 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Modeling Framework for Crop Prediction Tasks via Dynamic Parameter Calibration and Multi-Task Learning
Mar 16, 2026Accurate prediction of crop states (e.g., phenology stages and cold hardiness) is essential for timely farm management decisions such as irrigation, fertilization, and canopy management to optimize crop yield and quality. While traditional biophysical models can be used for season-long predictions, they lack the precision required for site-specific management. Deep learning methods are a compelling alternative, but can produce biologically unrealistic predictions and require large-scale data. We propose a \emph{hybrid modeling} approach that uses a neural network to parameterize a differentiable biophysical model and leverages multi-task learning for efficient data sharing across crop cultivars in data limited settings. By predicting the \emph{parameters} of the biophysical model, our approach improves the prediction accuracy while preserving biological realism. Empirical evaluation using real-world and synthetic datasets demonstrates that our method improves prediction accuracy by 60\% for phenology and 40\% for cold hardiness compared to deployed biophysical models.
Multi-Robot Coordination for Planning under Context Uncertainty
Mar 14, 2026Real-world robots often operate in settings where objective priorities depend on the underlying context of operation. When the underlying context is unknown apriori, multiple robots may have to coordinate to gather informative observations to infer the context, since acting based on an incorrect context can lead to misaligned and unsafe behavior. Once the underlying true context is inferred, the robots optimize their task-specific objectives in the preference order induced by the context. We formalize this problem as a Multi-Robot Context-Uncertain Stochastic Shortest Path (MR-CUSSP), which captures context-relevant information at landmark states through joint observations. Our two-stage solution approach is composed of: (1) CIMOP (Coordinated Inference for Multi-Objective Planning) to compute plans that guide robots toward informative landmarks to efficiently infer the true context, and (2) LCBS (Lexicographic Conflict-Based Search) for collision-free multi-robot path planning with lexicographic objective preferences, induced by the context. We evaluate the algorithms using three simulated domains and demonstrate its practical applicability using five mobile robots in the salp domain setup.
Multi-Objective Multi-Agent Path Finding with Lexicographic Cost Preferences
Oct 08, 2025Many real-world scenarios require multiple agents to coordinate in shared environments, while balancing trade-offs between multiple, potentially competing objectives. Current multi-objective multi-agent path finding (MO-MAPF) algorithms typically produce conflict-free plans by computing Pareto frontiers. They do not explicitly optimize for user-defined preferences, even when the preferences are available, and scale poorly with the number of objectives. We propose a lexicographic framework for modeling MO-MAPF, along with an algorithm \textit{Lexicographic Conflict-Based Search} (LCBS) that directly computes a single solution aligned with a lexicographic preference over objectives. LCBS integrates a priority-aware low-level $A^*$ search with conflict-based search, avoiding Pareto frontier construction and enabling efficient planning guided by preference over objectives. We provide insights into optimality and scalability, and empirically demonstrate that LCBS computes optimal solutions while scaling to instances with up to ten objectives -- far beyond the limits of existing MO-MAPF methods. Evaluations on standard and randomized MAPF benchmarks show consistently higher success rates against state-of-the-art baselines, especially with increasing number of objectives.
Calibrating Biophysical Models for Grape Phenology Prediction via Multi-Task Learning
Aug 05, 2025Accurate prediction of grape phenology is essential for timely vineyard management decisions, such as scheduling irrigation and fertilization, to maximize crop yield and quality. While traditional biophysical models calibrated on historical field data can be used for season-long predictions, they lack the precision required for fine-grained vineyard management. Deep learning methods are a compelling alternative but their performance is hindered by sparse phenology datasets, particularly at the cultivar level. We propose a hybrid modeling approach that combines multi-task learning with a recurrent neural network to parameterize a differentiable biophysical model. By using multi-task learning to predict the parameters of the biophysical model, our approach enables shared learning across cultivars while preserving biological structure, thereby improving the robustness and accuracy of predictions. Empirical evaluation using real-world and synthetic datasets demonstrates that our method significantly outperforms both conventional biophysical models and baseline deep learning approaches in predicting phenological stages, as well as other crop state variables such as cold-hardiness and wheat yield.
Learning with Expert Abstractions for Efficient Multi-Task Continuous Control
Mar 19, 2025Decision-making in complex, continuous multi-task environments is often hindered by the difficulty of obtaining accurate models for planning and the inefficiency of learning purely from trial and error. While precise environment dynamics may be hard to specify, human experts can often provide high-fidelity abstractions that capture the essential high-level structure of a task and user preferences in the target environment. Existing hierarchical approaches often target discrete settings and do not generalize across tasks. We propose a hierarchical reinforcement learning approach that addresses these limitations by dynamically planning over the expert-specified abstraction to generate subgoals to learn a goal-conditioned policy. To overcome the challenges of learning under sparse rewards, we shape the reward based on the optimal state value in the abstract model. This structured decision-making process enhances sample efficiency and facilitates zero-shot generalization. Our empirical evaluation on a suite of procedurally generated continuous control environments demonstrates that our approach outperforms existing hierarchical reinforcement learning methods in terms of sample efficiency, task completion rate, scalability to complex tasks, and generalization to novel scenarios.
WOFOSTGym: A Crop Simulator for Learning Annual and Perennial Crop Management Strategies
Feb 26, 2025We introduce WOFOSTGym, a novel crop simulation environment designed to train reinforcement learning (RL) agents to optimize agromanagement decisions for annual and perennial crops in single and multi-farm settings. Effective crop management requires optimizing yield and economic returns while minimizing environmental impact, a complex sequential decision-making problem well suited for RL. However, the lack of simulators for perennial crops in multi-farm contexts has hindered RL applications in this domain. Existing crop simulators also do not support multiple annual crops. WOFOSTGym addresses these gaps by supporting 23 annual crops and two perennial crops, enabling RL agents to learn diverse agromanagement strategies in multi-year, multi-crop, and multi-farm settings. Our simulator offers a suite of challenging tasks for learning under partial observability, non-Markovian dynamics, and delayed feedback. WOFOSTGym's standard RL interface allows researchers without agricultural expertise to explore a wide range of agromanagement problems. Our experiments demonstrate the learned behaviors across various crop varieties and soil types, highlighting WOFOSTGym's potential for advancing RL-driven decision support in agriculture.
Adaptive Querying for Reward Learning from Human Feedback
Dec 11, 2024



Learning from human feedback is a popular approach to train robots to adapt to user preferences and improve safety. Existing approaches typically consider a single querying (interaction) format when seeking human feedback and do not leverage multiple modes of user interaction with a robot. We examine how to learn a penalty function associated with unsafe behaviors, such as side effects, using multiple forms of human feedback, by optimizing the query state and feedback format. Our framework for adaptive feedback selection enables querying for feedback in critical states in the most informative format, while accounting for the cost and probability of receiving feedback in a certain format. We employ an iterative, two-phase approach which first selects critical states for querying, and then uses information gain to select a feedback format for querying across the sampled critical states. Our evaluation in simulation demonstrates the sample efficiency of our approach.
Mitigating Negative Side Effects in Multi-Agent Systems Using Blame Assignment
May 07, 2024
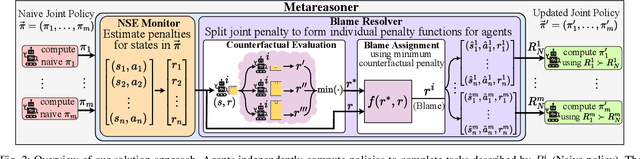
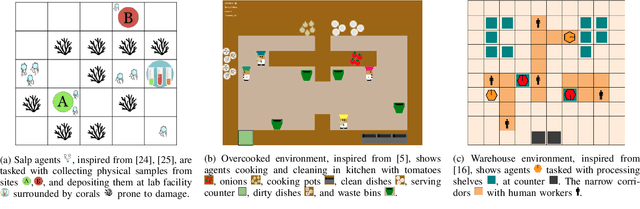

When agents that are independently trained (or designed) to complete their individual tasks are deployed in a shared environment, their joint actions may produce negative side effects (NSEs). As their training does not account for the behavior of other agents or their joint action effects on the environment, the agents have no prior knowledge of the NSEs of their actions. We model the problem of mitigating NSEs in a cooperative multi-agent system as a Lexicographic Decentralized Markov Decision Process with two objectives. The agents must optimize the completion of their assigned tasks while mitigating NSEs. We assume independence of transitions and rewards with respect to the agents' tasks but the joint NSE penalty creates a form of dependence in this setting. To improve scalability, the joint NSE penalty is decomposed into individual penalties for each agent using credit assignment, which facilitates decentralized policy computation. Our results in simulation on three domains demonstrate the effectiveness and scalability of our approach in mitigating NSEs by updating the policies of a subset of agents in the system.
Mitigating Negative Side Effects via Environment Shaping
Feb 13, 2021



Agents operating in unstructured environments often produce negative side effects (NSE), which are difficult to identify at design time. While the agent can learn to mitigate the side effects from human feedback, such feedback is often expensive and the rate of learning is sensitive to the agent's state representation. We examine how humans can assist an agent, beyond providing feedback, and exploit their broader scope of knowledge to mitigate the impacts of NSE. We formulate this problem as a human-agent team with decoupled objectives. The agent optimizes its assigned task, during which its actions may produce NSE. The human shapes the environment through minor reconfiguration actions so as to mitigate the impacts of the agent's side effects, without affecting the agent's ability to complete its assigned task. We present an algorithm to solve this problem and analyze its theoretical properties. Through experiments with human subjects, we assess the willingness of users to perform minor environment modifications to mitigate the impacts of NSE. Empirical evaluation of our approach shows that the proposed framework can successfully mitigate NSE, without affecting the agent's ability to complete its assigned task.
Learning to Generate Fair Clusters from Demonstrations
Feb 08, 2021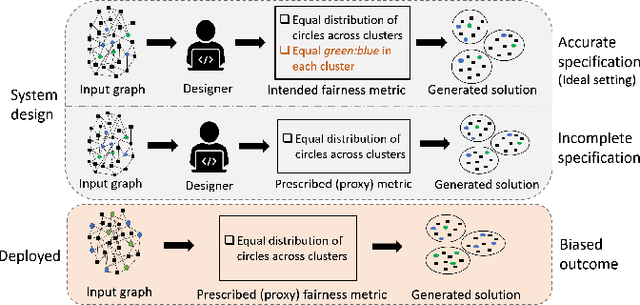


Fair clustering is the process of grouping similar entities together, while satisfying a mathematically well-defined fairness metric as a constraint. Due to the practical challenges in precise model specification, the prescribed fairness constraints are often incomplete and act as proxies to the intended fairness requirement, leading to biased outcomes when the system is deployed. We examine how to identify the intended fairness constraint for a problem based on limited demonstrations from an expert. Each demonstration is a clustering over a subset of the data. We present an algorithm to identify the fairness metric from demonstrations and generate clusters using existing off-the-shelf clustering techniques, and analyze its theoretical properties. To extend our approach to novel fairness metrics for which clustering algorithms do not currently exist, we present a greedy method for clustering. Additionally, we investigate how to generate interpretable solutions using our approach. Empirical evaluation on three real-world datasets demonstrates the effectiveness of our approach in quickly identifying the underlying fairness and interpretability constraints, which are then used to generate fair and interpretable clusters.