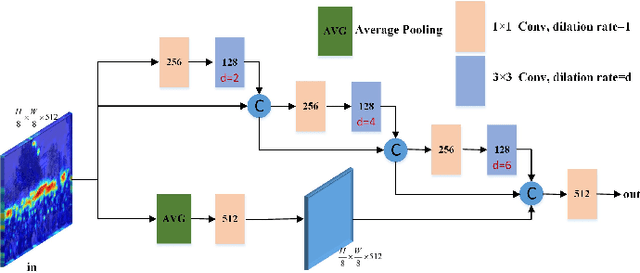
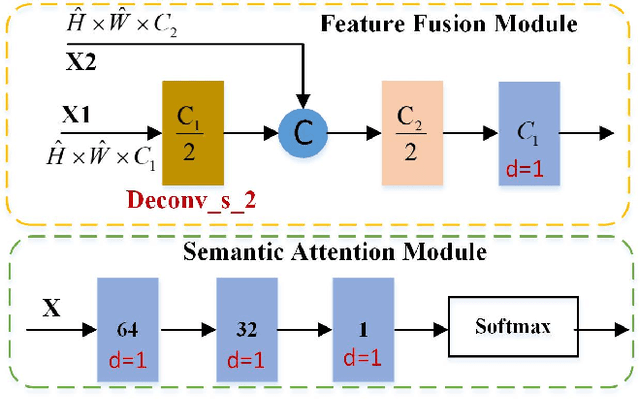
Crowd counting aims to predict the number of people and generate the density map in the image. There are many challenges, including varying head scales, the diversity of crowd distribution across images and cluttered backgrounds. In this paper, we propose a multi-scale context aggregation network (MSCANet) based on single-column encoder-decoder architecture for crowd counting, which consists of an encoder based on a dense context-aware module (DCAM) and a hierarchical attention-guided decoder. To handle the issue of scale variation, we construct the DCAM to aggregate multi-scale contextual information by densely connecting the dilated convolution with varying receptive fields. The proposed DCAM can capture rich contextual information of crowd areas due to its long-range receptive fields and dense scale sampling. Moreover, to suppress the background noise and generate a high-quality density map, we adopt a hierarchical attention-guided mechanism in the decoder. This helps to integrate more useful spatial information from shallow feature maps of the encoder by introducing multiple supervision based on semantic attention module (SAM). Extensive experiments demonstrate that the proposed approach achieves better performance than other similar state-of-the-art methods on three challenging benchmark datasets for crowd counting. The code is available at https://github.com/KingMV/MSCANet