 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Structured, State-Aware, and Execution-Grounded Reasoning for Software Engineering Agents
Feb 04, 2026Software Engineering (SE) agents have shown promising abilities in supporting various SE tasks. Current SE agents remain fundamentally reactive, making decisions mainly based on conversation history and the most recent response. However, this reactive design provides no explicit structure or persistent state within the agent's memory, making long-horizon reasoning challenging. As a result, SE agents struggle to maintain a coherent understanding across reasoning steps, adapt their hypotheses as new evidence emerges, or incorporate execution feedback into the mental reasoning model of the system state. In this position paper, we argue that, to further advance SE agents, we need to move beyond reactive behavior toward a structured, state-aware, and execution-grounded reasoning. We outline how explicit structure, persistent and evolving state, and the integration of execution-grounded feedback can help SE agents perform more coherent and reliable reasoning in long-horizon tasks. We also provide an initial roadmap for developing next-generation SE agents that can more effectively perform real-world tasks.
MAPLE: A Mobile Assistant with Persistent Finite State Machines for Recovery Reasoning
May 29, 2025Mobile GUI agents aim to autonomously complete user-instructed tasks across mobile apps. Recent advances in Multimodal Large Language Models (MLLMs) enable these agents to interpret UI screens, identify actionable elements, and perform interactions such as tapping or typing. However, existing agents remain reactive: they reason only over the current screen and lack a structured model of app navigation flow, limiting their ability to understand context, detect unexpected outcomes, and recover from errors. We present MAPLE, a state-aware multi-agent framework that abstracts app interactions as a Finite State Machine (FSM). We computationally model each UI screen as a discrete state and user actions as transitions, allowing the FSM to provide a structured representation of the app execution. MAPLE consists of specialized agents responsible for four phases of task execution: planning, execution, verification, error recovery, and knowledge retention. These agents collaborate to dynamically construct FSMs in real time based on perception data extracted from the UI screen, allowing the GUI agents to track navigation progress and flow, validate action outcomes through pre- and post-conditions of the states, and recover from errors by rolling back to previously stable states. Our evaluation results on two challenging cross-app benchmarks, Mobile-Eval-E and SPA-Bench, show that MAPLE outperforms the state-of-the-art baseline, improving task success rate by up to 12%, recovery success by 13.8%, and action accuracy by 6.5%. Our results highlight the importance of structured state modeling in guiding mobile GUI agents during task execution. Moreover, our FSM representation can be integrated into future GUI agent architectures as a lightweight, model-agnostic memory layer to support structured planning, execution verification, and error recovery.
ZS4C: Zero-Shot Synthesis of Compilable Code for Incomplete Code Snippets using ChatGPT
Jan 25, 2024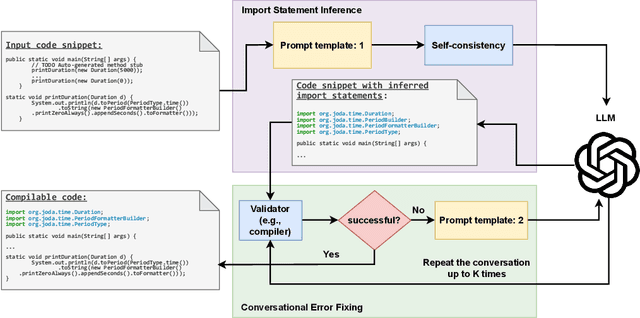


Technical question and answering (Q&A) sites such as Stack Overflow have become an important source for software developers to seek knowledge. However, code snippets on Q&A sites are usually uncompilable and semantically incomplete for compilation due to unresolved types and missing dependent libraries, which raises the obstacle for users to reuse or analyze Q&A code snippets. Prior approaches either are not designed for synthesizing compilable code or suffer from a low compilation success rate. To address this problem, we propose ZS4C, a lightweight approach to perform zero-shot synthesis of compilable code from incomplete code snippets using Large Language Model (LLM). ZS4C operates in two stages. In the first stage, ZS4C utilizes an LLM, i.e., ChatGPT, to identify missing import statements for a given code snippet, leveraging our designed task-specific prompt template. In the second stage, ZS4C fixes compilation errors caused by incorrect import statements and syntax errors through collaborative work between ChatGPT and a compiler. We thoroughly evaluated ZS4C on a widely used benchmark called StatType-SO against the SOTA approach SnR. Compared with SnR, ZS4C improves the compilation rate from 63% to 87.6%, with a 39.3% improvement. On average, ZS4C can infer more accurate import statements than SnR, with an improvement of 6.6% in the F1.
A First Look at Information Highlighting in Stack Overflow Answers
Jan 03, 2024



Context: Navigating the knowledge of Stack Overflow (SO) remains challenging. To make the posts vivid to users, SO allows users to write and edit posts with Markdown or HTML so that users can leverage various formatting styles (e.g., bold, italic, and code) to highlight the important information. Nonetheless, there have been limited studies on the highlighted information. Objective: We carried out the first large-scale exploratory study on the information highlighted in SO answers in our recent study. To extend our previous study, we develop approaches to automatically recommend highlighted content with formatting styles using neural network architectures initially designed for the Named Entity Recognition task. Method: In this paper, we studied 31,169,429 answers of Stack Overflow. For training recommendation models, we choose CNN and BERT models for each type of formatting (i.e., Bold, Italic, Code, and Heading) using the information highlighting dataset we collected from SO answers. Results: Our models based on CNN architecture achieve precision ranging from 0.71 to 0.82. The trained model for automatic code content highlighting achieves a recall of 0.73 and an F1 score of 0.71, outperforming the trained models for other formatting styles. The BERT models have even lower recalls and F1 scores than the CNN models. Our analysis of failure cases indicates that the majority of the failure cases are missing identification (i.e., the model misses the content that is supposed to be highlighted) due to the models tend to learn the frequently highlighted words while struggling to learn less frequent words. Conclusion: Our findings suggest that it is possible to develop recommendation models for highlighting information for answers with different formatting styles on Stack Overflow.