 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Bounds for Approximate Influence-Based Abstraction
Nov 03, 2020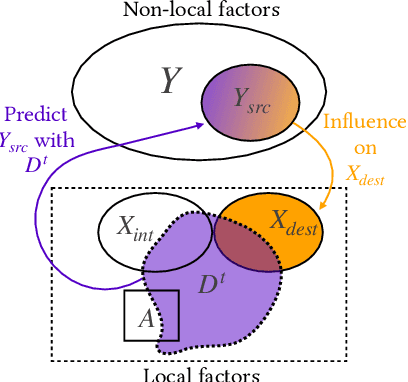
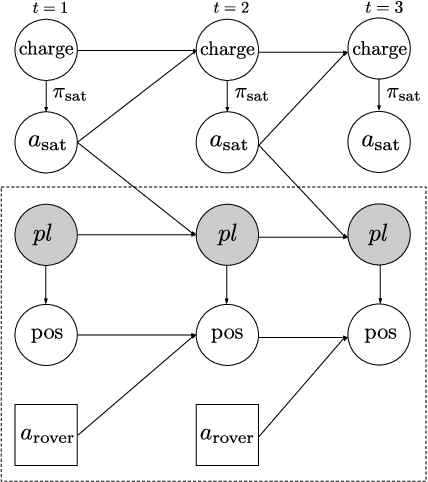
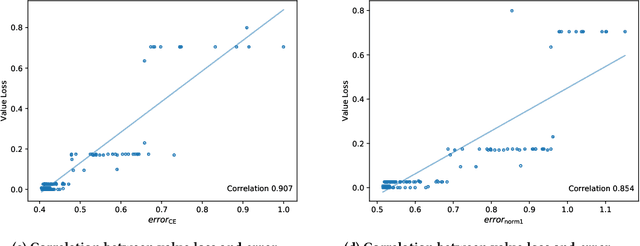
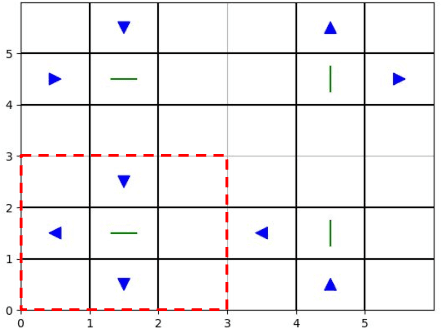
Sequential decision making techniques hold great promise to improve the performance of many real-world systems, but computational complexity hampers their principled application. Influence-based abstraction aims to gain leverage by modeling local subproblems together with the 'influence' that the rest of the system exerts on them. While computing exact representations of such influence might be intractable, learning approximate representations offers a promising approach to enable scalable solutions. This paper investigates the performance of such approaches from a theoretical perspective. The primary contribution is the derivation of sufficient conditions on approximate influence representations that can guarantee solutions with small value loss. In particular we show that neural networks trained with cross entropy are well suited to learn approximate influence representations. Moreover, we provide a sample based formulation of the bounds, which reduces the gap to applications. Finally, driven by our theoretical insights, we propose approximation error estimators, which empirically reveal to correlate well with the value loss.
Influence-aware Memory for Deep Reinforcement Learning
Nov 21, 2019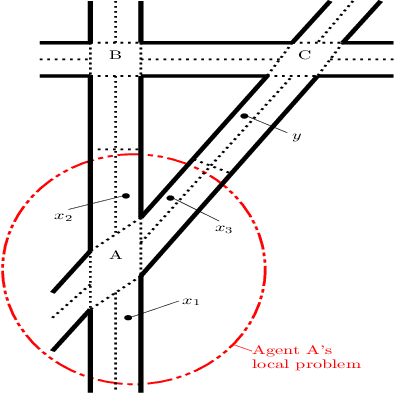
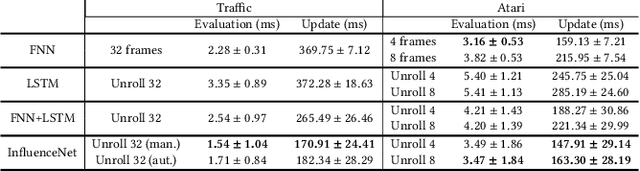


Making the right decisions when some of the state variables are hidden, involves reasoning about all the possible states of the environment. An agent receiving only partial observations needs to infer the true values of these hidden variables based on the history of experiences. Recent deep reinforcement learning methods use recurrent models to keep track of past information. However, these models are sometimes expensive to train and have convergence difficulties, especially when dealing with high dimensional input spaces. Taking inspiration from influence-based abstraction, we show that effective policies can be learned in the presence of uncertainty by only memorizing a small subset of input variables. We also incorporate a mechanism in our network that learns to automatically choose the important pieces of information that need to be remembered. The results indicate that, by forcing the agent's internal memory to focus on the selected regions while treating the rest of the observable variables as Markovian, we can outperform ordinary recurrent architectures in situations where the amount of information that the agent needs to retain represents a small fraction of the entire observation input. The method also reduces training time and obtains better scores than methods that stack multiple observations to remove partial observability in domains where long-term memory is required.