 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAVD-Mamba: Deformable Token Fusion Vision Mamba for Multimodal UAV Detection
Jul 01, 2025Unmanned Aerial Vehicle (UAV) object detection has been widely used in traffic management, agriculture, emergency rescue, etc. However, it faces significant challenges, including occlusions, small object sizes, and irregular shapes. These challenges highlight the necessity for a robust and efficient multimodal UAV object detection method. Mamba has demonstrated considerable potential in multimodal image fusion. Leveraging this, we propose UAVD-Mamba, a multimodal UAV object detection framework based on Mamba architectures. To improve geometric adaptability, we propose the Deformable Token Mamba Block (DTMB) to generate deformable tokens by incorporating adaptive patches from deformable convolutions alongside normal patches from normal convolutions, which serve as the inputs to the Mamba Block. To optimize the multimodal feature complementarity, we design two separate DTMBs for the RGB and infrared (IR) modalities, with the outputs from both DTMBs integrated into the Mamba Block for feature extraction and into the Fusion Mamba Block for feature fusion. Additionally, to improve multiscale object detection, especially for small objects, we stack four DTMBs at different scales to produce multiscale feature representations, which are then sent to the Detection Neck for Mamba (DNM). The DNM module, inspired by the YOLO series, includes modifications to the SPPF and C3K2 of YOLOv11 to better handle the multiscale features. In particular, we employ cross-enhanced spatial attention before the DTMB and cross-channel attention after the Fusion Mamba Block to extract more discriminative features. Experimental results on the DroneVehicle dataset show that our method outperforms the baseline OAFA method by 3.6% in the mAP metric. Codes will be released at https://github.com/GreatPlum-hnu/UAVD-Mamba.git.
Post-interactive Multimodal Trajectory Prediction for Autonomous Driving
Mar 12, 2025Modeling the interactions among agents for trajectory prediction of autonomous driving has been challenging due to the inherent uncertainty in agents' behavior. The interactions involved in the predicted trajectories of agents, also called post-interactions, have rarely been considered in trajectory prediction models. To this end, we propose a coarse-to-fine Transformer for multimodal trajectory prediction, i.e., Pioformer, which explicitly extracts the post-interaction features to enhance the prediction accuracy. Specifically, we first build a Coarse Trajectory Network to generate coarse trajectories based on the observed trajectories and lane segments, in which the low-order interaction features are extracted with the graph neural networks. Next, we build a hypergraph neural network-based Trajectory Proposal Network to generate trajectory proposals, where the high-order interaction features are learned by the hypergraphs. Finally, the trajectory proposals are sent to the Proposal Refinement Network for further refinement. The observed trajectories and trajectory proposals are concatenated together as the inputs of the Proposal Refinement Network, in which the post-interaction features are learned by combining the previous interaction features and trajectory consistency features. Moreover, we propose a three-stage training scheme to facilitate the learning process. Extensive experiments on the Argoverse 1 dataset demonstrate the superiority of our method. Compared with the baseline HiVT-64, our model has reduced the prediction errors by 4.4%, 8.4%, 14.4%, 5.7% regarding metrics minADE6, minFDE6, MR6, and brier-minFDE6, respectively.
Human-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
Mar 04, 2025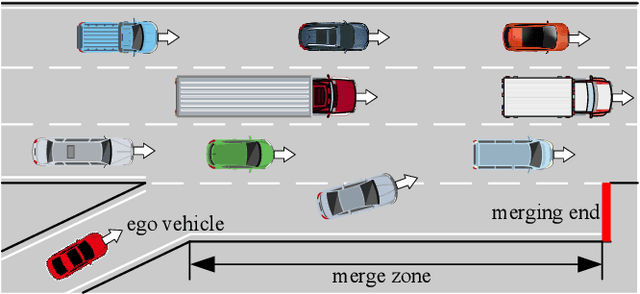
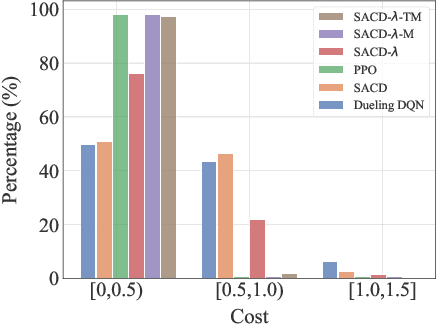
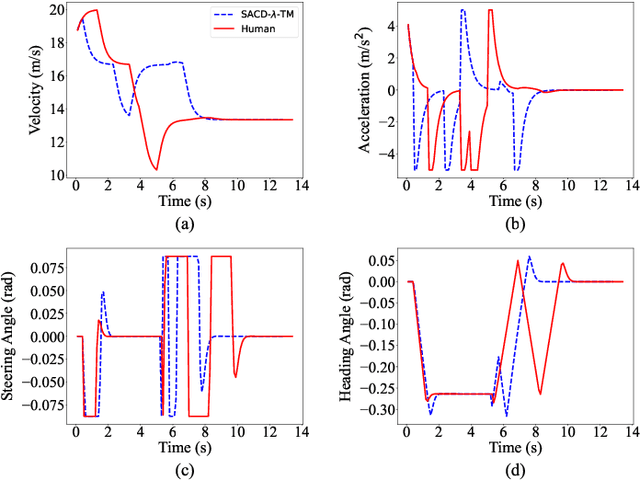
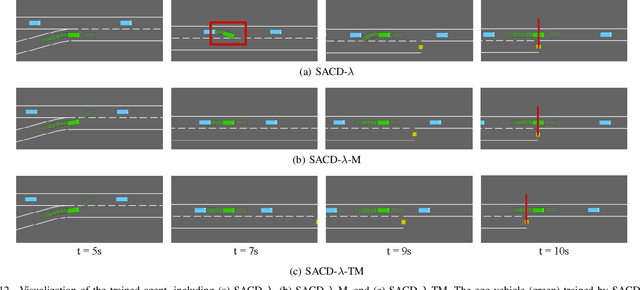
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.