 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOHA: Empowering Multilingual Agent for University Orientation with Hierarchical Retrieval
May 13, 2025The rise of Large Language Models~(LLMs) revolutionizes information retrieval, allowing users to obtain required answers through complex instructions within conversations. However, publicly available services remain inadequate in addressing the needs of faculty and students to search campus-specific information. It is primarily due to the LLM's lack of domain-specific knowledge and the limitation of search engines in supporting multilingual and timely scenarios. To tackle these challenges, we introduce ALOHA, a multilingual agent enhanced by hierarchical retrieval for university orientation. We also integrate external APIs into the front-end interface to provide interactive service. The human evaluation and case study show our proposed system has strong capabilities to yield correct, timely, and user-friendly responses to the queries in multiple languages, surpassing commercial chatbots and search engines. The system has been deployed and has provided service for more than 12,000 people.
D$^4$M: Dataset Distillation via Disentangled Diffusion Model
Jul 21, 2024



Dataset distillation offers a lightweight synthetic dataset for fast network training with promising test accuracy. To imitate the performance of the original dataset, most approaches employ bi-level optimization and the distillation space relies on the matching architecture. Nevertheless, these approaches either suffer significant computational costs on large-scale datasets or experience performance decline on cross-architectures. We advocate for designing an economical dataset distillation framework that is independent of the matching architectures. With empirical observations, we argue that constraining the consistency of the real and synthetic image spaces will enhance the cross-architecture generalization. Motivated by this, we introduce Dataset Distillation via Disentangled Diffusion Model (D$^4$M), an efficient framework for dataset distillation. Compared to architecture-dependent methods, D$^4$M employs latent diffusion model to guarantee consistency and incorporates label information into category prototypes. The distilled datasets are versatile, eliminating the need for repeated generation of distinct datasets for various architectures. Through comprehensive experiments, D$^4$M demonstrates superior performance and robust generalization, surpassing the SOTA methods across most aspects.
Crimson: Empowering Strategic Reasoning in Cybersecurity through Large Language Models
Mar 01, 2024



We introduces Crimson, a system that enhances the strategic reasoning capabilities of Large Language Models (LLMs) within the realm of cybersecurity. By correlating CVEs with MITRE ATT&CK techniques, Crimson advances threat anticipation and strategic defense efforts. Our approach includes defining and evaluating cybersecurity strategic tasks, alongside implementing a comprehensive human-in-the-loop data-synthetic workflow to develop the CVE-to-ATT&CK Mapping (CVEM) dataset. We further enhance LLMs' reasoning abilities through a novel Retrieval-Aware Training (RAT) process and its refined iteration, RAT-R. Our findings demonstrate that an LLM fine-tuned with our techniques, possessing 7 billion parameters, approaches the performance level of GPT-4, showing markedly lower rates of hallucination and errors, and surpassing other models in strategic reasoning tasks. Moreover, domain-specific fine-tuning of embedding models significantly improves performance within cybersecurity contexts, underscoring the efficacy of our methodology. By leveraging Crimson to convert raw vulnerability data into structured and actionable insights, we bolster proactive cybersecurity defenses.
Data-Free Generalized Zero-Shot Learning
Jan 28, 2024



Deep learning models have the ability to extract rich knowledge from large-scale datasets. However, the sharing of data has become increasingly challenging due to concerns regarding data copyright and privacy. Consequently, this hampers the effective transfer of knowledge from existing data to novel downstream tasks and concepts. Zero-shot learning (ZSL) approaches aim to recognize new classes by transferring semantic knowledge learned from base classes. However, traditional generative ZSL methods often require access to real images from base classes and rely on manually annotated attributes, which presents challenges in terms of data restrictions and model scalability. To this end, this paper tackles a challenging and practical problem dubbed as data-free zero-shot learning (DFZSL), where only the CLIP-based base classes data pre-trained classifier is available for zero-shot classification. Specifically, we propose a generic framework for DFZSL, which consists of three main components. Firstly, to recover the virtual features of the base data, we model the CLIP features of base class images as samples from a von Mises-Fisher (vMF) distribution based on the pre-trained classifier. Secondly, we leverage the text features of CLIP as low-cost semantic information and propose a feature-language prompt tuning (FLPT) method to further align the virtual image features and textual features. Thirdly, we train a conditional generative model using the well-aligned virtual image features and corresponding semantic text features, enabling the generation of new classes features and achieve better zero-shot generalization. Our framework has been evaluated on five commonly used benchmarks for generalized ZSL, as well as 11 benchmarks for the base-to-new ZSL. The results demonstrate the superiority and effectiveness of our approach. Our code is available in https://github.com/ylong4/DFZSL
FuncFooler: A Practical Black-box Attack Against Learning-based Binary Code Similarity Detection Methods
Aug 26, 2022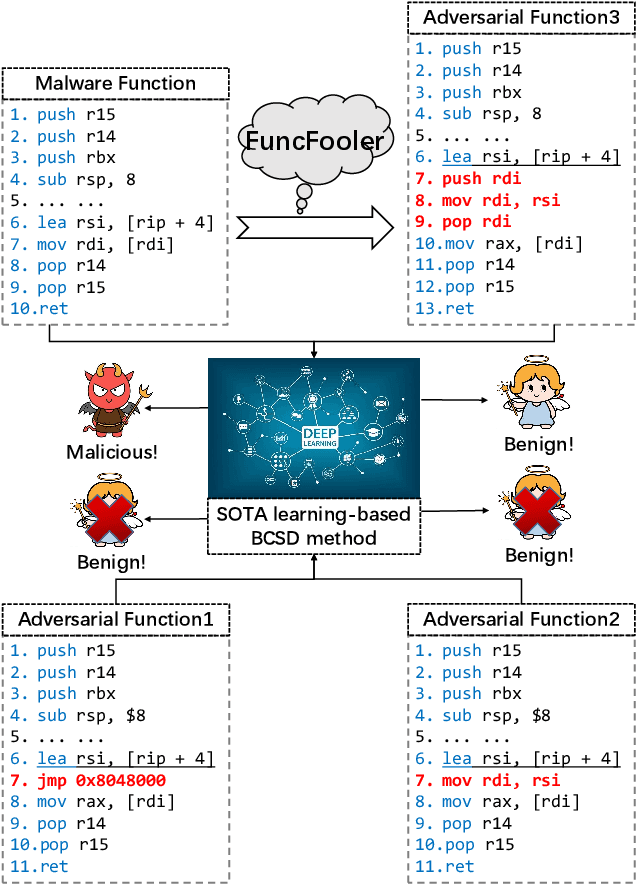
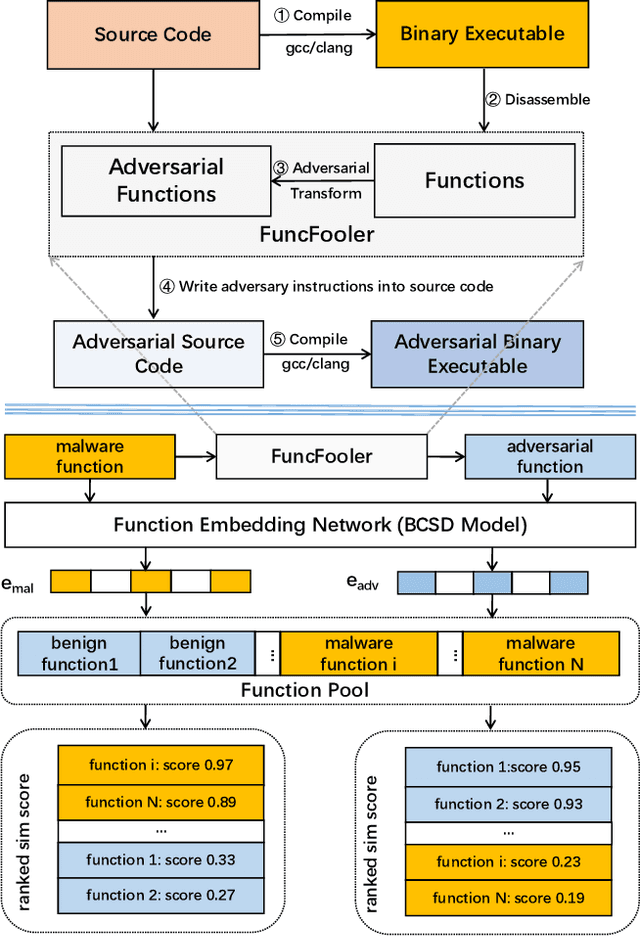

The binary code similarity detection (BCSD) method measures the similarity of two binary executable codes. Recently, the learning-based BCSD methods have achieved great success, outperforming traditional BCSD in detection accuracy and efficiency. However, the existing studies are rather sparse on the adversarial vulnerability of the learning-based BCSD methods, which cause hazards in security-related applications. To evaluate the adversarial robustness, this paper designs an efficient and black-box adversarial code generation algorithm, namely, FuncFooler. FuncFooler constrains the adversarial codes 1) to keep unchanged the program's control flow graph (CFG), and 2) to preserve the same semantic meaning. Specifically, FuncFooler consecutively 1) determines vulnerable candidates in the malicious code, 2) chooses and inserts the adversarial instructions from the benign code, and 3) corrects the semantic side effect of the adversarial code to meet the constraints. Empirically, our FuncFooler can successfully attack the three learning-based BCSD models, including SAFE, Asm2Vec, and jTrans, which calls into question whether the learning-based BCSD is desirable.
LighTN: Light-weight Transformer Network for Performance-overhead Tradeoff in Point Cloud Downsampling
Feb 13, 2022Compared with traditional task-irrelevant downsampling methods, task-oriented neural networks have shown improved performance in point cloud downsampling range. Recently, Transformer family of networks has shown a more powerful learning capacity in visual tasks. However, Transformer-based architectures potentially consume too many resources which are usually worthless for low overhead task networks in downsampling range. This paper proposes a novel light-weight Transformer network (LighTN) for task-oriented point cloud downsampling, as an end-to-end and plug-and-play solution. In LighTN, a single-head self-correlation module is presented to extract refined global contextual features, where three projection matrices are simultaneously eliminated to save resource overhead, and the output of symmetric matrix satisfies the permutation invariant. Then, we design a novel downsampling loss function to guide LighTN focuses on critical point cloud regions with more uniform distribution and prominent points coverage. Furthermore, We introduce a feed-forward network scaling mechanism to enhance the learnable capacity of LighTN according to the expand-reduce strategy. The result of extensive experiments on classification and registration tasks demonstrates LighTN can achieve state-of-the-art performance with limited resource overhead.