 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4RC: 4D Reconstruction via Conditional Querying Anytime and Anywhere
Feb 10, 2026We present 4RC, a unified feed-forward framework for 4D reconstruction from monocular videos. Unlike existing approaches that typically decouple motion from geometry or produce limited 4D attributes such as sparse trajectories or two-view scene flow, 4RC learns a holistic 4D representation that jointly captures dense scene geometry and motion dynamics. At its core, 4RC introduces a novel encode-once, query-anywhere and anytime paradigm: a transformer backbone encodes the entire video into a compact spatio-temporal latent space, from which a conditional decoder can efficiently query 3D geometry and motion for any query frame at any target timestamp. To facilitate learning, we represent per-view 4D attributes in a minimally factorized form by decomposing them into base geometry and time-dependent relative motion. Extensive experiments demonstrate that 4RC outperforms prior and concurrent methods across a wide range of 4D reconstruction tasks.
OmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Aug 14, 2025We present STream3R, a novel approach to 3D reconstruction that reformulates pointmap prediction as a decoder-only Transformer problem. Existing state-of-the-art methods for multi-view reconstruction either depend on expensive global optimization or rely on simplistic memory mechanisms that scale poorly with sequence length. In contrast, STream3R introduces an streaming framework that processes image sequences efficiently using causal attention, inspired by advances in modern language modeling. By learning geometric priors from large-scale 3D datasets, STream3R generalizes well to diverse and challenging scenarios, including dynamic scenes where traditional methods often fail. Extensive experiments show that our method consistently outperforms prior work across both static and dynamic scene benchmarks. Moreover, STream3R is inherently compatible with LLM-style training infrastructure, enabling efficient large-scale pretraining and fine-tuning for various downstream 3D tasks. Our results underscore the potential of causal Transformer models for online 3D perception, paving the way for real-time 3D understanding in streaming environments. More details can be found in our project page: https://nirvanalan.github.io/projects/stream3r.
3DEnhancer: Consistent Multi-View Diffusion for 3D Enhancement
Dec 24, 2024



Despite advances in neural rendering, due to the scarcity of high-quality 3D datasets and the inherent limitations of multi-view diffusion models, view synthesis and 3D model generation are restricted to low resolutions with suboptimal multi-view consistency. In this study, we present a novel 3D enhancement pipeline, dubbed 3DEnhancer, which employs a multi-view latent diffusion model to enhance coarse 3D inputs while preserving multi-view consistency. Our method includes a pose-aware encoder and a diffusion-based denoiser to refine low-quality multi-view images, along with data augmentation and a multi-view attention module with epipolar aggregation to maintain consistent, high-quality 3D outputs across views. Unlike existing video-based approaches, our model supports seamless multi-view enhancement with improved coherence across diverse viewing angles. Extensive evaluations show that 3DEnhancer significantly outperforms existing methods, boosting both multi-view enhancement and per-instance 3D optimization tasks.
Paint Bucket Colorization Using Anime Character Color Design Sheets
Oct 25, 2024



Line art colorization plays a crucial role in hand-drawn animation production, where digital artists manually colorize segments using a paint bucket tool, guided by RGB values from character color design sheets. This process, often called paint bucket colorization, involves two main tasks: keyframe colorization, where colors are applied according to the character's color design sheet, and consecutive frame colorization, where these colors are replicated across adjacent frames. Current automated colorization methods primarily focus on reference-based and segment-matching approaches. However, reference-based methods often fail to accurately assign specific colors to each region, while matching-based methods are limited to consecutive frame colorization and struggle with issues like significant deformation and occlusion. In this work, we introduce inclusion matching, which allows the network to understand the inclusion relationships between segments, rather than relying solely on direct visual correspondences. By integrating this approach with segment parsing and color warping modules, our inclusion matching pipeline significantly improves performance in both keyframe colorization and consecutive frame colorization. To support our network's training, we have developed a unique dataset named PaintBucket-Character, which includes rendered line arts alongside their colorized versions and shading annotations for various 3D characters. To replicate industry animation data formats, we also created color design sheets for each character, with semantic information for each color and standard pose reference images. Experiments highlight the superiority of our method, demonstrating accurate and consistent colorization across both our proposed benchmarks and hand-drawn animations.
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
Dec 11, 2023Text-based diffusion models have exhibited remarkable success in generation and editing, showing great promise for enhancing visual content with their generative prior. However, applying these models to video super-resolution remains challenging due to the high demands for output fidelity and temporal consistency, which is complicated by the inherent randomness in diffusion models. Our study introduces Upscale-A-Video, a text-guided latent diffusion framework for video upscaling. This framework ensures temporal coherence through two key mechanisms: locally, it integrates temporal layers into U-Net and VAE-Decoder, maintaining consistency within short sequences; globally, without training, a flow-guided recurrent latent propagation module is introduced to enhance overall video stability by propagating and fusing latent across the entire sequences. Thanks to the diffusion paradigm, our model also offers greater flexibility by allowing text prompts to guide texture creation and adjustable noise levels to balance restoration and generation, enabling a trade-off between fidelity and quality. Extensive experiments show that Upscale-A-Video surpasses existing methods in both synthetic and real-world benchmarks, as well as in AI-generated videos, showcasing impressive visual realism and temporal consistency.
Flare7K++: Mixing Synthetic and Real Datasets for Nighttime Flare Removal and Beyond
Jun 08, 2023



Artificial lights commonly leave strong lens flare artifacts on the images captured at night, degrading both the visual quality and performance of vision algorithms. Existing flare removal approaches mainly focus on removing daytime flares and fail in nighttime cases. Nighttime flare removal is challenging due to the unique luminance and spectrum of artificial lights, as well as the diverse patterns and image degradation of the flares. The scarcity of the nighttime flare removal dataset constraints the research on this crucial task. In this paper, we introduce Flare7K++, the first comprehensive nighttime flare removal dataset, consisting of 962 real-captured flare images (Flare-R) and 7,000 synthetic flares (Flare7K). Compared to Flare7K, Flare7K++ is particularly effective in eliminating complicated degradation around the light source, which is intractable by using synthetic flares alone. Besides, the previous flare removal pipeline relies on the manual threshold and blur kernel settings to extract light sources, which may fail when the light sources are tiny or not overexposed. To address this issue, we additionally provide the annotations of light sources in Flare7K++ and propose a new end-to-end pipeline to preserve the light source while removing lens flares. Our dataset and pipeline offer a valuable foundation and benchmark for future investigations into nighttime flare removal studies. Extensive experiments demonstrate that Flare7K++ supplements the diversity of existing flare datasets and pushes the frontier of nighttime flare removal towards real-world scenarios.
Nighttime Smartphone Reflective Flare Removal Using Optical Center Symmetry Prior
Mar 27, 2023



Reflective flare is a phenomenon that occurs when light reflects inside lenses, causing bright spots or a "ghosting effect" in photos, which can impact their quality. Eliminating reflective flare is highly desirable but challenging. Many existing methods rely on manually designed features to detect these bright spots, but they often fail to identify reflective flares created by various types of light and may even mistakenly remove the light sources in scenarios with multiple light sources. To address these challenges, we propose an optical center symmetry prior, which suggests that the reflective flare and light source are always symmetrical around the lens's optical center. This prior helps to locate the reflective flare's proposal region more accurately and can be applied to most smartphone cameras. Building on this prior, we create the first reflective flare removal dataset called BracketFlare, which contains diverse and realistic reflective flare patterns. We use continuous bracketing to capture the reflective flare pattern in the underexposed image and combine it with a normally exposed image to synthesize a pair of flare-corrupted and flare-free images. With the dataset, neural networks can be trained to remove the reflective flares effectively. Extensive experiments demonstrate the effectiveness of our method on both synthetic and real-world datasets.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
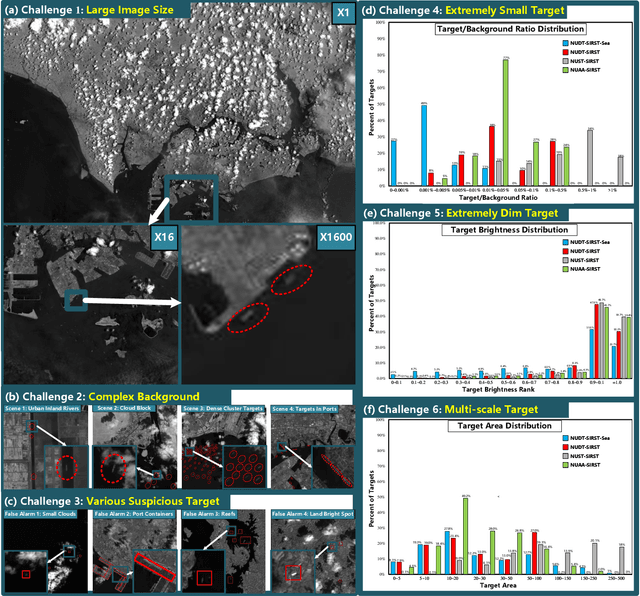
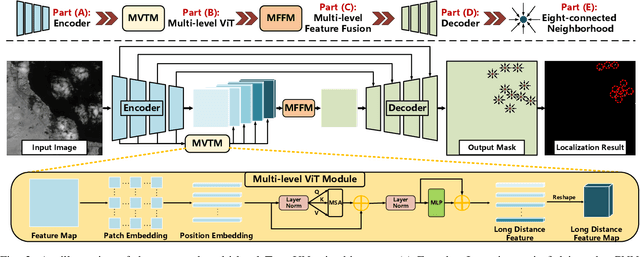
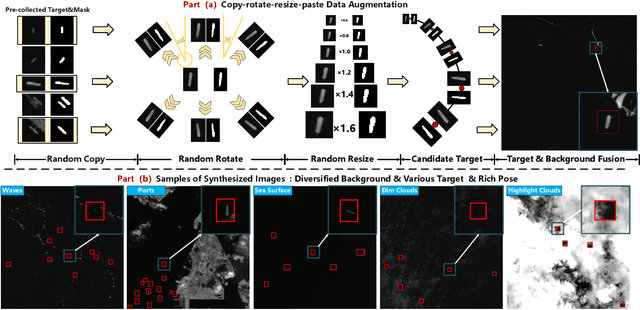
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.