 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Negative Side Effects in Multi-Agent Systems Using Blame Assignment
Paper and Code
May 07, 2024
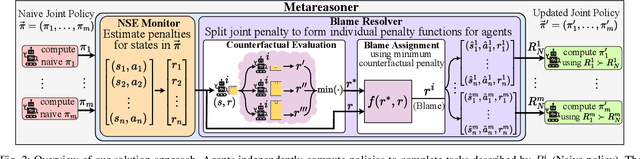
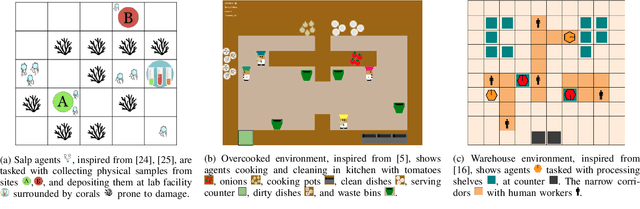

When agents that are independently trained (or designed) to complete their individual tasks are deployed in a shared environment, their joint actions may produce negative side effects (NSEs). As their training does not account for the behavior of other agents or their joint action effects on the environment, the agents have no prior knowledge of the NSEs of their actions. We model the problem of mitigating NSEs in a cooperative multi-agent system as a Lexicographic Decentralized Markov Decision Process with two objectives. The agents must optimize the completion of their assigned tasks while mitigating NSEs. We assume independence of transitions and rewards with respect to the agents' tasks but the joint NSE penalty creates a form of dependence in this setting. To improve scalability, the joint NSE penalty is decomposed into individual penalties for each agent using credit assignment, which facilitates decentralized policy computation. Our results in simulation on three domains demonstrate the effectiveness and scalability of our approach in mitigating NSEs by updating the policies of a subset of agents in the system.