 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Class-Incremental Learning via Entropy-Regularized Data-Free Replay
Paper and Code
Jul 22, 2022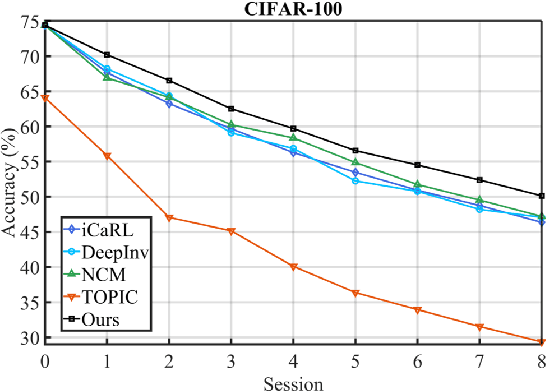
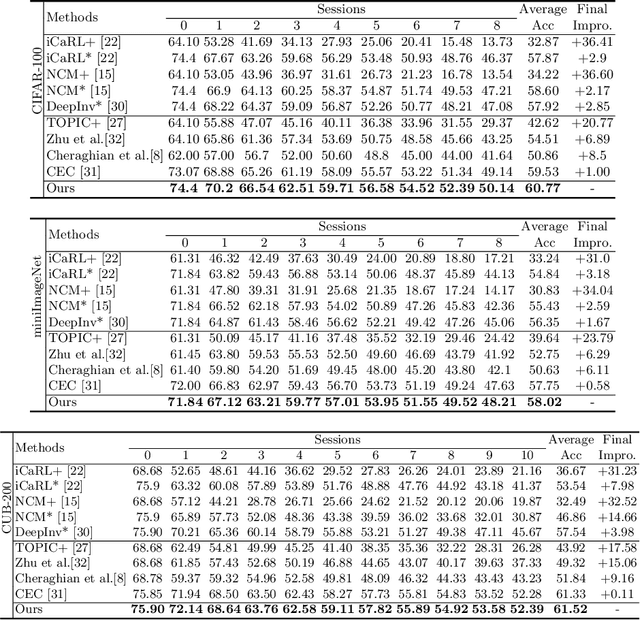

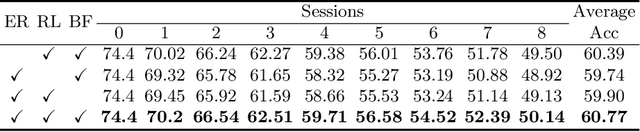
Few-shot class-incremental learning (FSCIL) has been proposed aiming to enable a deep learning system to incrementally learn new classes with limited data. Recently, a pioneer claims that the commonly used replay-based method in class-incremental learning (CIL) is ineffective and thus not preferred for FSCIL. This has, if truth, a significant influence on the fields of FSCIL. In this paper, we show through empirical results that adopting the data replay is surprisingly favorable. However, storing and replaying old data can lead to a privacy concern. To address this issue, we alternatively propose using data-free replay that can synthesize data by a generator without accessing real data. In observing the the effectiveness of uncertain data for knowledge distillation, we impose entropy regularization in the generator training to encourage more uncertain examples. Moreover, we propose to relabel the generated data with one-hot-like labels. This modification allows the network to learn by solely minimizing the cross-entropy loss, which mitigates the problem of balancing different objectives in the conventional knowledge distillation approach. Finally, we show extensive experimental results and analysis on CIFAR-100, miniImageNet and CUB-200 to demonstrate the effectiveness of our proposed one.