 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOSTURE: Pose Guided Unsupervised Domain Adaptation for Human Body Part Segmentation
Jul 04, 2024



Existing algorithms for human body part segmentation have shown promising results on challenging datasets, primarily relying on end-to-end supervision. However, these algorithms exhibit severe performance drops in the face of domain shifts, leading to inaccurate segmentation masks. To tackle this issue, we introduce POSTURE: \underline{Po}se Guided Un\underline{s}upervised Domain Adap\underline{t}ation for H\underline{u}man Body Pa\underline{r}t S\underline{e}gmentation - an innovative pseudo-labelling approach designed to improve segmentation performance on the unlabeled target data. Distinct from conventional domain adaptive methods for general semantic segmentation, POSTURE stands out by considering the underlying structure of the human body and uses anatomical guidance from pose keypoints to drive the adaptation process. This strong inductive prior translates to impressive performance improvements, averaging 8\% over existing state-of-the-art domain adaptive semantic segmentation methods across three benchmark datasets. Furthermore, the inherent flexibility of our proposed approach facilitates seamless extension to source-free settings (SF-POSTURE), effectively mitigating potential privacy and computational concerns, with negligible drop in performance.
TEMP3D: Temporally Continuous 3D Human Pose Estimation Under Occlusions
Dec 24, 2023
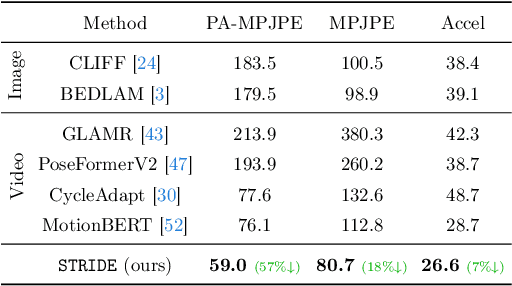
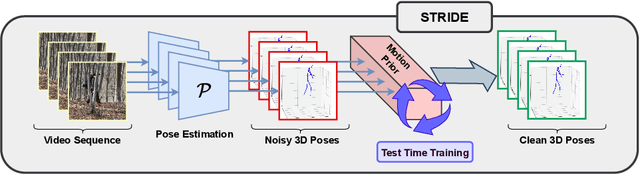

Existing 3D human pose estimation methods perform remarkably well in both monocular and multi-view settings. However, their efficacy diminishes significantly in the presence of heavy occlusions, which limits their practical utility. For video sequences, temporal continuity can help infer accurate poses, especially in heavily occluded frames. In this paper, we aim to leverage this potential of temporal continuity through human motion priors, coupled with large-scale pre-training on 3D poses and self-supervised learning, to enhance 3D pose estimation in a given video sequence. This leads to a temporally continuous 3D pose estimate on unlabelled in-the-wild videos, which may contain occlusions, while exclusively relying on pre-trained 3D pose models. We propose an unsupervised method named TEMP3D that aligns a motion prior model on a given in-the-wild video using existing SOTA single image-based 3D pose estimation methods to give temporally continuous output under occlusions. To evaluate our method, we test it on the Occluded Human3.6M dataset, our custom-built dataset which contains significantly large (up to 100%) human body occlusions incorporated into the Human3.6M dataset. We achieve SOTA results on Occluded Human3.6M and the OcMotion dataset while maintaining competitive performance on non-occluded data. URL: https://sites.google.com/ucr.edu/temp3d
Factorized Tensor Networks for Multi-Task and Multi-Domain Learning
Oct 09, 2023



Multi-task and multi-domain learning methods seek to learn multiple tasks/domains, jointly or one after another, using a single unified network. The key challenge and opportunity is to exploit shared information across tasks and domains to improve the efficiency of the unified network. The efficiency can be in terms of accuracy, storage cost, computation, or sample complexity. In this paper, we propose a factorized tensor network (FTN) that can achieve accuracy comparable to independent single-task/domain networks with a small number of additional parameters. FTN uses a frozen backbone network from a source model and incrementally adds task/domain-specific low-rank tensor factors to the shared frozen network. This approach can adapt to a large number of target domains and tasks without catastrophic forgetting. Furthermore, FTN requires a significantly smaller number of task-specific parameters compared to existing methods. We performed experiments on widely used multi-domain and multi-task datasets. We show the experiments on convolutional-based architecture with different backbones and on transformer-based architecture. We observed that FTN achieves similar accuracy as single-task/domain methods while using only a fraction of additional parameters per task.
eTOP: Early Termination of Pipelines for Faster Training of AutoML Systems
Apr 17, 2023



Recent advancements in software and hardware technologies have enabled the use of AI/ML models in everyday applications has significantly improved the quality of service rendered. However, for a given application, finding the right AI/ML model is a complex and costly process, that involves the generation, training, and evaluation of multiple interlinked steps (called pipelines), such as data pre-processing, feature engineering, selection, and model tuning. These pipelines are complex (in structure) and costly (both in compute resource and time) to execute end-to-end, with a hyper-parameter associated with each step. AutoML systems automate the search of these hyper-parameters but are slow, as they rely on optimizing the pipeline's end output. We propose the eTOP Framework which works on top of any AutoML system and decides whether or not to execute the pipeline to the end or terminate at an intermediate step. Experimental evaluation on 26 benchmark datasets and integration of eTOPwith MLBox4 reduces the training time of the AutoML system upto 40x than baseline MLBox.