 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRExIt: On Opponent Modelling in Expert Iteration
Paper and Code
May 31, 2022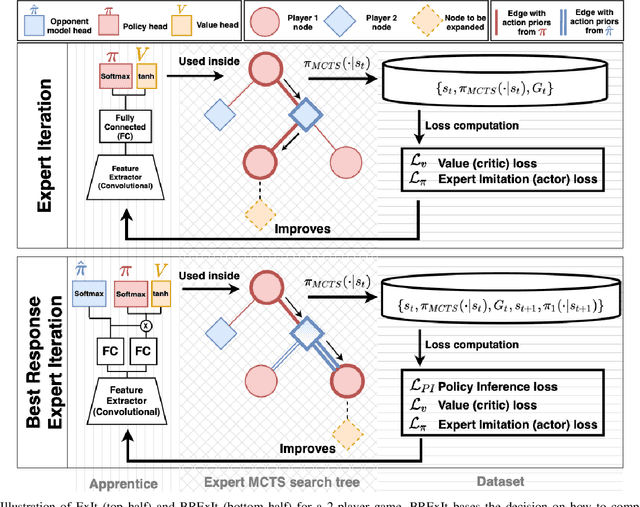
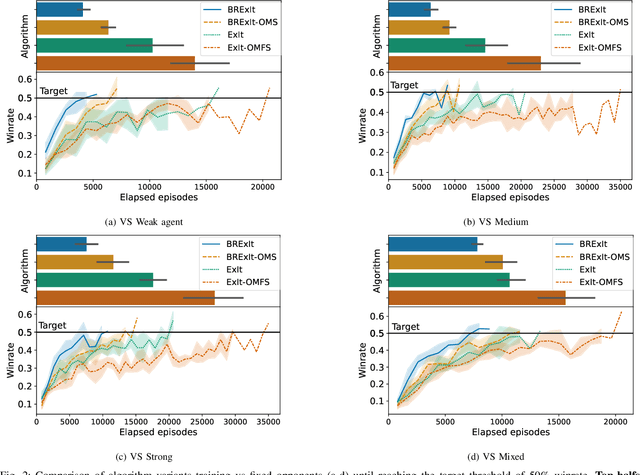
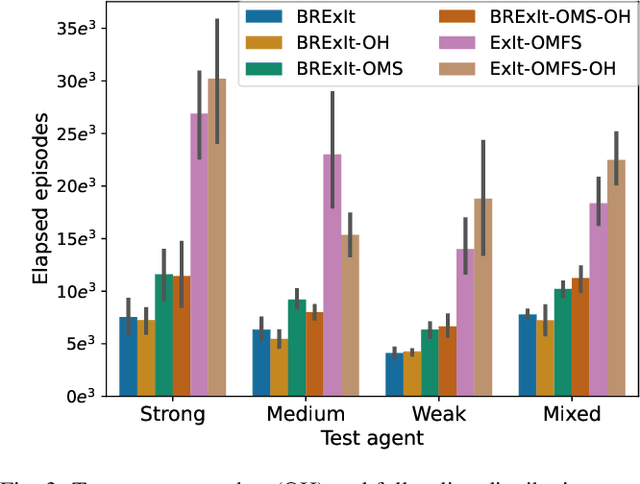
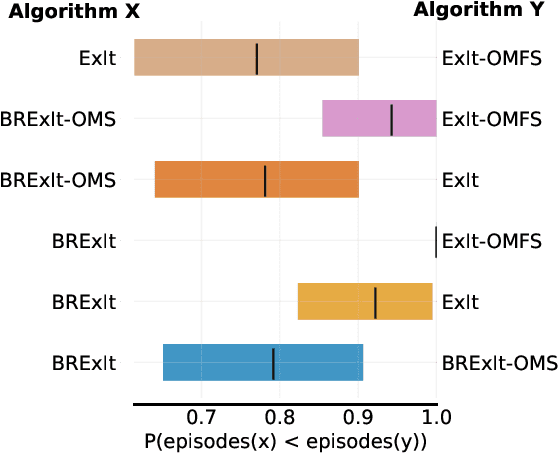
Finding a best response policy is a central objective in game theory and multi-agent learning, with modern population-based training approaches employing reinforcement learning algorithms as best-response oracles to improve play against candidate opponents (typically previously learnt policies). We propose Best Response Expert Iteration (BRExIt), which accelerates learning in games by incorporating opponent models into the state-of-the-art learning algorithm Expert Iteration (ExIt). BRExIt aims to (1) improve feature shaping in the apprentice, with a policy head predicting opponent policies as an auxiliary task, and (2) bias opponent moves in planning towards the given or learnt opponent model, to generate apprentice targets that better approximate a best response. In an empirical ablation on BRExIt's algorithmic variants in the game Connect4 against a set of fixed test agents, we provide statistical evidence that BRExIt learns well-performing policies with greater sample efficiency than ExIt.