 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask Hierarchical Features For Self-Supervised Learning
Paper and Code
Apr 01, 2023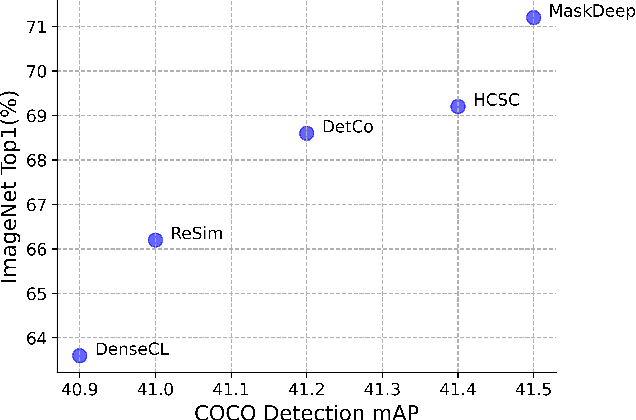
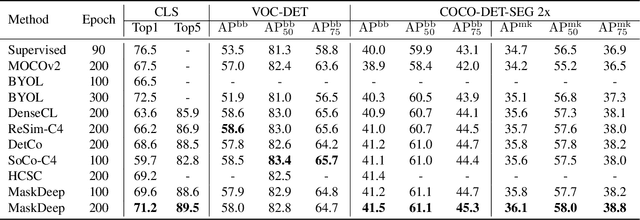
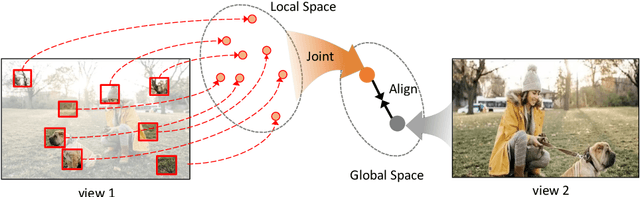
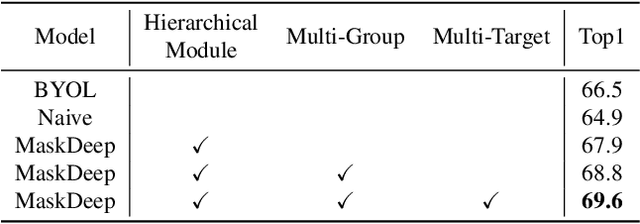
This paper shows that Masking the Deep hierarchical features is an efficient self-supervised method, denoted as MaskDeep. MaskDeep treats each patch in the representation space as an independent instance. We mask part of patches in the representation space and then utilize sparse visible patches to reconstruct high semantic image representation. The intuition of MaskDeep lies in the fact that models can reason from sparse visible patches semantic to the global semantic of the image. We further propose three designs in our framework: 1) a Hierarchical Deep-Masking module to concern the hierarchical property of patch representations, 2) a multi-group strategy to improve the efficiency without any extra computing consumption of the encoder and 3) a multi-target strategy to provide more description of the global semantic. Our MaskDeep brings decent improvements. Trained on ResNet50 with 200 epochs, MaskDeep achieves state-of-the-art results of 71.2% Top1 accuracy linear classification on ImageNet. On COCO object detection tasks, MaskDeep outperforms the self-supervised method SoCo, which specifically designed for object detection. When trained with 100 epochs, MaskDeep achieves 69.6% Top1 accuracy, which surpasses current methods trained with 200 epochs, such as HCSC, by 0.4% .