 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZS4C: Zero-Shot Synthesis of Compilable Code for Incomplete Code Snippets using ChatGPT
Jan 25, 2024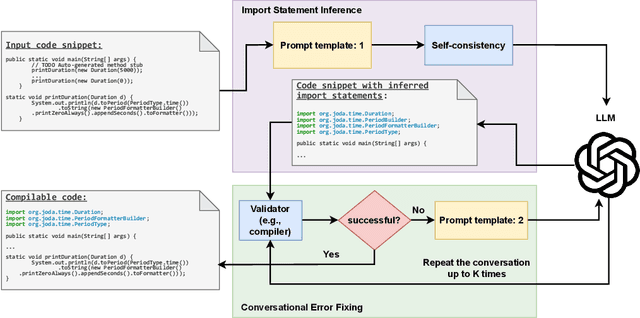
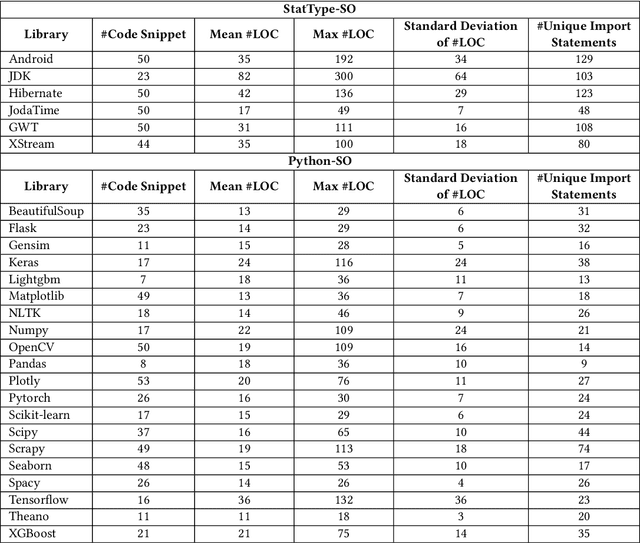


Technical question and answering (Q&A) sites such as Stack Overflow have become an important source for software developers to seek knowledge. However, code snippets on Q&A sites are usually uncompilable and semantically incomplete for compilation due to unresolved types and missing dependent libraries, which raises the obstacle for users to reuse or analyze Q&A code snippets. Prior approaches either are not designed for synthesizing compilable code or suffer from a low compilation success rate. To address this problem, we propose ZS4C, a lightweight approach to perform zero-shot synthesis of compilable code from incomplete code snippets using Large Language Model (LLM). ZS4C operates in two stages. In the first stage, ZS4C utilizes an LLM, i.e., ChatGPT, to identify missing import statements for a given code snippet, leveraging our designed task-specific prompt template. In the second stage, ZS4C fixes compilation errors caused by incorrect import statements and syntax errors through collaborative work between ChatGPT and a compiler. We thoroughly evaluated ZS4C on a widely used benchmark called StatType-SO against the SOTA approach SnR. Compared with SnR, ZS4C improves the compilation rate from 63% to 87.6%, with a 39.3% improvement. On average, ZS4C can infer more accurate import statements than SnR, with an improvement of 6.6% in the F1.
Fast Clustering of Short Text Streams Using Efficient Cluster Indexing and Dynamic Similarity Thresholds
Jan 21, 2021

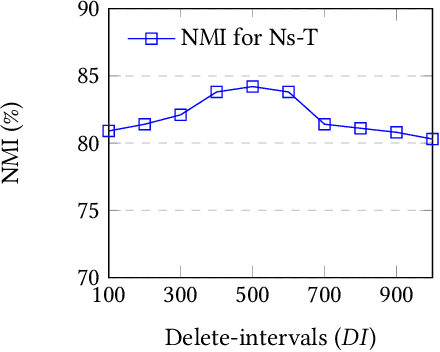
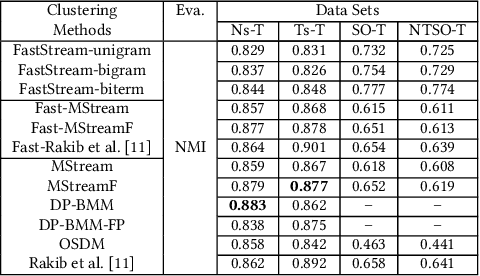
Short text stream clustering is an important but challenging task since massive amount of text is generated from different sources such as micro-blogging, question-answering, and social news aggregation websites. One of the major challenges of clustering such massive amount of text is to cluster them within a reasonable amount of time. The existing state-of-the-art short text stream clustering methods can not cluster such massive amount of text within a reasonable amount of time as they compute similarities between a text and all the existing clusters to assign that text to a cluster. To overcome this challenge, we propose a fast short text stream clustering method (called FastStream) that efficiently index the clusters using inverted index and compute similarity between a text and a selected number of clusters while assigning a text to a cluster. In this way, we not only reduce the running time of our proposed method but also reduce the running time of several state-of-the-art short text stream clustering methods. FastStream assigns a text to a cluster (new or existing) using the dynamically computed similarity thresholds based on statistical measure. Thus our method efficiently deals with the concept drift problem. Experimental results demonstrate that FastStream outperforms the state-of-the-art short text stream clustering methods by a significant margin on several short text datasets. In addition, the running time of FastStream is several orders of magnitude faster than that of the state-of-the-art methods.