 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBad Habits: Policy Confounding and Out-of-Trajectory Generalization in RL
Paper and Code
Jun 04, 2023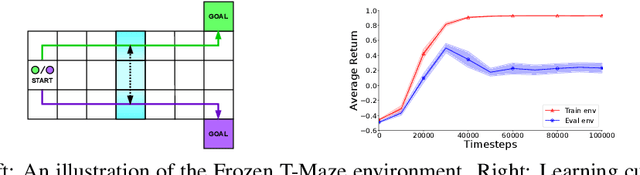


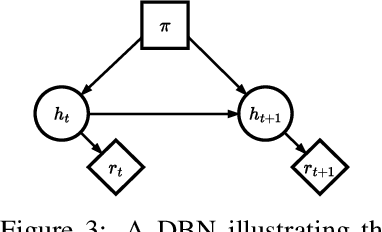
Reinforcement learning agents may sometimes develop habits that are effective only when specific policies are followed. After an initial exploration phase in which agents try out different actions, they eventually converge toward a particular policy. When this occurs, the distribution of state-action trajectories becomes narrower, and agents start experiencing the same transitions again and again. At this point, spurious correlations may arise. Agents may then pick up on these correlations and learn state representations that do not generalize beyond the agent's trajectory distribution. In this paper, we provide a mathematical characterization of this phenomenon, which we refer to as policy confounding, and show, through a series of examples, when and how it occurs in practice.