 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing the Tradeoff Between Clustering Value and Interpretability
Paper and Code


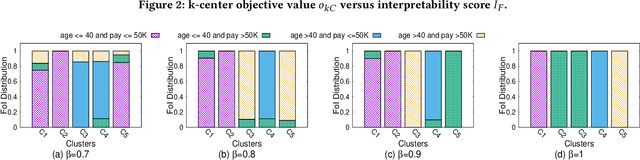
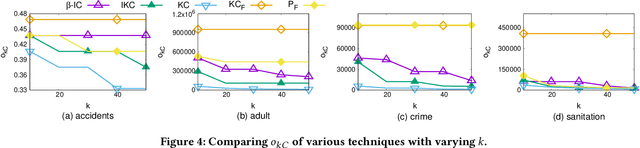
Graph clustering groups entities -- the vertices of a graph -- based on their similarity, typically using a complex distance function over a large number of features. Successful integration of clustering approaches in automated decision-support systems hinges on the interpretability of the resulting clusters. This paper addresses the problem of generating interpretable clusters, given features of interest that signify interpretability to an end-user, by optimizing interpretability in addition to common clustering objectives. We propose a $\beta$-interpretable clustering algorithm that ensures that at least $\beta$ fraction of nodes in each cluster share the same feature value. The tunable parameter $\beta$ is user-specified. We also present a more efficient algorithm for scenarios with $\beta\!=\!1$ and analyze the theoretical guarantees of the two algorithms. Finally, we empirically demonstrate the benefits of our approaches in generating interpretable clusters using four real-world datasets. The interpretability of the clusters is complemented by generating simple explanations denoting the feature values of the nodes in the clusters, using frequent pattern mining.