 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Approach for Vehicle-to-Building Charging with Heterogeneous Agents and Long Term Rewards
Feb 24, 2025Strategic aggregation of electric vehicle batteries as energy reservoirs can optimize power grid demand, benefiting smart and connected communities, especially large office buildings that offer workplace charging. This involves optimizing charging and discharging to reduce peak energy costs and net peak demand, monitored over extended periods (e.g., a month), which involves making sequential decisions under uncertainty and delayed and sparse rewards, a continuous action space, and the complexity of ensuring generalization across diverse conditions. Existing algorithmic approaches, e.g., heuristic-based strategies, fall short in addressing real-time decision-making under dynamic conditions, and traditional reinforcement learning (RL) models struggle with large state-action spaces, multi-agent settings, and the need for long-term reward optimization. To address these challenges, we introduce a novel RL framework that combines the Deep Deterministic Policy Gradient approach (DDPG) with action masking and efficient MILP-driven policy guidance. Our approach balances the exploration of continuous action spaces to meet user charging demands. Using real-world data from a major electric vehicle manufacturer, we show that our approach comprehensively outperforms many well-established baselines and several scalable heuristic approaches, achieving significant cost savings while meeting all charging requirements. Our results show that the proposed approach is one of the first scalable and general approaches to solving the V2B energy management challenge.
Safe Wasserstein Constrained Deep Q-Learning
Feb 07, 2020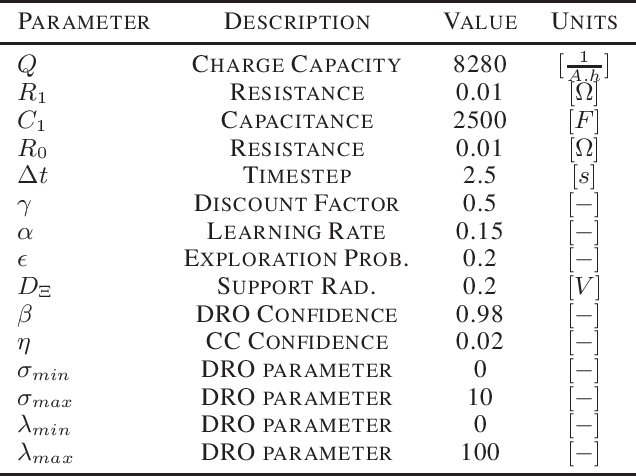
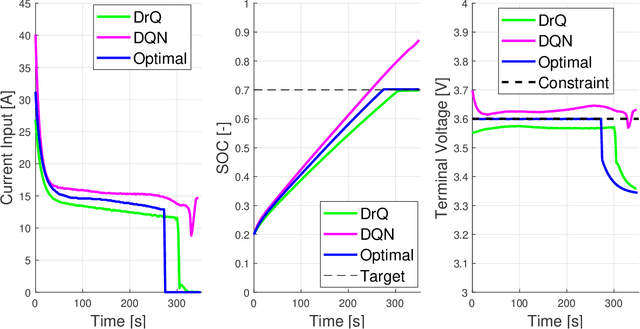

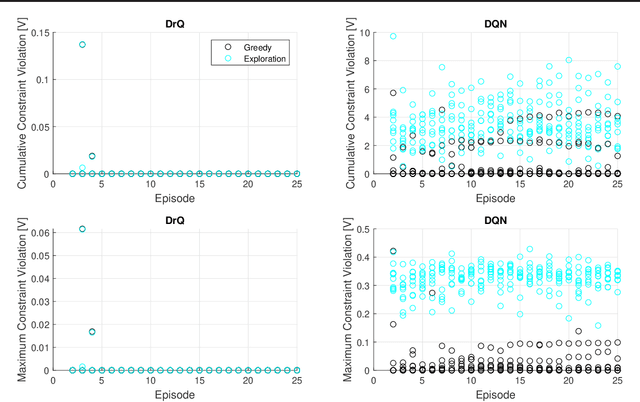
This paper presents a distributionally robust Q-Learning algorithm (DrQ) which leverages Wasserstein ambiguity sets to provide probabilistic out-of-sample safety guarantees during online learning. First, we follow past work by separating the constraint functions from the principal objective to create a hierarchy of machines within the constrained Markov decision process (CMDP). DrQ works within this framework by augmenting constraint costs with tightening offset variables obtained through Wasserstein distributionally robust optimization (DRO). These offset variables correspond to worst-case distributions of modeling error characterized by the TD-errors of the constraint Q-functions. This overall procedure allows us to safely approach the nominal constraint boundaries with strong probabilistic out-of-sample safety guarantees. Using a case study of safe lithium-ion battery fast charging, we demonstrate dramatic improvements in safety and performance relative to a conventional DQN.