 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianAvatar-Editor: Photorealistic Animatable Gaussian Head Avatar Editor
Jan 17, 2025We introduce GaussianAvatar-Editor, an innovative framework for text-driven editing of animatable Gaussian head avatars that can be fully controlled in expression, pose, and viewpoint. Unlike static 3D Gaussian editing, editing animatable 4D Gaussian avatars presents challenges related to motion occlusion and spatial-temporal inconsistency. To address these issues, we propose the Weighted Alpha Blending Equation (WABE). This function enhances the blending weight of visible Gaussians while suppressing the influence on non-visible Gaussians, effectively handling motion occlusion during editing. Furthermore, to improve editing quality and ensure 4D consistency, we incorporate conditional adversarial learning into the editing process. This strategy helps to refine the edited results and maintain consistency throughout the animation. By integrating these methods, our GaussianAvatar-Editor achieves photorealistic and consistent results in animatable 4D Gaussian editing. We conduct comprehensive experiments across various subjects to validate the effectiveness of our proposed techniques, which demonstrates the superiority of our approach over existing methods. More results and code are available at: [Project Link](https://xiangyueliu.github.io/GaussianAvatar-Editor/).
GenN2N: Generative NeRF2NeRF Translation
Apr 03, 2024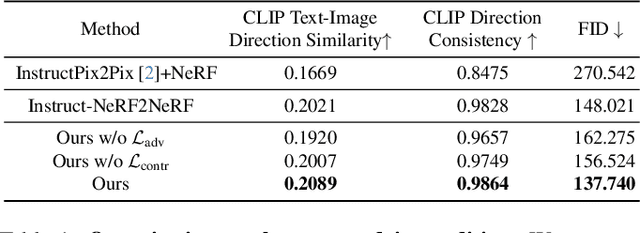
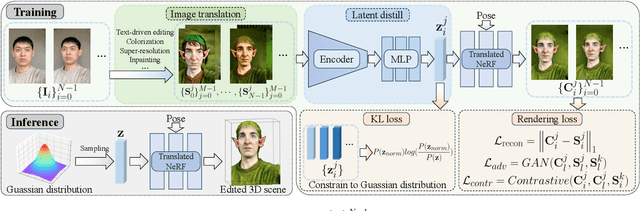
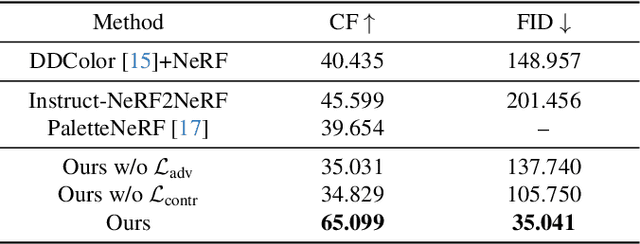

We present GenN2N, a unified NeRF-to-NeRF translation framework for various NeRF translation tasks such as text-driven NeRF editing, colorization, super-resolution, inpainting, etc. Unlike previous methods designed for individual translation tasks with task-specific schemes, GenN2N achieves all these NeRF editing tasks by employing a plug-and-play image-to-image translator to perform editing in the 2D domain and lifting 2D edits into the 3D NeRF space. Since the 3D consistency of 2D edits may not be assured, we propose to model the distribution of the underlying 3D edits through a generative model that can cover all possible edited NeRFs. To model the distribution of 3D edited NeRFs from 2D edited images, we carefully design a VAE-GAN that encodes images while decoding NeRFs. The latent space is trained to align with a Gaussian distribution and the NeRFs are supervised through an adversarial loss on its renderings. To ensure the latent code does not depend on 2D viewpoints but truly reflects the 3D edits, we also regularize the latent code through a contrastive learning scheme. Extensive experiments on various editing tasks show GenN2N, as a universal framework, performs as well or better than task-specific specialists while possessing flexible generative power. More results on our project page: https://xiangyueliu.github.io/GenN2N/
KD-MVS: Knowledge Distillation Based Self-supervised Learning for MVS
Jul 21, 2022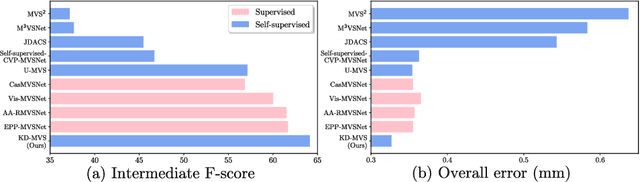
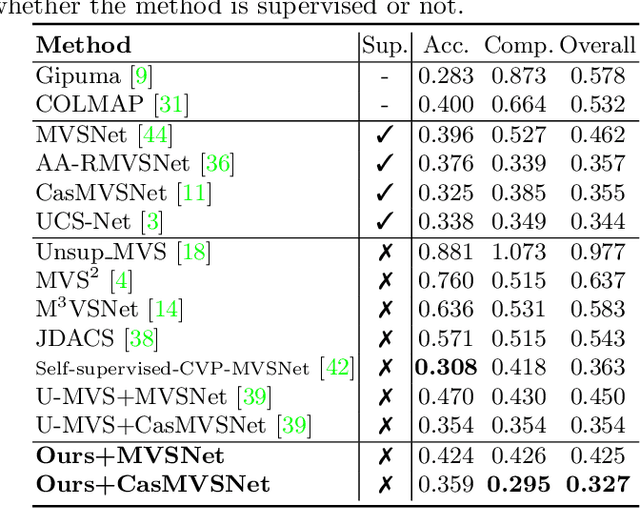
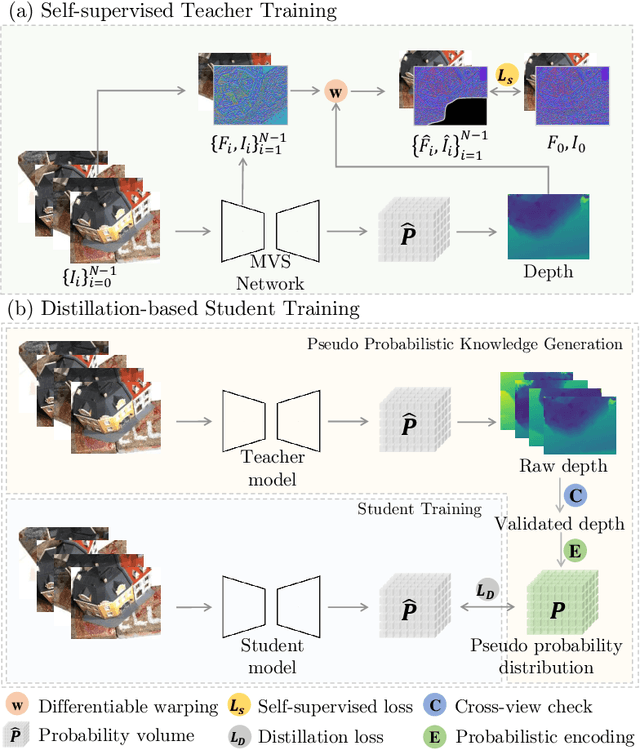
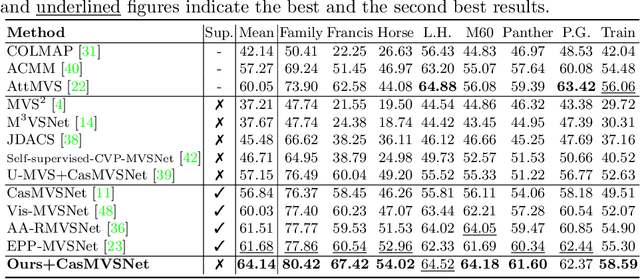
Supervised multi-view stereo (MVS) methods have achieved remarkable progress in terms of reconstruction quality, but suffer from the challenge of collecting large-scale ground-truth depth. In this paper, we propose a novel self-supervised training pipeline for MVS based on knowledge distillation, termed \textit{KD-MVS}, which mainly consists of self-supervised teacher training and distillation-based student training. Specifically, the teacher model is trained in a self-supervised fashion using both photometric and featuremetric consistency. Then we distill the knowledge of the teacher model to the student model through probabilistic knowledge transferring. With the supervision of validated knowledge, the student model is able to outperform its teacher by a large margin. Extensive experiments performed on multiple datasets show our method can even outperform supervised methods.
Sobolev Training for Implicit Neural Representations with Approximated Image Derivatives
Jul 21, 2022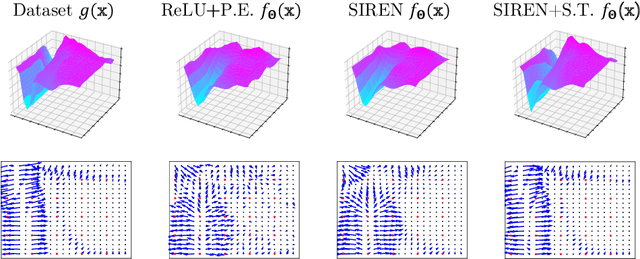
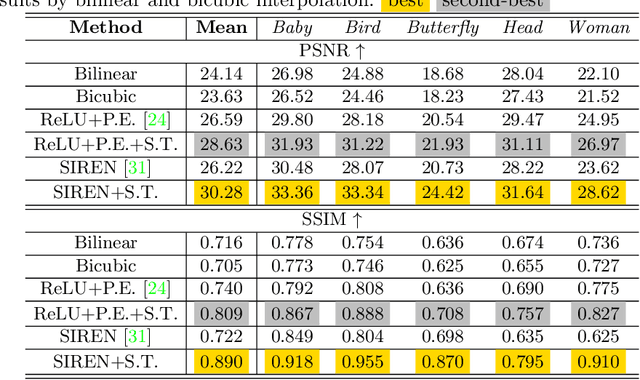


Recently, Implicit Neural Representations (INRs) parameterized by neural networks have emerged as a powerful and promising tool to represent different kinds of signals due to its continuous, differentiable properties, showing superiorities to classical discretized representations. However, the training of neural networks for INRs only utilizes input-output pairs, and the derivatives of the target output with respect to the input, which can be accessed in some cases, are usually ignored. In this paper, we propose a training paradigm for INRs whose target output is image pixels, to encode image derivatives in addition to image values in the neural network. Specifically, we use finite differences to approximate image derivatives. We show how the training paradigm can be leveraged to solve typical INRs problems, i.e., image regression and inverse rendering, and demonstrate this training paradigm can improve the data-efficiency and generalization capabilities of INRs. The code of our method is available at \url{https://github.com/megvii-research/Sobolev_INRs}.
TransMVSNet: Global Context-aware Multi-view Stereo Network with Transformers
Nov 29, 2021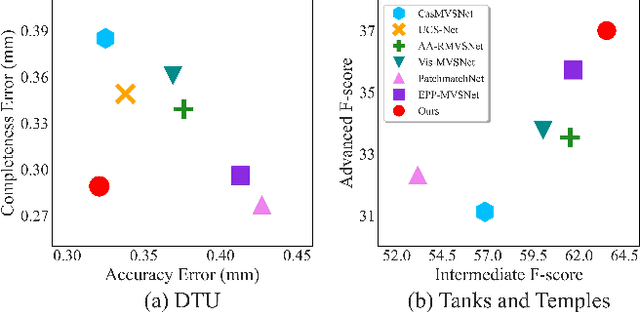
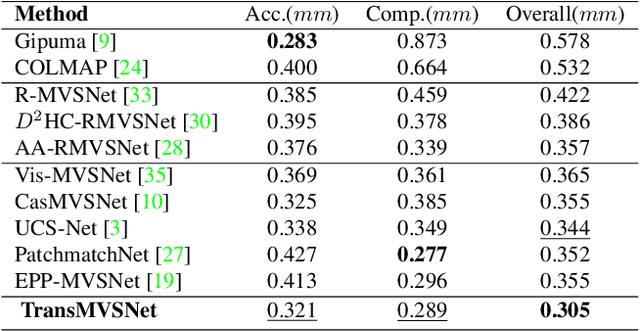
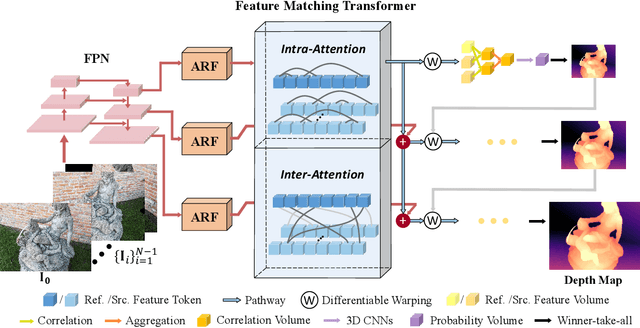
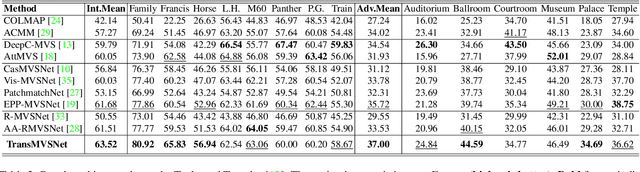
In this paper, we present TransMVSNet, based on our exploration of feature matching in multi-view stereo (MVS). We analogize MVS back to its nature of a feature matching task and therefore propose a powerful Feature Matching Transformer (FMT) to leverage intra- (self-) and inter- (cross-) attention to aggregate long-range context information within and across images. To facilitate a better adaptation of the FMT, we leverage an Adaptive Receptive Field (ARF) module to ensure a smooth transit in scopes of features and bridge different stages with a feature pathway to pass transformed features and gradients across different scales. In addition, we apply pair-wise feature correlation to measure similarity between features, and adopt ambiguity-reducing focal loss to strengthen the supervision. To the best of our knowledge, TransMVSNet is the first attempt to leverage Transformer into the task of MVS. As a result, our method achieves state-of-the-art performance on DTU dataset, Tanks and Temples benchmark, and BlendedMVS dataset. The code of our method will be made available at https://github.com/MegviiRobot/TransMVSNet .
2nd Place Solution to Instance Segmentation of IJCAI 3D AI Challenge 2020
Oct 21, 2020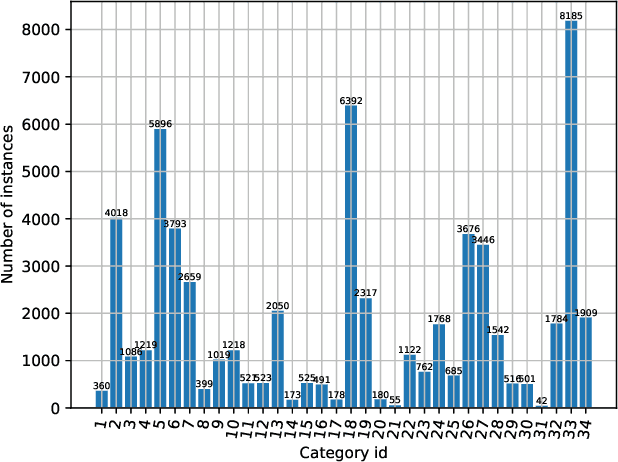


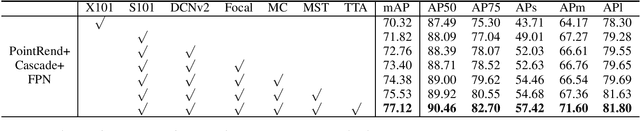
Compared with MS-COCO, the dataset for the competition has a larger proportion of large objects which area is greater than 96x96 pixels. As getting fine boundaries is vitally important for large object segmentation, Mask R-CNN with PointRend is selected as the base segmentation framework to output high-quality object boundaries. Besides, a better engine that integrates ResNeSt, FPN and DCNv2, and a range of effective tricks that including multi-scale training and test time augmentation are applied to improve segmentation performance. Our best performance is an ensemble of four models (three PointRend-based models and SOLOv2), which won the 2nd place in IJCAI-PRICAI 3D AI Challenge 2020: Instance Segmentation.