 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Rooftop PV Systems via Probabilistic Embeddings
May 15, 2025As the number of rooftop photovoltaic (PV) installations increases, aggregators and system operators are required to monitor and analyze these systems, raising the challenge of integration and management of large, spatially distributed time-series data that are both high-dimensional and affected by missing values. In this work, a probabilistic entity embedding-based clustering framework is proposed to address these problems. This method encodes each PV system's characteristic power generation patterns and uncertainty as a probability distribution, then groups systems by their statistical distances and agglomerative clustering. Applied to a multi-year residential PV dataset, it produces concise, uncertainty-aware cluster profiles that outperform a physics-based baseline in representativeness and robustness, and support reliable missing-value imputation. A systematic hyperparameter study further offers practical guidance for balancing model performance and robustness.
One Model to Forecast Them All and in Entity Distributions Bind Them
Jan 26, 2025Probabilistic forecasting in power systems often involves multi-entity datasets like households, feeders, and wind turbines, where generating reliable entity-specific forecasts presents significant challenges. Traditional approaches require training individual models for each entity, making them inefficient and hard to scale. This study addresses this problem using GUIDE-VAE, a conditional variational autoencoder that allows entity-specific probabilistic forecasting using a single model. GUIDE-VAE provides flexible outputs, ranging from interpretable point estimates to full probability distributions, thanks to its advanced covariance composition structure. These distributions capture uncertainty and temporal dependencies, offering richer insights than traditional methods. To evaluate our GUIDE-VAE-based forecaster, we use household electricity consumption data as a case study due to its multi-entity and highly stochastic nature. Experimental results demonstrate that GUIDE-VAE outperforms conventional quantile regression techniques across key metrics while ensuring scalability and versatility. These features make GUIDE-VAE a powerful and generalizable tool for probabilistic forecasting tasks, with potential applications beyond household electricity consumption.
Data Enrichment Opportunities for Distribution Grid Cable Networks using Variational Autoencoders
Jan 19, 2025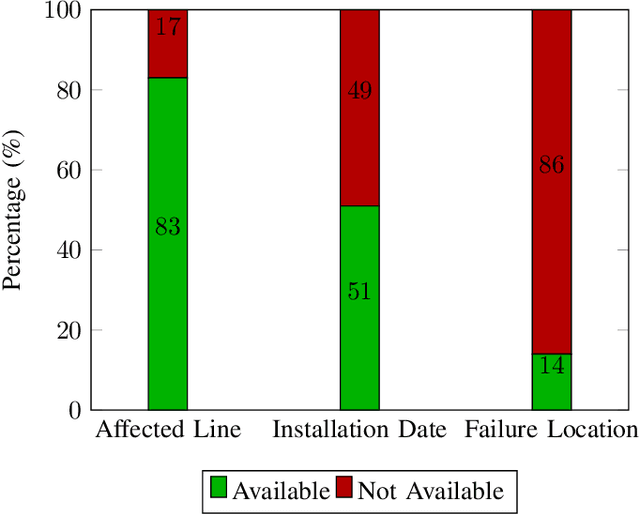


Electricity distribution cable networks suffer from incomplete and unbalanced data, hindering the effectiveness of machine learning models for predictive maintenance and reliability evaluation. Features such as the installation date of the cables are frequently missing. To address data scarcity, this study investigates the application of Variational Autoencoders (VAEs) for data enrichment, synthetic data generation, imbalanced data handling, and outlier detection. Based on a proof-of-concept case study for Denmark, targeting the imputation of missing age information in cable network asset registers, the analysis underlines the potential of generative models to support data-driven maintenance. However, the study also highlights several areas for improvement, including enhanced feature importance analysis, incorporating network characteristics and external features, and handling biases in missing data. Future initiatives should expand the application of VAEs by incorporating semi-supervised learning, advanced sampling techniques, and additional distribution grid elements, including low-voltage networks, into the analysis.
GUIDE-VAE: Advancing Data Generation with User Information and Pattern Dictionaries
Nov 06, 2024



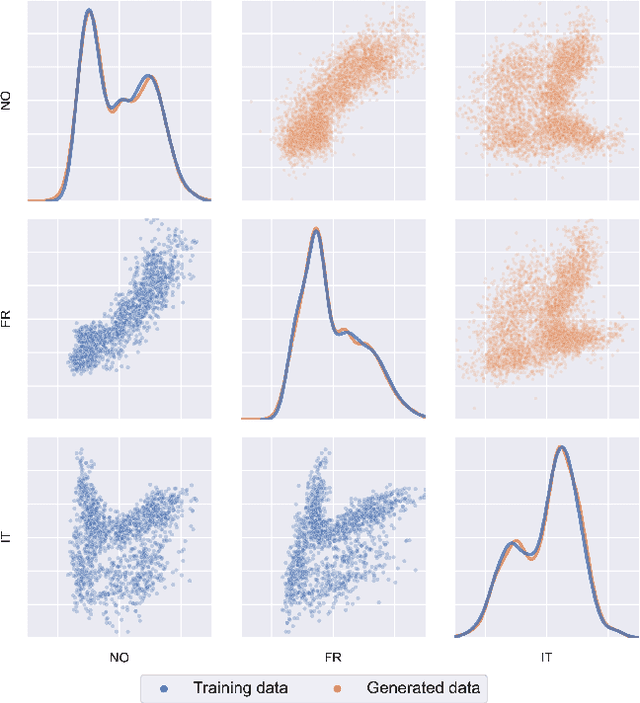
Generative modelling of multi-user datasets has become prominent in science and engineering. Generating a data point for a given user requires employing user information, and conventional generative models, including variational autoencoders (VAEs), often ignore that. This paper introduces GUIDE-VAE, a novel conditional generative model that leverages user embeddings to generate user-guided data. By allowing the model to benefit from shared patterns across users, GUIDE-VAE enhances performance in multi-user settings, even under significant data imbalance. In addition to integrating user information, GUIDE-VAE incorporates a pattern dictionary-based covariance composition (PDCC) to improve the realism of generated samples by capturing complex feature dependencies. While user embeddings drive performance gains, PDCC addresses common issues such as noise and over-smoothing typically seen in VAEs. The proposed GUIDE-VAE was evaluated on a multi-user smart meter dataset characterized by substantial data imbalance across users. Quantitative results show that GUIDE-VAE performs effectively in both synthetic data generation and missing record imputation tasks, while qualitative evaluations reveal that GUIDE-VAE produces more plausible and less noisy data. These results establish GUIDE-VAE as a promising tool for controlled, realistic data generation in multi-user datasets, with potential applications across various domains requiring user-informed modelling.
Stable Training of Probabilistic Models Using the Leave-One-Out Maximum Log-Likelihood Objective
Oct 05, 2023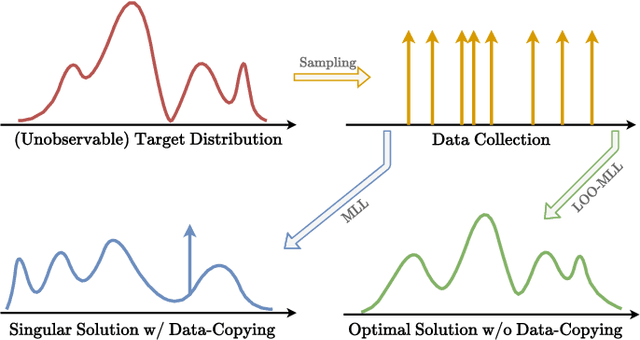
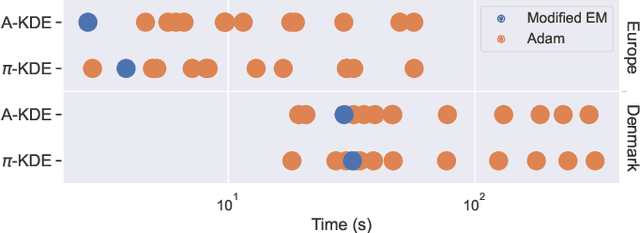
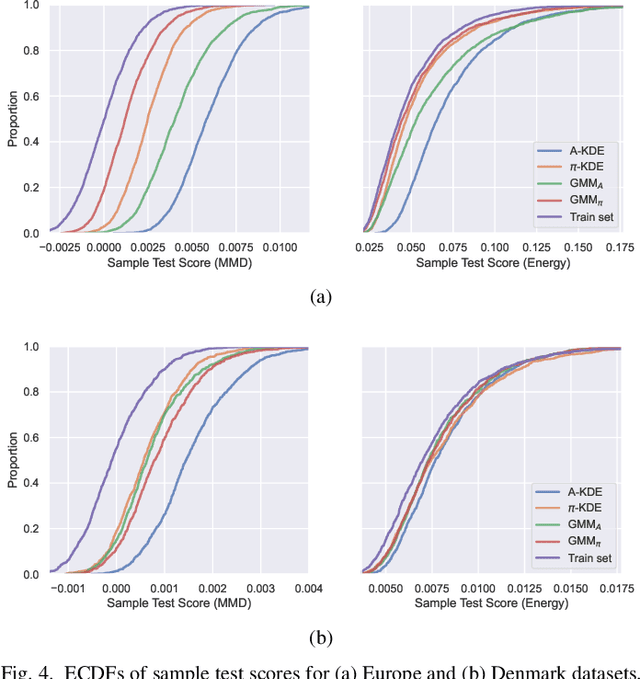
Probabilistic modelling of power systems operation and planning processes depends on data-driven methods, which require sufficiently large datasets. When historical data lacks this, it is desired to model the underlying data generation mechanism as a probability distribution to assess the data quality and generate more data, if needed. Kernel density estimation (KDE) based models are popular choices for this task, but they fail to adapt to data regions with varying densities. In this paper, an adaptive KDE model is employed to circumvent this, where each kernel in the model has an individual bandwidth. The leave-one-out maximum log-likelihood (LOO-MLL) criterion is proposed to prevent the singular solutions that the regular MLL criterion gives rise to, and it is proven that LOO-MLL prevents these. Relying on this guaranteed robustness, the model is extended by assigning learnable weights to the kernels. In addition, a modified expectation-maximization algorithm is employed to accelerate the optimization speed reliably. The performance of the proposed method and models are exhibited on two power systems datasets using different statistical tests and by comparison with Gaussian mixture models. Results show that the proposed models have promising performance, in addition to their singularity prevention guarantees.
Channel State Information Based Localization with Deep Learning
Sep 25, 2021Localization is one of the most important problems in various fields such as robotics and wireless communications. For instance, Unmanned Aerial Vehicles (UAVs) require the information of the position precisely for an adequate control strategy. This problem is handled very efficiently with integrated GPS units for outdoor applications. However, indoor applications require special treatment due to the unavailability of GPS signals. Another aspect of mobile robots such as UAVs is that there is constant wireless communication between the mobile robot and a computational unit. This communication is mainly done for obtaining telemetry information or computation of control actions directly. The responsible integrated units for this transmission are commercial wireless communication chipsets. These units on the receiver side are responsible for getting rid of the diverse effects of the communication channel with various mathematical techniques. These techniques mainly require the Channel State Information (CSI) of the current channel to compensate the channel itself. After the compensation, the chipset has nothing to do with CSI. However, the locations of both the transmitter and receiver have a direct impact on CSI. Even though CSI contains such rich information about the environment, the accessibility of these data is blocked by the commercial wireless chipsets since they are manufactured to provide only the processed information data bits to the user. However, with the IEEE 802.11n standardization, certain chipsets provide access to CSI. Therefore, CSI data became processible and integrable to localization schemes. In this project, a test environment was constructed for the localization task. Two routers with proper chipsets were assigned as transmitter and receiver. They were operationalized for the CSI data collection. Lastly, these data were processed with various deep learning models.