 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPlan: Hierarchical Planning for LLM-Based Agents with Adaptive Global-Local Guidance
Aug 26, 2025Large language model (LLM)-based agents have demonstrated remarkable capabilities in decision-making tasks, but struggle significantly with complex, long-horizon planning scenarios. This arises from their lack of macroscopic guidance, causing disorientation and failures in complex tasks, as well as insufficient continuous oversight during execution, rendering them unresponsive to environmental changes and prone to deviations. To tackle these challenges, we introduce HiPlan, a hierarchical planning framework that provides adaptive global-local guidance to boost LLM-based agents'decision-making. HiPlan decomposes complex tasks into milestone action guides for general direction and step-wise hints for detailed actions. During the offline phase, we construct a milestone library from expert demonstrations, enabling structured experience reuse by retrieving semantically similar tasks and milestones. In the execution phase, trajectory segments from past milestones are dynamically adapted to generate step-wise hints that align current observations with the milestone objectives, bridging gaps and correcting deviations. Extensive experiments across two challenging benchmarks demonstrate that HiPlan substantially outperforms strong baselines, and ablation studies validate the complementary benefits of its hierarchical components.
TreeReview: A Dynamic Tree of Questions Framework for Deep and Efficient LLM-based Scientific Peer Review
Jun 09, 2025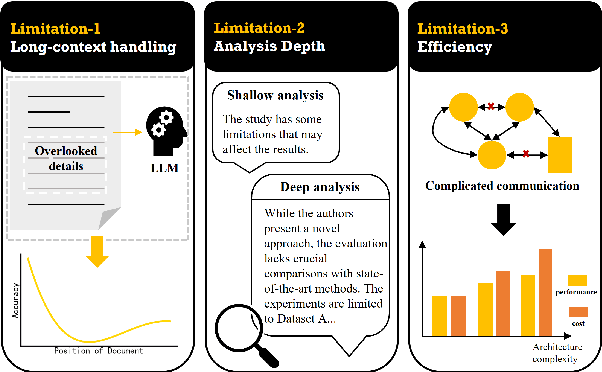
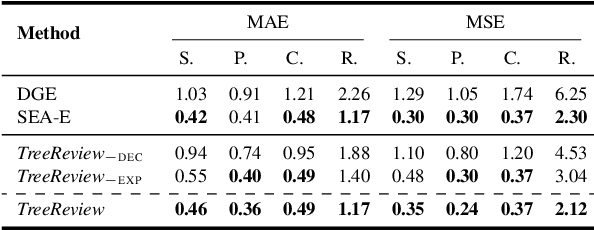
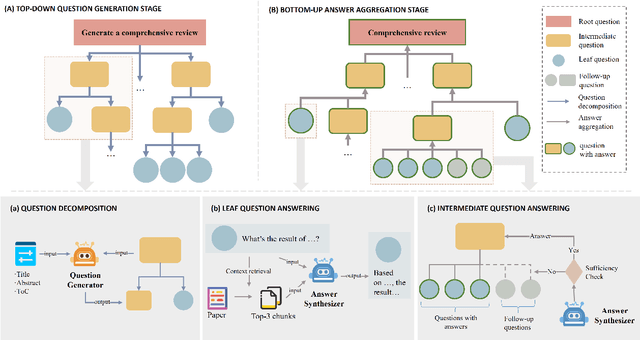
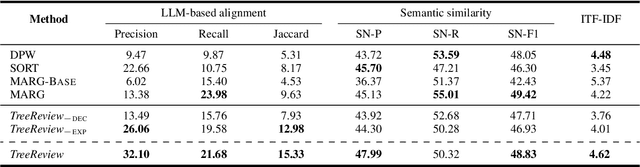
While Large Language Models (LLMs) have shown significant potential in assisting peer review, current methods often struggle to generate thorough and insightful reviews while maintaining efficiency. In this paper, we propose TreeReview, a novel framework that models paper review as a hierarchical and bidirectional question-answering process. TreeReview first constructs a tree of review questions by recursively decomposing high-level questions into fine-grained sub-questions and then resolves the question tree by iteratively aggregating answers from leaf to root to get the final review. Crucially, we incorporate a dynamic question expansion mechanism to enable deeper probing by generating follow-up questions when needed. We construct a benchmark derived from ICLR and NeurIPS venues to evaluate our method on full review generation and actionable feedback comments generation tasks. Experimental results of both LLM-based and human evaluation show that TreeReview outperforms strong baselines in providing comprehensive, in-depth, and expert-aligned review feedback, while reducing LLM token usage by up to 80% compared to computationally intensive approaches. Our code and benchmark dataset are available at https://github.com/YuanChang98/tree-review.
Semi-KAN: KAN Provides an Effective Representation for Semi-Supervised Learning in Medical Image Segmentation
Mar 19, 2025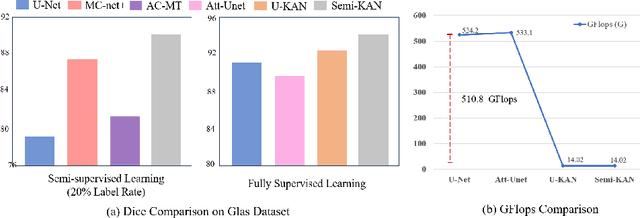
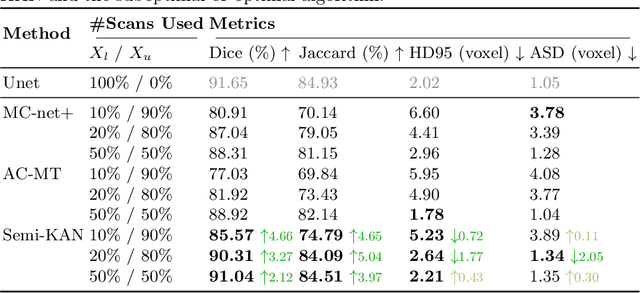
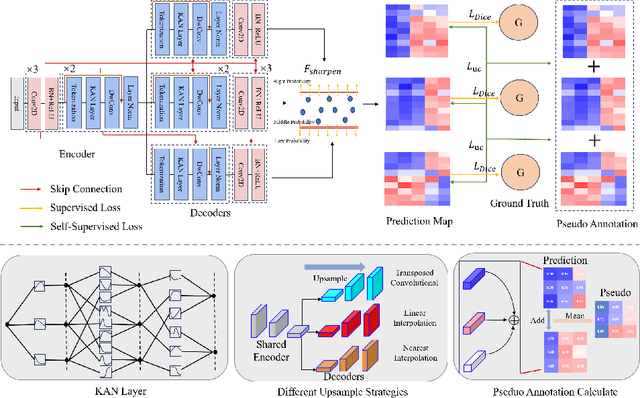
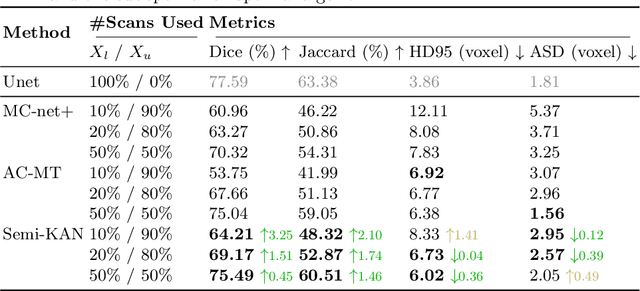
Deep learning-based medical image segmentation has shown remarkable success; however, it typically requires extensive pixel-level annotations, which are both expensive and time-intensive. Semi-supervised medical image segmentation (SSMIS) offers a viable alternative, driven by advancements in CNNs and ViTs. However, these networks often rely on single fixed activation functions and linear modeling patterns, limiting their ability to effectively learn robust representations. Given the limited availability of labeled date, achieving robust representation learning becomes crucial. Inspired by Kolmogorov-Arnold Networks (KANs), we propose Semi-KAN, which leverages the untapped potential of KANs to enhance backbone architectures for representation learning in SSMIS. Our findings indicate that: (1) compared to networks with fixed activation functions, KANs exhibit superior representation learning capabilities with fewer parameters, and (2) KANs excel in high-semantic feature spaces. Building on these insights, we integrate KANs into tokenized intermediate representations, applying them selectively at the encoder's bottleneck and the decoder's top layers within a U-Net pipeline to extract high-level semantic features. Although learnable activation functions improve feature expansion, they introduce significant computational overhead with only marginal performance gains. To mitigate this, we reduce the feature dimensions and employ horizontal scaling to capture multiple pattern representations. Furthermore, we design a multi-branch U-Net architecture with uncertainty estimation to effectively learn diverse pattern representations. Extensive experiments on four public datasets demonstrate that Semi-KAN surpasses baseline networks, utilizing fewer KAN layers and lower computational cost, thereby underscoring the potential of KANs as a promising approach for SSMIS.
Human-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
Mar 04, 2025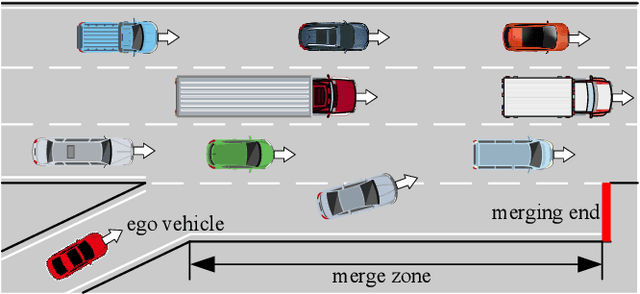
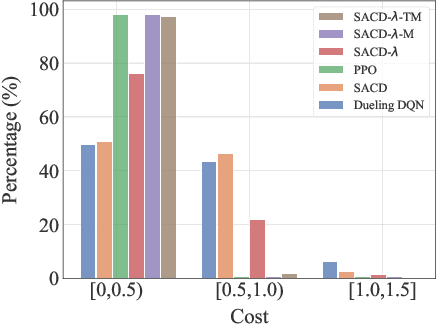
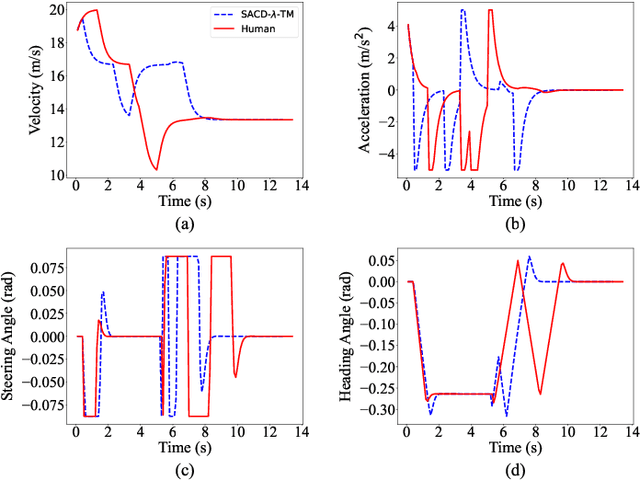
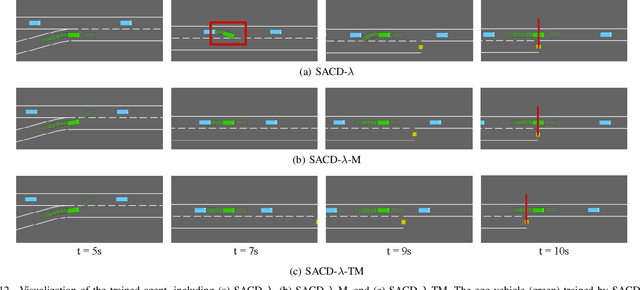
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.
Deep Monocular 3D Human Pose Estimation via Cascaded Dimension-Lifting
Apr 08, 2021
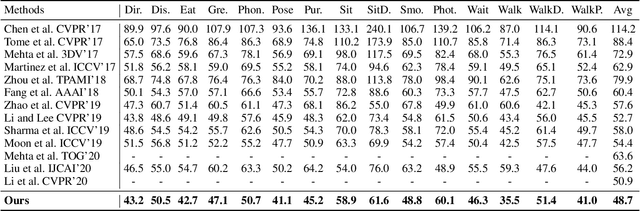


The 3D pose estimation from a single image is a challenging problem due to depth ambiguity. One type of the previous methods lifts 2D joints, obtained by resorting to external 2D pose detectors, to the 3D space. However, this type of approaches discards the contextual information of images which are strong cues for 3D pose estimation. Meanwhile, some other methods predict the joints directly from monocular images but adopt a 2.5D output representation $P^{2.5D} = (u,v,z^{r}) $ where both $u$ and $v$ are in the image space but $z^{r}$ in root-relative 3D space. Thus, the ground-truth information (e.g., the depth of root joint from the camera) is normally utilized to transform the 2.5D output to the 3D space, which limits the applicability in practice. In this work, we propose a novel end-to-end framework that not only exploits the contextual information but also produces the output directly in the 3D space via cascaded dimension-lifting. Specifically, we decompose the task of lifting pose from 2D image space to 3D spatial space into several sequential sub-tasks, 1) kinematic skeletons \& individual joints estimation in 2D space, 2) root-relative depth estimation, and 3) lifting to the 3D space, each of which employs direct supervisions and contextual image features to guide the learning process. Extensive experiments show that the proposed framework achieves state-of-the-art performance on two widely used 3D human pose datasets (Human3.6M, MuPoTS-3D).
EMLight: Lighting Estimation via Spherical Distribution Approximation
Dec 21, 2020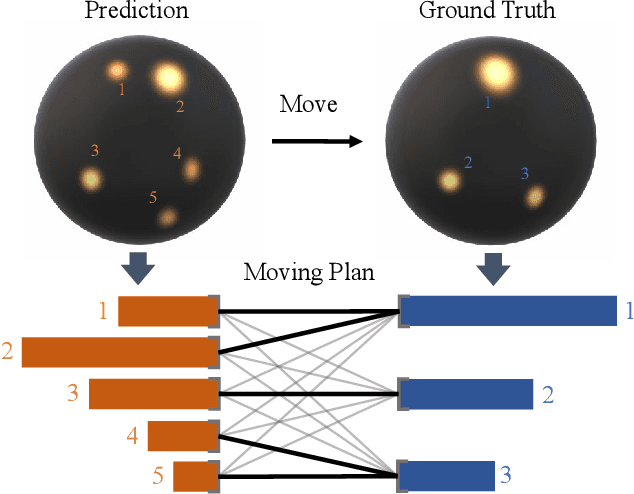


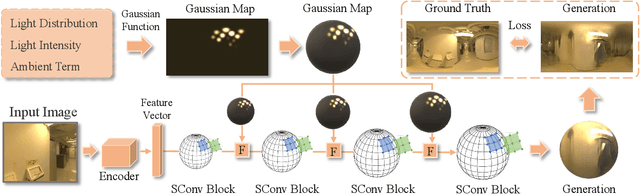
Illumination estimation from a single image is critical in 3D rendering and it has been investigated extensively in the computer vision and computer graphic research community. On the other hand, existing works estimate illumination by either regressing light parameters or generating illumination maps that are often hard to optimize or tend to produce inaccurate predictions. We propose Earth Mover Light (EMLight), an illumination estimation framework that leverages a regression network and a neural projector for accurate illumination estimation. We decompose the illumination map into spherical light distribution, light intensity and the ambient term, and define the illumination estimation as a parameter regression task for the three illumination components. Motivated by the Earth Mover distance, we design a novel spherical mover's loss that guides to regress light distribution parameters accurately by taking advantage of the subtleties of spherical distribution. Under the guidance of the predicted spherical distribution, light intensity and ambient term, the neural projector synthesizes panoramic illumination maps with realistic light frequency. Extensive experiments show that EMLight achieves accurate illumination estimation and the generated relighting in 3D object embedding exhibits superior plausibility and fidelity as compared with state-of-the-art methods.
Time-Efficient Mars Exploration of Simultaneous Coverage and Charging with Multiple Drones
Nov 16, 2020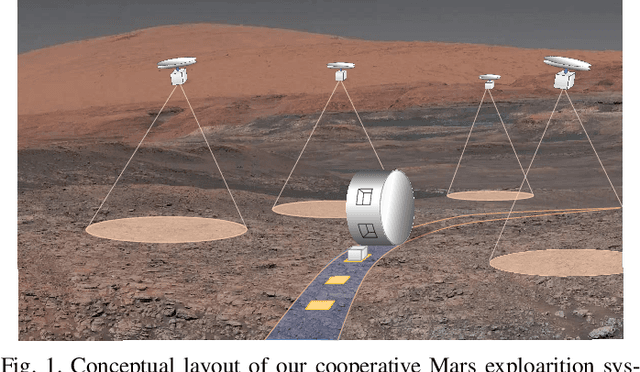
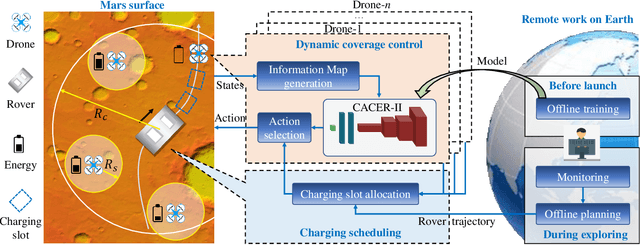
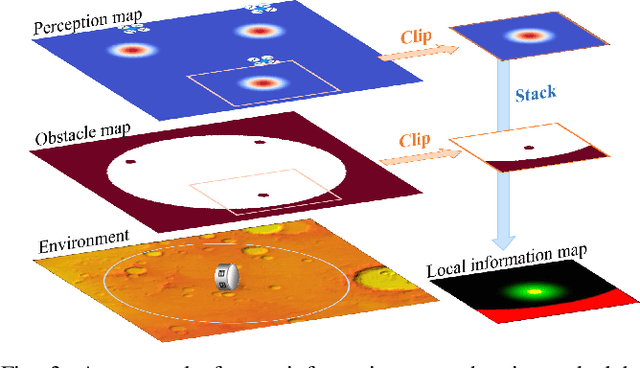
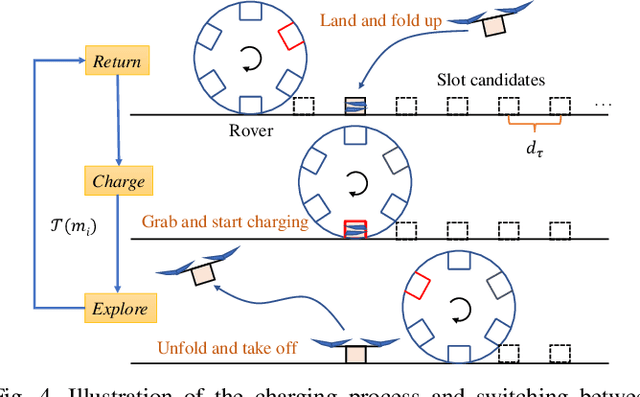
This paper presents a time-efficient scheme for Mars exploration by the cooperation of multiple drones and a rover. To maximize effective coverage of the Mars surface in the long run, a comprehensive framework has been developed with joint consideration for limited energy, sensor model, communication range and safety radius, which we call TIME-SC2 (TIme-efficient Mars Exploration of Simultaneous Coverage and Charging). First, we propose a multi-drone coverage control algorithm by leveraging emerging deep reinforcement learning and design a novel information map to represent dynamic system states. Second, we propose a near-optimal charging scheduling algorithm to navigate each drone to an individual charging slot, and we have proven that there always exists feasible solutions. The attractiveness of this framework not only resides on its ability to maximize exploration efficiency, but also on its high autonomy that has greatly reduced the non-exploring time. Extensive simulations have been conducted to demonstrate the remarkable performance of TIME-SC2 in terms of time-efficiency, adaptivity and flexibility.