 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-domain Random Pre-training with Prototypes for Reinforcement Learning
Paper and Code
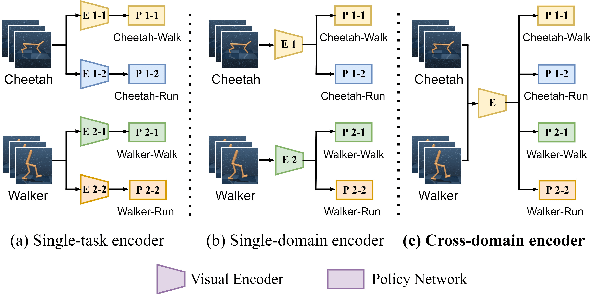

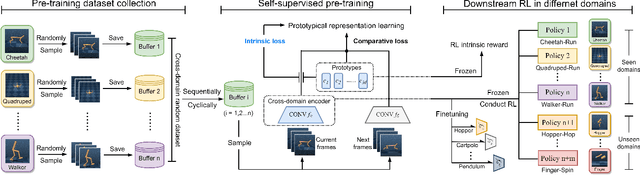

Task-agnostic cross-domain pre-training shows great potential in image-based Reinforcement Learning (RL) but poses a big challenge. In this paper, we propose CRPTpro, a Cross-domain self-supervised Random Pre-Training framework with prototypes for image-based RL. CRPTpro employs cross-domain random policy to easily and quickly sample diverse data from multiple domains, to improve pre-training efficiency. Moreover, prototypical representation learning with a novel intrinsic loss is proposed to pre-train an effective and generic encoder across different domains. Without finetuning, the cross-domain encoder can be implemented for challenging downstream visual-control RL tasks defined in different domains efficiently. Compared with prior arts like APT and Proto-RL, CRPTpro achieves better performance on cross-domain downstream RL tasks without extra training on exploration agents for expert data collection, greatly reducing the burden of pre-training. Experiments on DeepMind Control suite (DMControl) demonstrate that CRPTpro outperforms APT significantly on 11/12 cross-domain RL tasks with only 39% pre-training hours, becoming a state-of-the-art cross-domain pre-training method in both policy learning performance and pre-training efficiency. The complete code will be released at https://github.com/liuxin0824/CRPTpro.