 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Contrastive Learning with Relation Knowledge Distillation
Dec 08, 2021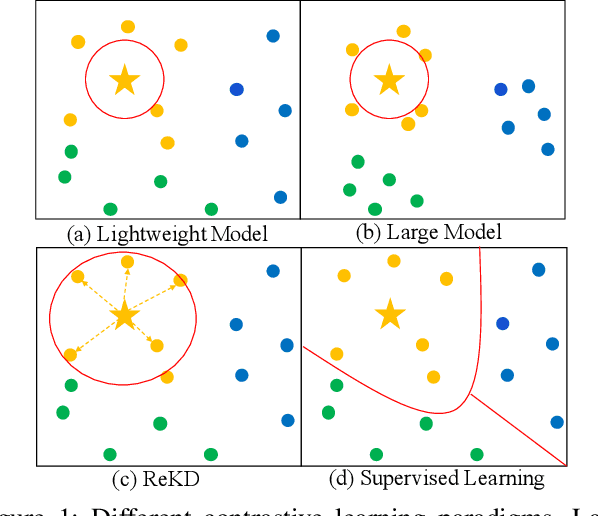
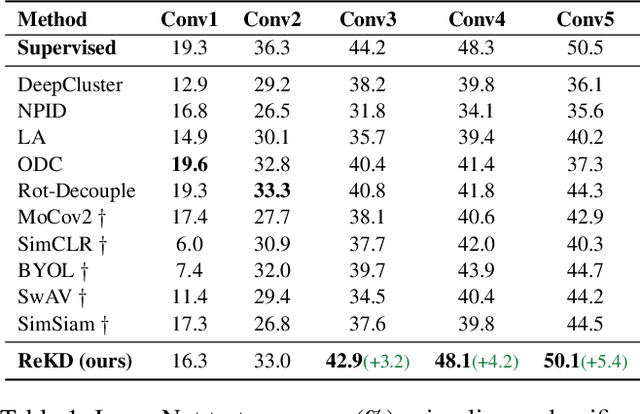
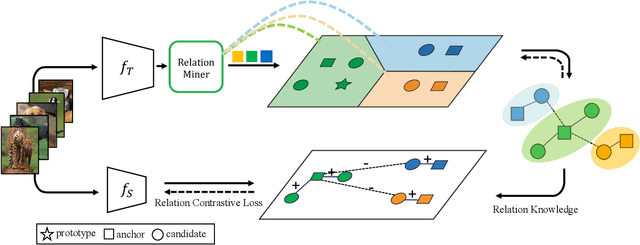
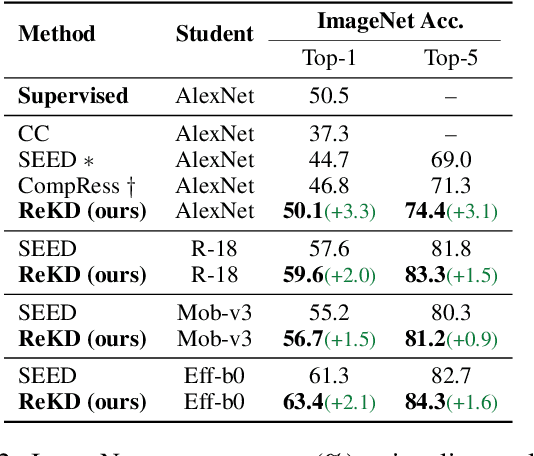
While self-supervised representation learning (SSL) has proved to be effective in the large model, there is still a huge gap between the SSL and supervised method in the lightweight model when following the same solution. We delve into this problem and find that the lightweight model is prone to collapse in semantic space when simply performing instance-wise contrast. To address this issue, we propose a relation-wise contrastive paradigm with Relation Knowledge Distillation (ReKD). We introduce a heterogeneous teacher to explicitly mine the semantic information and transferring a novel relation knowledge to the student (lightweight model). The theoretical analysis supports our main concern about instance-wise contrast and verify the effectiveness of our relation-wise contrastive learning. Extensive experimental results also demonstrate that our method achieves significant improvements on multiple lightweight models. Particularly, the linear evaluation on AlexNet obviously improves the current state-of-art from 44.7% to 50.1%, which is the first work to get close to the supervised 50.5%. Code will be made available.
TransMVSNet: Global Context-aware Multi-view Stereo Network with Transformers
Nov 29, 2021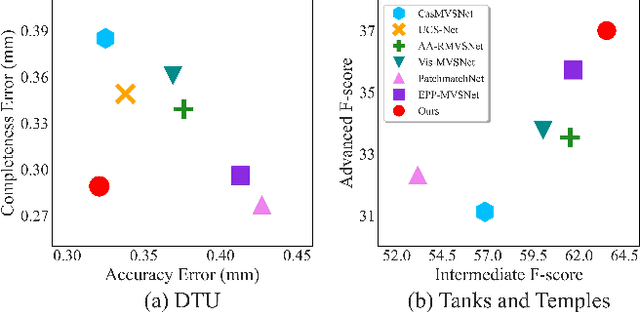
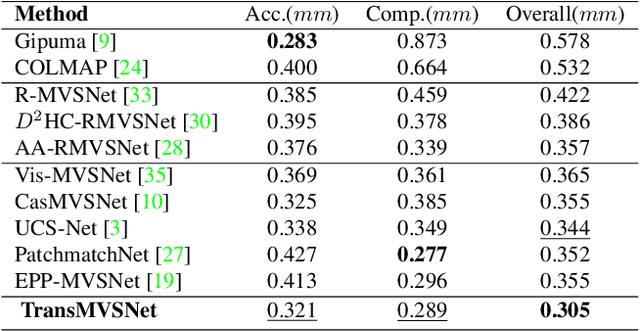
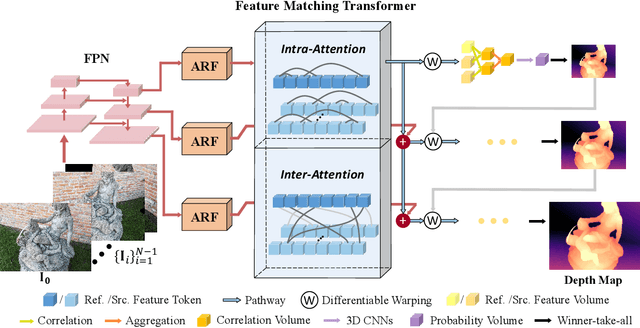
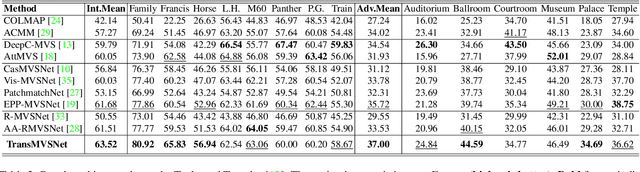
In this paper, we present TransMVSNet, based on our exploration of feature matching in multi-view stereo (MVS). We analogize MVS back to its nature of a feature matching task and therefore propose a powerful Feature Matching Transformer (FMT) to leverage intra- (self-) and inter- (cross-) attention to aggregate long-range context information within and across images. To facilitate a better adaptation of the FMT, we leverage an Adaptive Receptive Field (ARF) module to ensure a smooth transit in scopes of features and bridge different stages with a feature pathway to pass transformed features and gradients across different scales. In addition, we apply pair-wise feature correlation to measure similarity between features, and adopt ambiguity-reducing focal loss to strengthen the supervision. To the best of our knowledge, TransMVSNet is the first attempt to leverage Transformer into the task of MVS. As a result, our method achieves state-of-the-art performance on DTU dataset, Tanks and Temples benchmark, and BlendedMVS dataset. The code of our method will be made available at https://github.com/MegviiRobot/TransMVSNet .
Temporal Knowledge Consistency for Unsupervised Visual Representation Learning
Aug 24, 2021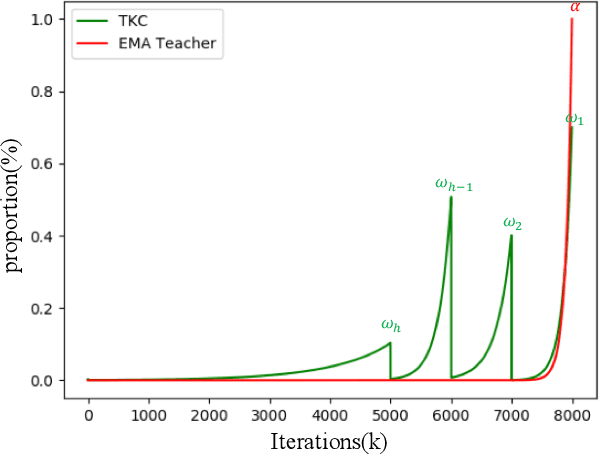
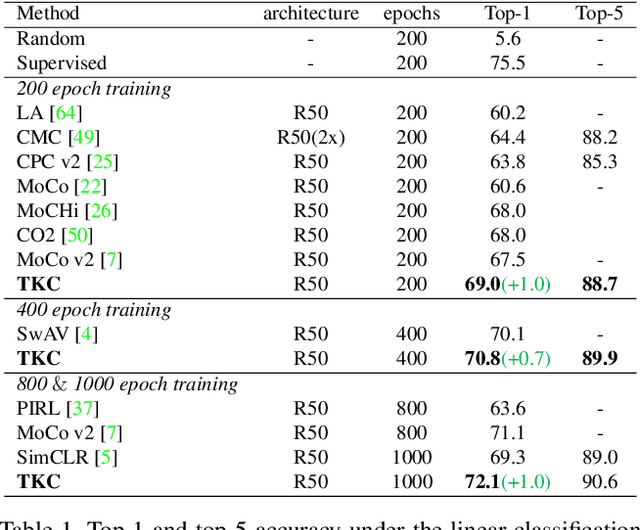
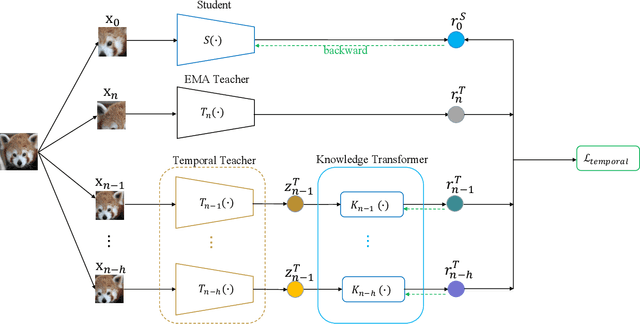

The instance discrimination paradigm has become dominant in unsupervised learning. It always adopts a teacher-student framework, in which the teacher provides embedded knowledge as a supervision signal for the student. The student learns meaningful representations by enforcing instance spatial consistency with the views from the teacher. However, the outputs of the teacher can vary dramatically on the same instance during different training stages, introducing unexpected noise and leading to catastrophic forgetting caused by inconsistent objectives. In this paper, we first integrate instance temporal consistency into current instance discrimination paradigms, and propose a novel and strong algorithm named Temporal Knowledge Consistency (TKC). Specifically, our TKC dynamically ensembles the knowledge of temporal teachers and adaptively selects useful information according to its importance to learning instance temporal consistency. Experimental result shows that TKC can learn better visual representations on both ResNet and AlexNet on linear evaluation protocol while transfer well to downstream tasks. All experiments suggest the good effectiveness and generalization of our method.
* To appear in ICCV 2021