 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeSinger 2: Fully Parallel Singing Voice Synthesis via Multi-Singer Conditional Adversarial Training
Paper and Code
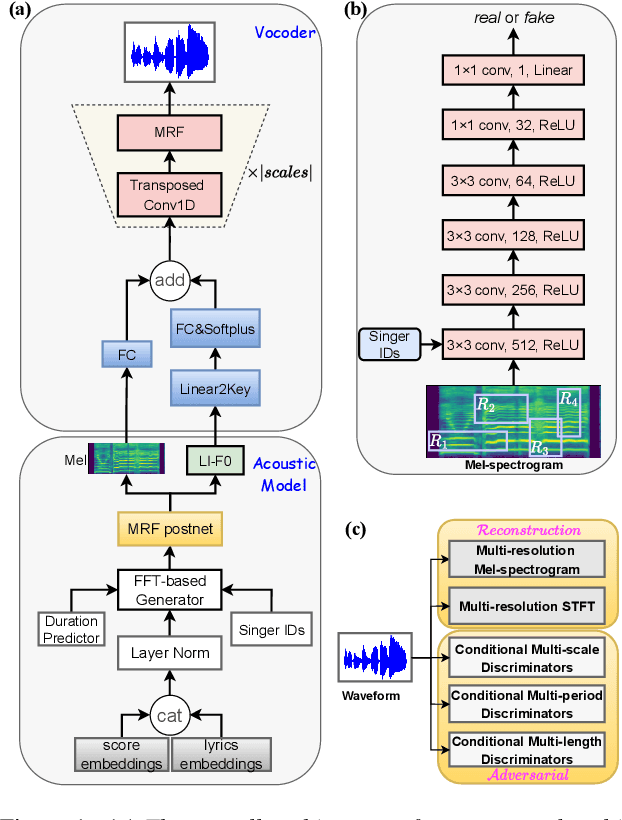
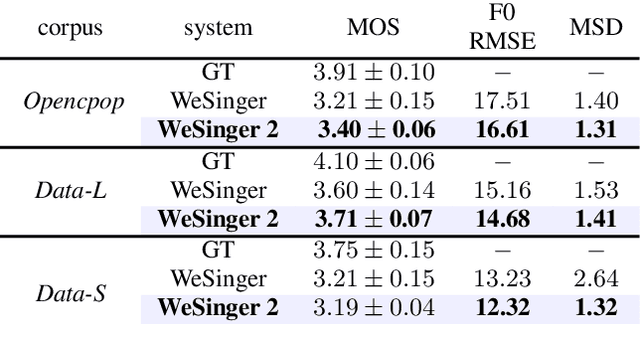


This paper aims to introduce a robust singing voice synthesis (SVS) system to produce high-quality singing voices efficiently by leveraging the adversarial training strategy. On one hand, we designed simple but generic random area conditional discriminators to help supervise the acoustic model, which can effectively avoid the over-smoothed spectrogram prediction by the duration-allocated Transformer-based acoustic model. On the other hand, we subtly combined the spectrogram with the frame-level linearly-interpolated F0 sequence as the input for the neural vocoder, which is then optimized with the help of multiple adversarial discriminators in the waveform domain and multi-scale distance functions in the frequency domain. The experimental results and ablation studies concluded that, compared with our previous auto-regressive work, our new system can produce high-quality singing voices efficiently by fine-tuning on different singing datasets covering from several minutes to few hours. Some synthesized singing samples are available online\footnote{https://zzw922cn.github.io/wesinger2}.