 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDobi-SVD: Differentiable SVD for LLM Compression and Some New Perspectives
Feb 04, 2025



We provide a new LLM-compression solution via SVD, unlocking new possibilities for LLM compression beyond quantization and pruning. We point out that the optimal use of SVD lies in truncating activations, rather than merely using activations as an optimization distance. Building on this principle, we address three critical challenges in SVD-based LLM compression: including (1) How can we determine the optimal activation truncation position for each weight matrix in LLMs? (2) How can we efficiently reconstruct the weight matrices based on truncated activations? (3) How can we address the inherent "injection" nature that results in the information loss of the SVD? We propose Dobi-SVD, which establishes a new, principled approach to SVD-based LLM compression.
Key-Grid: Unsupervised 3D Keypoints Detection using Grid Heatmap Features
Oct 03, 2024

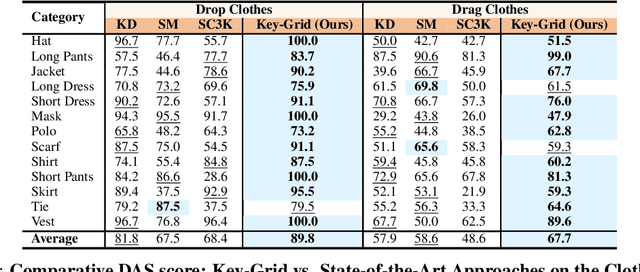
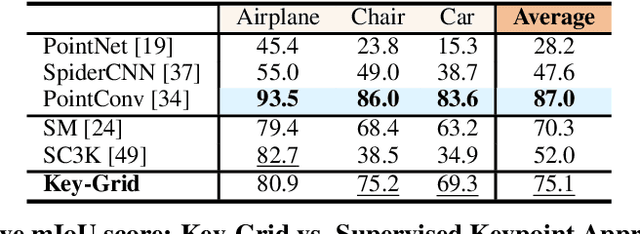
Detecting 3D keypoints with semantic consistency is widely used in many scenarios such as pose estimation, shape registration and robotics. Currently, most unsupervised 3D keypoint detection methods focus on the rigid-body objects. However, when faced with deformable objects, the keypoints they identify do not preserve semantic consistency well. In this paper, we introduce an innovative unsupervised keypoint detector Key-Grid for both the rigid-body and deformable objects, which is an autoencoder framework. The encoder predicts keypoints and the decoder utilizes the generated keypoints to reconstruct the objects. Unlike previous work, we leverage the identified keypoint in formation to form a 3D grid feature heatmap called grid heatmap, which is used in the decoder section. Grid heatmap is a novel concept that represents the latent variables for grid points sampled uniformly in the 3D cubic space, where these variables are the shortest distance between the grid points and the skeleton connected by keypoint pairs. Meanwhile, we incorporate the information from each layer of the encoder into the decoder section. We conduct an extensive evaluation of Key-Grid on a list of benchmark datasets. Key-Grid achieves the state-of-the-art performance on the semantic consistency and position accuracy of keypoints. Moreover, we demonstrate the robustness of Key-Grid to noise and downsampling. In addition, we achieve SE-(3) invariance of keypoints though generalizing Key-Grid to a SE(3)-invariant backbone.