 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
Mar 04, 2025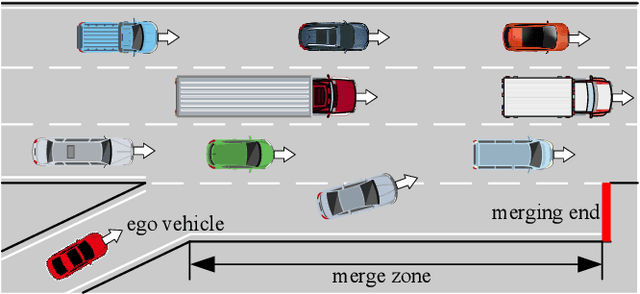
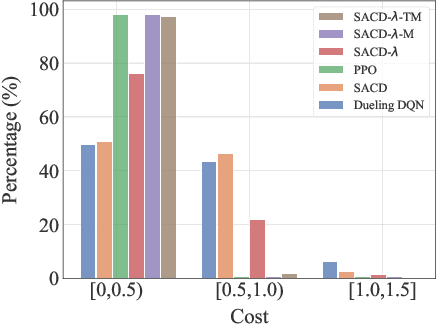
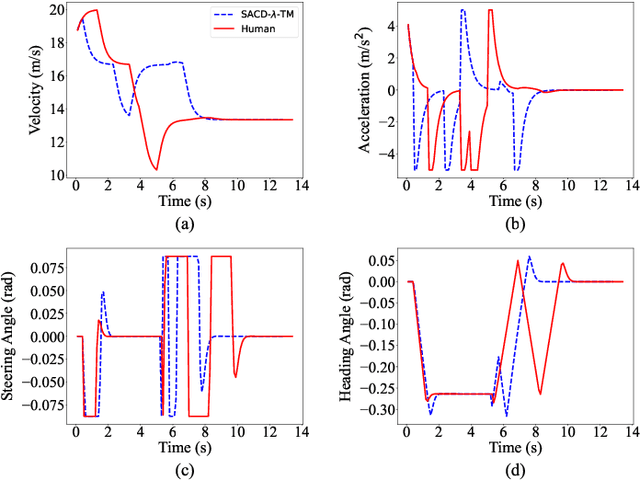
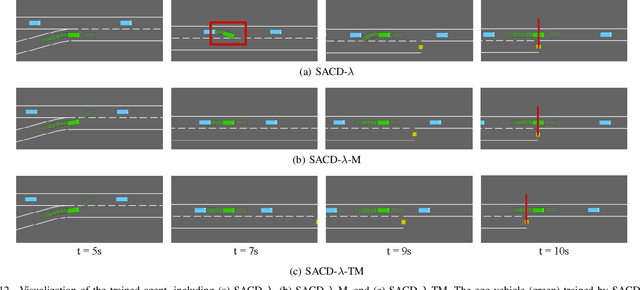
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.