 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMP3D: Temporally Continuous 3D Human Pose Estimation Under Occlusions
Paper and Code
Dec 24, 2023
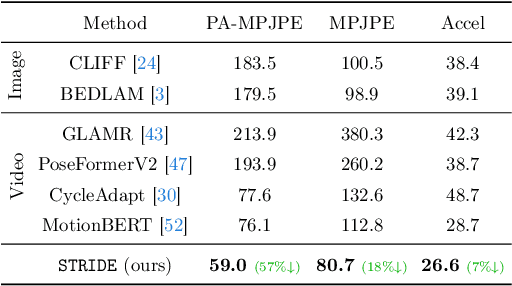
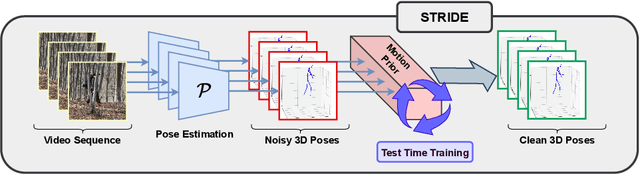

Existing 3D human pose estimation methods perform remarkably well in both monocular and multi-view settings. However, their efficacy diminishes significantly in the presence of heavy occlusions, which limits their practical utility. For video sequences, temporal continuity can help infer accurate poses, especially in heavily occluded frames. In this paper, we aim to leverage this potential of temporal continuity through human motion priors, coupled with large-scale pre-training on 3D poses and self-supervised learning, to enhance 3D pose estimation in a given video sequence. This leads to a temporally continuous 3D pose estimate on unlabelled in-the-wild videos, which may contain occlusions, while exclusively relying on pre-trained 3D pose models. We propose an unsupervised method named TEMP3D that aligns a motion prior model on a given in-the-wild video using existing SOTA single image-based 3D pose estimation methods to give temporally continuous output under occlusions. To evaluate our method, we test it on the Occluded Human3.6M dataset, our custom-built dataset which contains significantly large (up to 100%) human body occlusions incorporated into the Human3.6M dataset. We achieve SOTA results on Occluded Human3.6M and the OcMotion dataset while maintaining competitive performance on non-occluded data. URL: https://sites.google.com/ucr.edu/temp3d